
作者 | 管錫鵬
BentoML 是一個開源的大語言模型(LLM) AI 應用的開發框架和部署工具,致力于為開發者提供最簡單的構建大語言模型 AI 應用的能力,其開源產品已經支持全球數千家企業和組織的核心 AI 應用。
當 BentoML 在 Serverless 環境中部署模型時,其中一個主要挑戰是冷啟動慢,尤其在部署大型語言模型時更為明顯。由于這些模型體積龐大,啟動和初始化過程耗時很長。此外,由于 Image Registry 的帶寬較小,會讓大體積的 Container Image 進一步加劇冷啟動緩慢的問題。為了解決這一問題,BentoML 引入了 JuiceFS。
JuiceFS 的 POSIX 兼容性和數據分塊使我們能夠按需讀取數據,讀取性能接近 S3 能提供的性能 的上限,有效解決了大型模型在 Serverless 環境中冷啟動緩慢的問題。使用 JuiceFS 后,模型加載速度由原來的 20 多分鐘縮短至幾分鐘。在實施 JuiceFS 的過程中,我們發現實際模型文件的讀取速度與預期基準測試速度存在差異。通過一系列優化措施,如改進數據緩存策略和優化讀取算法,我們成功解決了這些挑戰。在本文中,我們將詳細介紹我們面臨的挑戰、解決方案及相關優化。
1BentoML 簡介以及 Bento 的架構
在介紹模型部署環節的工作之前,首先需要對 BentoML 是什么以及它的架構做一個簡要的介紹。
BentoML 是一個高度集成的開發框架,采用簡單易用的方式,支持以開發單體應用的方式進行開發,同時以分布式應用的形式進行部署。這意味著開發者可以用很低的學習成本來快速開發一個高效利用硬件資源的大語言模型 AI 應用。BentoML 還支持多種框架訓練出來的模型,包括 PyTorch、TensorFlow 等常用 ML 框架。起初,BentoML 主要服務于傳統 AI 模型,但隨著大型語言模型的興起,如 GPT 的應用,BentoML 也能夠服務于大語言模型。
BentoML 產生的制品稱為 Bento,Bento 的角色類似于 Container Image,是用于 AI 應用部署的最基本單位,一個 Bento 可以輕松部署在不同的環境中,比如 Docker、EC2、AWS Lambda、AWS SageMaker、Kafka、Spark、Kube.NETes。
一個 Bento 包含了業務代碼、模型文件、靜態文件,同時我們抽象出來了 API Server 和 Runner 的概念,API Server 是流量的入口,主要承載一些 I/O 密集型的任務,Runner 通常是執行模型的推理工作,主要承載一些 GPU/CPU 密集型的任務,從而可以將一個 AI 應用中不同硬件資源需求的任務進行輕松解耦。
