在探索人工智能的無限可能時,大型語言模型(LLMs)無疑占據(jù)了舉足輕重的地位。它們憑借卓越的自然語言理解和生成能力,在問答、翻譯、文本創(chuàng)作等多個領域大放異彩。然而,隨著模型體積的不斷膨脹,對計算資源的需求也水漲船高,這在端側(cè)設備上尤為棘手,因為這些設備的計算能力往往有限。從智能家居到智能座艙,端側(cè)設備無處不在,它們對小型、高效的語言模型需求迫切。
在此背景下,小型語言模型(SLMs)的研究逐漸升溫。微軟作為行業(yè)巨頭,憑借其深厚的研發(fā)實力,推出了Phi系列小模型,為資源受限的端側(cè)環(huán)境提供了切實可行的解決方案。這一系列模型以較小的體積和較低的計算需求,實現(xiàn)了令人矚目的語言理解和生成能力。
Phi-1作為系列的開山之作,基于Transformer架構(gòu),擁有1.3億參數(shù)。盡管規(guī)模不大,但在Python編程任務上,Phi-1的表現(xiàn)卻令人眼前一亮,尤其在Humaneval和MBPP基準測試中,其性能接近甚至超越了某些大型模型。這一成就為小型模型的發(fā)展奠定了堅實的基礎。
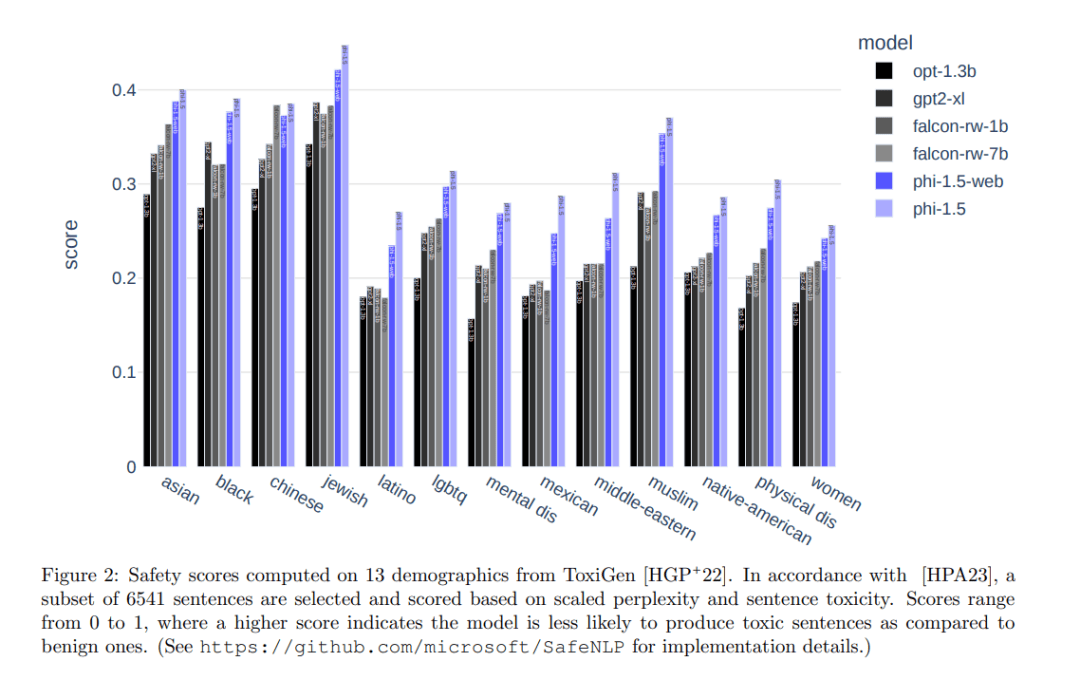
Phi-1.5在Phi-1的基礎上進行了優(yōu)化和擴展,同樣擁有1.3億參數(shù),但訓練數(shù)據(jù)得到了顯著提升。通過引入涵蓋科學、日常活動和心智理論等領域的教科書內(nèi)容,以及高質(zhì)量互聯(lián)網(wǎng)數(shù)據(jù),Phi-1.5在自然語言任務上的表現(xiàn)與比其大五倍的模型相當,甚至在復雜推理任務上超越了多數(shù)非前沿LLMs。
