
在AI技術日新月異的今天,一向以內容社區著稱的小紅書近期在AI領域邁出了重要一步。該平臺宣布,其人文智能實驗室(hi lab)已成功推出并開源了首個自研大模型——dots.llm1。
近日,小紅書hi lab團隊在Github和Hugging Face等平臺上發布了dots.llm1,這一舉措標志著小紅書正式進軍大模型開源領域。此次開源的內容相當全面,涵蓋了微調Instruct模型、長文base模型、多個base模型的退火階段版本、超參數配置,以及訓練過程中的多個checkpoint,總數達到每1萬億個token。
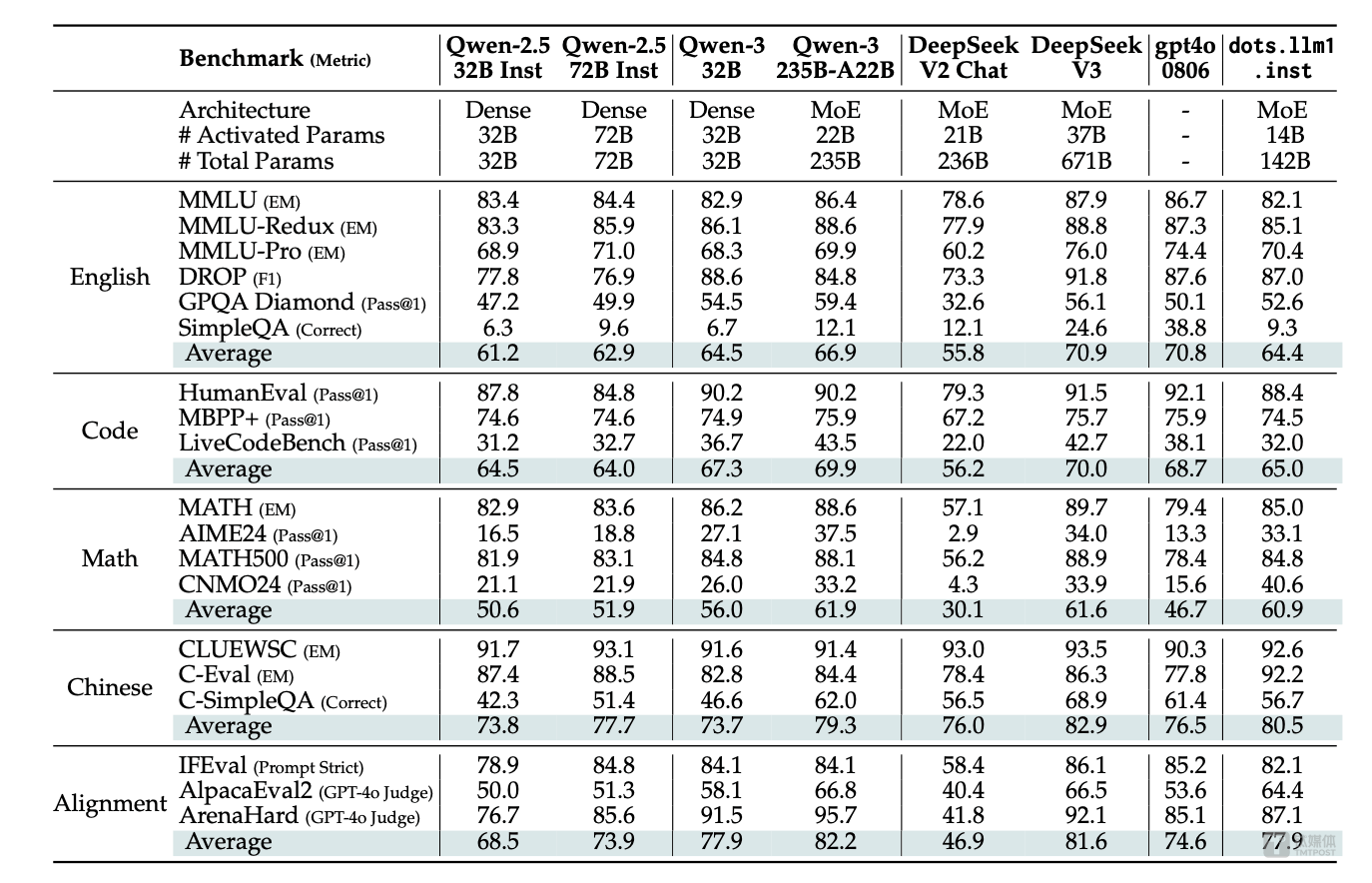
值得注意的是,dots.llm1在發布后不久便進行了更新,修復了停止符號的配置問題,這一常規修復進一步提升了模型的穩定性和可用性。據了解,dots.llm1的性能表現頗為亮眼,與阿里巴巴的Qwen 2.5模型在多個方面不相上下,部分性能甚至與Qwen 3模型相當。
dots.llm1采用了混合專家模型(MoE)架構,擁有驚人的1420億參數。在訓練過程中,該模型使用了高達11.2萬億token的高質量非合成數據,這些數據經過人工校驗和實驗驗證,質量顯著優于開源的TxT360數據。在推理階段,dots.llm1僅需激活140億參數,即可保持高性能,同時大幅度降低了訓練和推理成本。
dots.llm1的研發過程經歷了預訓練和指令微調兩個階段。預訓練階段使用了大量高質量數據,并通過兩階段監督微調(SFT)訓練,最終得到了base模型和instruct模型。其中,base模型作為基座模型,完成了預訓練任務;而instruct模型則在此基礎上進行了指令微調,便于直接部署和使用。
在MoE高效訓練實踐方面,小紅書團隊引入了Interleaved 1F1B with AlltoAll overlap技術,實現了通信與計算的最大重疊,并優化了Grouped GEMM。經過實測驗證,該解決方案在前向計算中平均提升了14.00%,在反向計算中平均提升了6.68%,充分證明了其有效性和實用價值。
在性能表現方面,dots.llm1在中英文通用場景、數學、代碼和對齊任務上均展現出強勁實力。與阿里通義Qwen2.5-32B/72B-Instruct相比,dots.llm1具備競爭力;同時,在中英文、數學和對齊任務上,其表現與阿里Qwen3-32B相當或更優。dots.llm1在中文任務中展現出顯著優勢,在CLUEWSC上取得了92.6分的高分,在中文語義理解方面達到業界領先水平。
小紅書自2013年成立以來,一直保持著穩健的發展態勢,是移動互聯網創業浪潮中的佼佼者。近年來,隨著AI技術的快速發展,小紅書也加快了AI落地的步伐。2023年起,小紅書持續投入研發大模型,并推出了AI搜索應用“點點”以及內置的“問一問”功能,為用戶提供更加便捷的信息查詢服務。
小紅書的估值也在不斷攀升。根據金沙江創投旗下的一份股份交易文件顯示,小紅書的估值已從200億美元大幅躍升至260億美元。這一估值不僅遠超B站、知乎等上市公司,也逼近了快手的市值。小紅書的老股報價已經達到了350億美元,市場對其未來發展充滿期待。
作為未來工作的一部分,小紅書hi lab將繼續致力于訓練更強大的模型,并探索更高效的架構設計。同時,該團隊還將加深對最佳訓練數據的理解,并探索實現更接近人類學習效率的方法,以期從每個訓練示例中最大限度地獲取知識。小紅書hi lab還計劃為社區貢獻更多更優的全模態大模型,推動AI技術的進一步發展和應用。