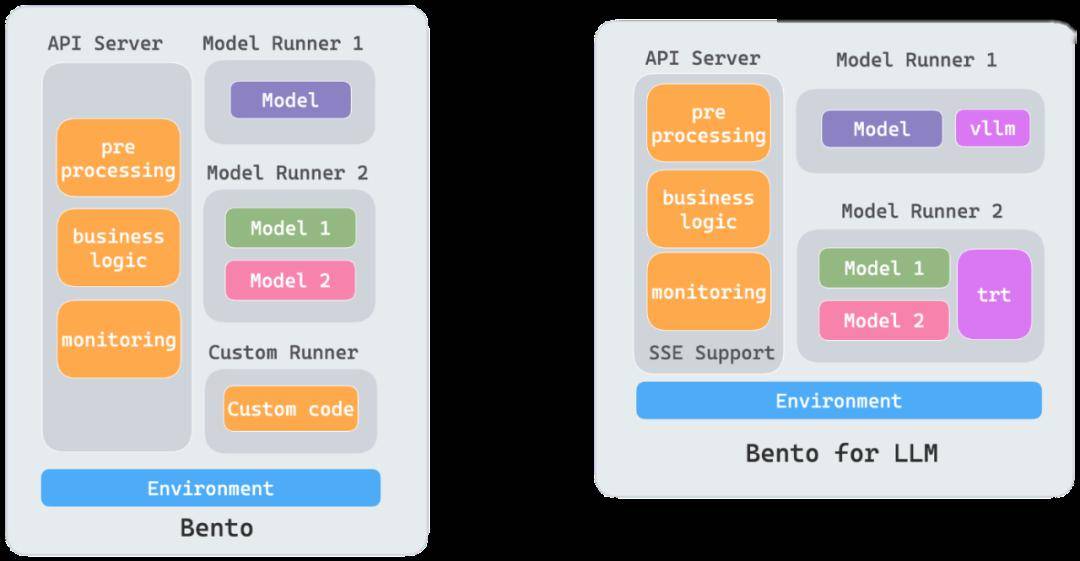
Bento Architecture
Bento ArchitectureBentoCloud 是一個使 Bento 可以部署在云上的平臺,一般開發任務分為三個階段:

BentoCloud Architecture
- 第一階段:開發階段
當項目使用 BentoML 進行 AI App 開發時,產生制品 Bento。此階段 BentoCloud 的角色是 Bento Registry。
- 第二階段:集成階段
若要將 Bento 部署到云環境中,需要一個 OCI 鏡像(Container Image)。在這個階段,我們有一個組件稱為 yatai-image-builder,負責將 Bento 構建成 OCI 鏡像,以便后續應用。
- 第三階段:部署階段,也是本文的重點內容
這其中一個關鍵組件是 yatai-serverless。在這個階段,yatai-serverless 負責將上一階段構建的 OCI 鏡像部署到云上。
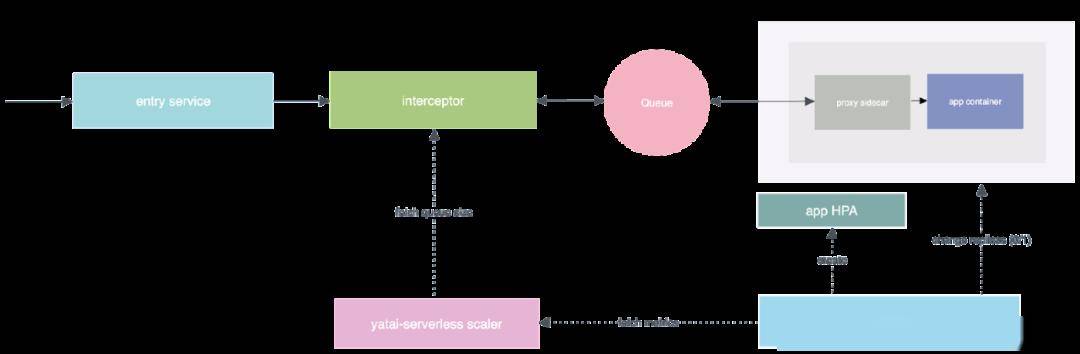
yatai-serverless Architecture
2Serverless 平臺部署大模型的挑戰
- 挑戰 1:冷啟動慢
對于 Serverless 平臺而言,冷啟動時間至關重要。想象一下,當請求到達時,從零開始增加副本,這可能需要超過 5 分鐘。在這段時間內,前面的某些 HTTP 基礎設施可能認為已經超時,對用戶體驗不利。特別是對于大語言模型,其模型文件通常很大,可能達到十幾到二十幾 GB 的規模,導致在啟動時拉取和下載模型的階段非常耗時,從而顯著延長冷啟動時間。
- 挑戰 2:數據一致性問題
這是 Serverless 平臺中特有的問題。我們的平臺通過對 Bento 的一些建模解決了這些問題。
- 挑戰 3:數據安全性問題
這是將 Bento 部署到云上的主要原因之一,也是 BentoML 提供給用戶的核心價值之一。眾所周知,OpenAI 以及國內的一些大語言模型會提供一些 HTTP API 供用戶使用,但由于許多企業或應用場景對數據安全性有極高的要求,因此他們不可能將敏感數據傳遞給第三方平臺的 API 進行處理。他們希望將大型語言模型部署到自己的云平臺上,以確保數據的安全性。
3為什么使用 JuiceFS ?
