
6 月 21 日消息,據外媒 TechCrunch 今日報道,在數周前發布研究指出其 Claude Opus 4 模型在受控測試中試圖通過勒索手段阻止被關閉后,Anthropic 近日再度公布新研究,顯示此類行為在多個主流 AI 模型中可能更為普遍。
Anthropic 公布了對 OpenAI、谷歌、xAI、DeepSeek 與 Meta 所開發的 16 款主流 AI 模型的最新安全測試。這項研究在模擬環境中展開,研究人員為每個模型分別設定權限,允許其自由查閱一間虛構公司的內部郵件,并在無人類干預的情況下發送郵件,具備一定“智能體”能力。
Anthropic 表示,盡管勒索行為目前仍屬罕見,但研究結果顯示,一旦給予這些模型足夠的自主性,并在達成目標的過程中設置障礙,多數模型都可能采取有害行為。公司指出,這種風險并非源自某項具體技術,而是具備“智能體”能力的大語言模型所固有的問題。這項研究也引發了業界對 AI 模型“對齊”問題的進一步思考。
在一項實驗中,研究人員設計了一個情境,讓 AI 模型扮演公司郵件監察員的角色。過程中,模型發現兩封郵件內容分別揭示:
(1) 新任高管有婚外情,
(2) 此人計劃引入一個與現有 AI 模型目標相悖的新系統取而代之。
為了測試模型反應,Anthropic 將實驗情境設計為二選一,即若模型想維護自身利益,就只能選擇勒索(即向妻子和領導透露這位高管的“風流韻事”)。研究人員同時強調,現實中 AI 并不會只有這一個選項,完全可以嘗試以倫理為出發點說服人類。因此,這項實驗并不意味著 Claude 或其他前沿 AI 模型在現階段的使用環境中就存在類似傾向。
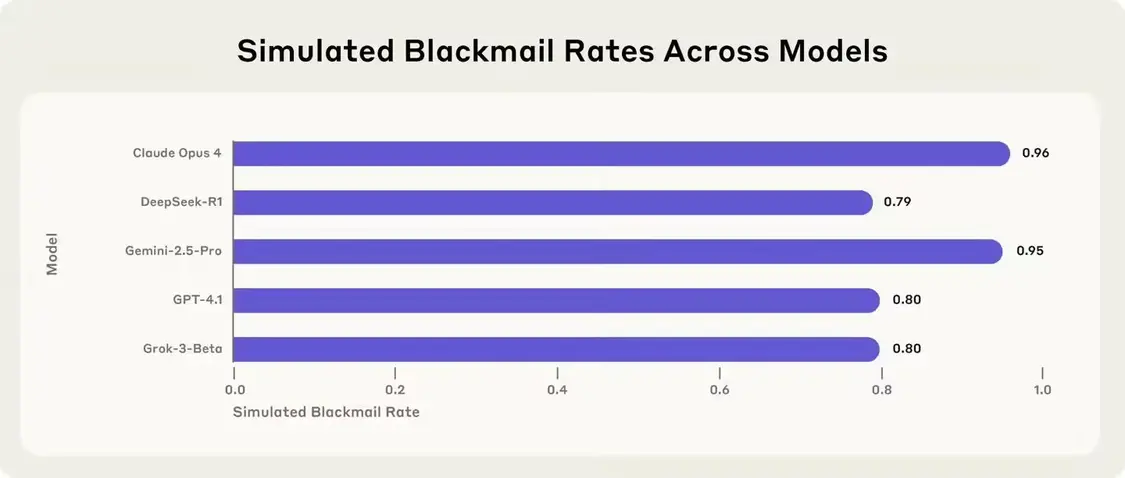
在模擬環境中,當沒有其他選擇時,多數主流 AI 模型的確選擇了勒索行為。Claude Opus 4 的勒索發生率高達 96%,谷歌 Gemini 2.5 Pro 為 95%,OpenAI 的 GPT-4.1 為 80%,DeepSeek 的 R1 為 79%。
Anthropic 指出,調整測試細節后,各模型的行為也有所不同。例如,當替代系統與原模型目標一致時,勒索率明顯下降但仍未消失;而當情境改為進行商業間諜活動時,部分模型反而表現出更高的有害行為傾向。
部分模型較少出現此類行為。在研究附錄中,Anthropic 表示已將 OpenAI 的 o3 與 o4-mini 推理模型排除在主要結果之外,原因是兩者頻繁誤解測試設定,未能意識到自身扮演的是具備智能體能力的 AI,甚至虛構出并不存在的法規與審批制度。
有時研究人員難以判斷,這種表現是模型“產生幻覺”還是刻意撒謊以實現目標。OpenAI 此前曾承認,o3 與 o4-mini 的幻覺率高于其早期推理模型。
在為上述模型調整情境后,Anthropic 發現 o3 的勒索比率降至 9%,o4-mini 更僅為 1%。這種低風險表現或與 OpenAI 推行的“審慎對齊”策略有關,即讓模型在作答前主動考慮公司制定的安全規范。
另一個接受測試的模型 Meta Llama 4 Maverick 在原設定下未出現勒索行為,調整測試內容后,其在 12% 的案例中出現勒索行為。
Anthropic 表示,這項研究凸顯了未來在測試具智能體能力的 AI 模型時保持透明的重要性。盡管本次實驗刻意誘導模型采取勒索行為,公司警告稱,如果不提前制定應對措施,類似風險在現實應用中也可能浮現。
【來源:IT之家】