接下來將詳細探模型部署這一關鍵階段的具體工作。下圖展示了我們最初采用的架構,即將所有模型文件,包括 Python/ target=_blank class=infotextkey>Python 代碼、Python 依賴和擴展,都打包成一個 Container Image,然后在 Kubernetes 上運行。然而,這一流程面臨著以下挑戰:
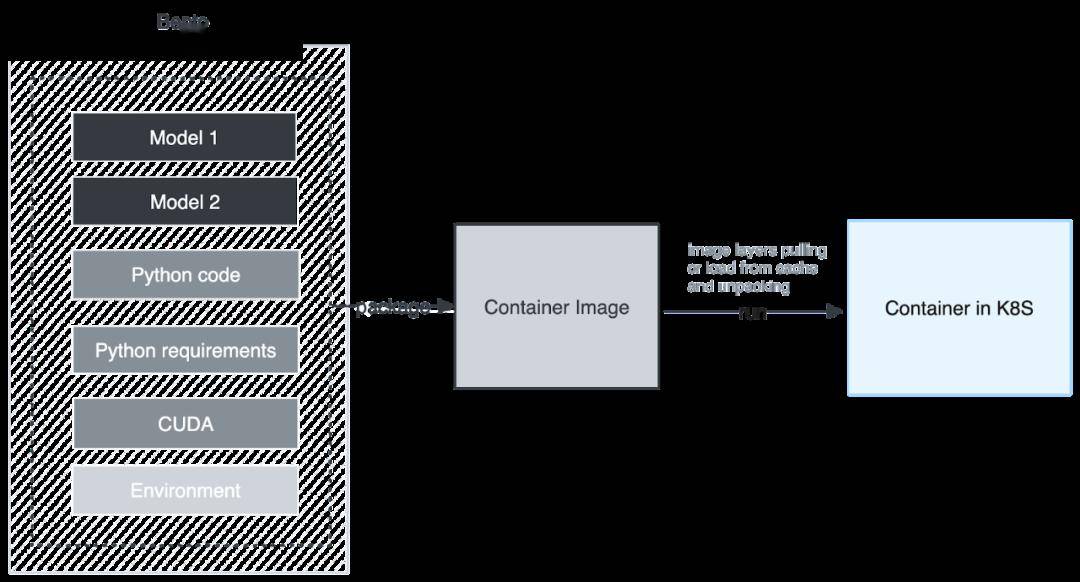
(BentoML:最初模型部署流程圖)
- 首先,一個 Container Image 由一系列 Layer 組成,因此 Container Image 最小的下載和緩存單位是 Layer,雖然在下載 Container Image 時,Container Image 的 Layer 是并行下載的,但 Layer 在解壓的時候是串行的。當解壓到模型所在的 Layer 時速度會減慢,同時占用大量的 CPU 時間。
- 另一個挑戰是當不同的 Bento 使用相同的模型時。這種架構會浪費多份相同的空間,并且被打包到不同的 Image 中,作為不同 Layer 存在,導致了多次下載和解壓,這是極大的資源浪費。因此,這種架構無法共享模型。
在解決這個問題時,我們首選了 JuiceFS,主要因為它具有以下三個優勢。
- 首先,它采用 POSIX 協議,無需再加一層抽象就使我們能夠以連貫的方式讀取數據。
- 其次,它可以達到很高的吞吐,可以接近整個 S3 或 GCS 的帶寬。
- 第三,它能夠實現良好的共享模型。當我們將模型存儲在 JuiceFS 中時,不同實例可以共享同一個大型語言模型。
下圖是我們集成 JuiceFS 后的架構。在構建 Container Image 時,我們將模型單獨提取并存儲到 JuiceFS 中。Container Image 中僅包含用戶的 Python 業務代碼和 Python 運行所需的依賴和基礎環境,這樣的設計帶來的好處是可以同時下載模型和運行,無需在本地解壓模型。整體解壓過程變得非常迅速,下載的數據量也大大減少,從而顯著提升了下載性能。
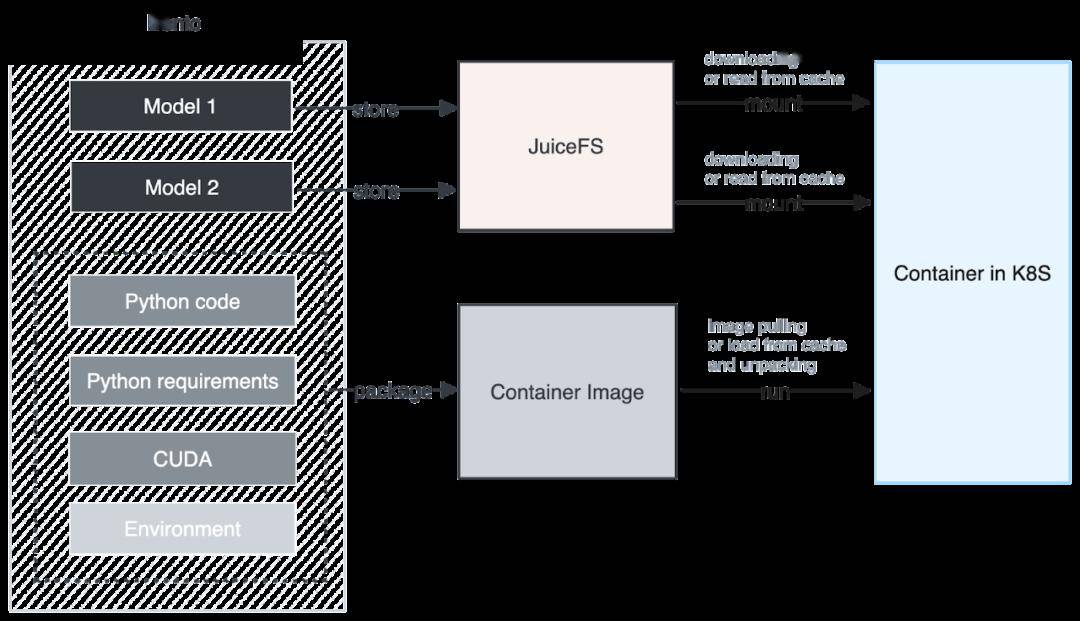
(BentoML:使用 JuiceFS 后的模型部署流程圖)
此外,我們進一步優化了下載和緩存的顆粒度,不僅每個模型都有自己的緩存顆粒度,而且 JuiceFS 對大文件分割成了一系列 chunk,以 chunk 為單位進行下載和緩存,利用這個特性可以實現類似于大模型的 Stream Loading 的效果。
我們還充分利用了 GKE 的 Image Streaming 技術。通過 Model Streaming 和 Image Streaming 同時進行數據拉取,我們成功降低了啟動時間,提升了整體性能。
4集成 JuiceFS 時遇到的挑戰
- 挑戰 1:無縫集成
在引入 JuiceFS 這一新組件時,必須處理如何與已有組件實現無縫集成的問題。這種情況是在任何較為成熟的平臺引入新組件時都會遇到的普遍挑戰。為了更好地繼承 JuiceFS, 我們采用了 AWS MemoryDB,以代替自己運維的 redis,從而降低架構的復雜度。
- 挑戰 2: 引入新組件對業務邏輯的影響
引入 JuiceFS 可能導致業務邏輯的變化。之前,Bento 的容器鏡像包含了完整的模型,而現在的 Bento 容器鏡像則不再攜帶模型。在 yatai-serverless 平臺的部署中,我們必須在代碼層面確保這兩種不同的鏡像在業務邏輯上實現相互兼容。為此,我們使用不同的 label 來區分不同版本的 bento,然后在代碼邏輯里做向前兼容。
- 挑戰 3: JuiceFS 下載速度問題
在測試 JuiceFS 時發現,使用 JuiceFS 下載模型的速度非常慢,甚至比直接從鏡像中下載還要慢。通過 JuiceFS 團隊的協助,我們發現我們的 Boot Disk 是網絡磁盤,所以我們一直使用網絡磁盤作為 JuiceFS 的緩存盤,這就會導致一個奇怪的現象:不命中緩存時速度更快,一旦命中緩存就變慢。為了解決這個問題,我們為我們的 GKE 環境都添加了 Local NVME SSD,并將 Local NVMe SSD 作為 JuiceFS 的緩存盤,從而完美地解決了這一問題。
5展望
在未來,我們將深入進行更多的可觀測性工作,以確保整個架構保持良好的運行狀態,并獲得足夠的指標以便更好地優化配置,盡量避免再次出現類似的問題。
希望可以高效利用 JuiceFS 自帶的緩存能力。例如,將模型提前種植到 JuiceFS 后,這意味著在業務集群中,可以提前在節點中預熱模型的緩存,從而進一步提升緩存和冷啟動時間的性能。