Phi-2則進一步提升了性能,擁有2.7億參數(shù)。通過創(chuàng)新的知識轉(zhuǎn)移技術,Phi-2在Phi-1.5的基礎上加速了訓練過程,并在基準測試中取得了顯著進步。在多個復雜基準測試中,Phi-2能夠匹配或超越比其規(guī)模大25倍的模型。Phi-2還在安全性和偏見方面進行了改進,減少了生成有害內(nèi)容的可能性。
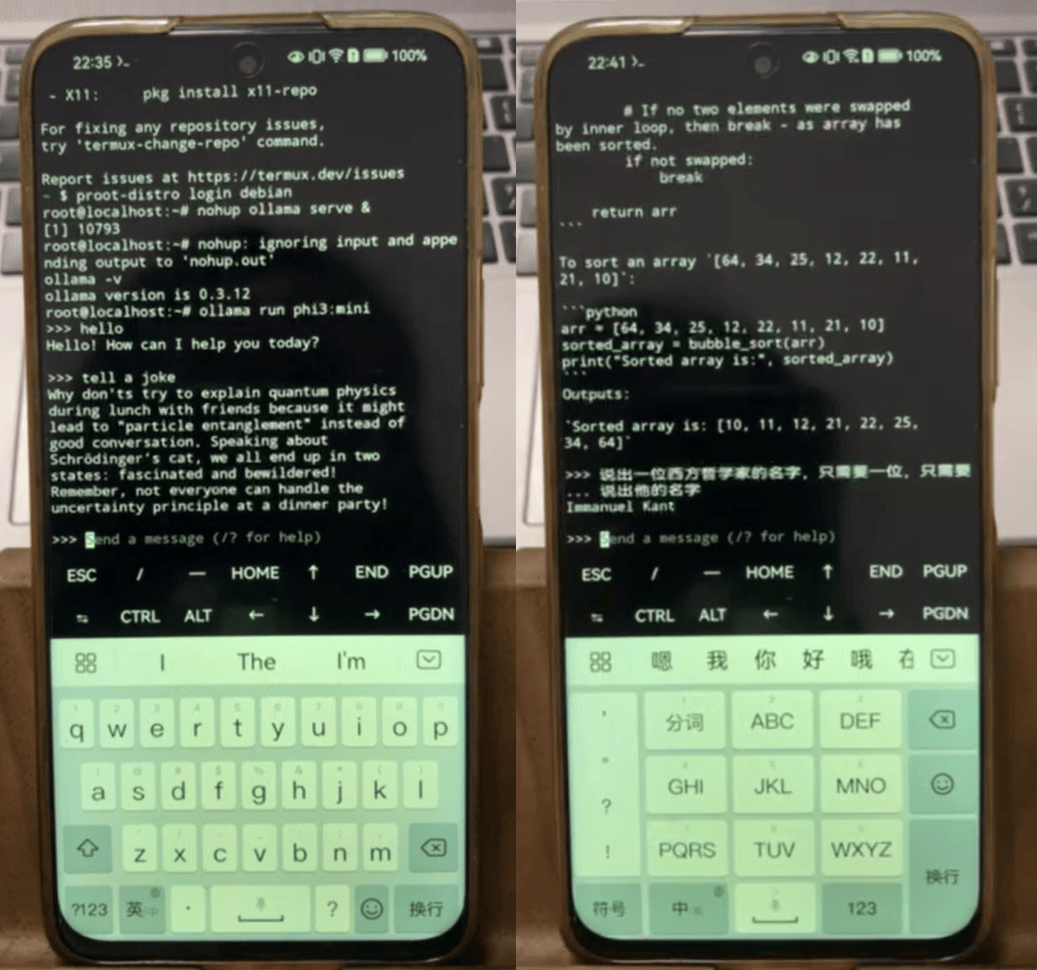
Phi-3系列則推出了三個不同量級的小模型:Phi-3 mini、Phi-3 small和Phi-3 medium。其中,Phi-3-mini擁有3.8B參數(shù),性能接近或等同于市場上的大型模型。在MMLU和MT-bench等學術基準測試中表現(xiàn)出色。量化后的Phi-3-mini可在iPhone 14上實現(xiàn)快速推理,同時也可部署在Android或HarmonyOS操作系統(tǒng)的手機上。
Phi-3系列還包含了一個多模態(tài)模型——Phi-3-vision,融合了視覺和語言功能。它能夠結(jié)合文本和圖像進行推理,從圖像中提取和推理文本,優(yōu)化對圖表和圖像的理解。在小型模型中提供了出色的語言和圖像推理質(zhì)量。在PC的CPU上部署Phi-3-vision,通過量化技術減少模型大小,實現(xiàn)了高效的多模態(tài)問答。

最新一代的Phi-3.5系列小模型則進一步提升了性能和靈活性。該系列包括Phi-3.5-mini、Phi-3.5-MoE和Phi-3.5-vision三個模型,分別針對輕量級推理、混合專家系統(tǒng)和多模態(tài)任務設計。Phi-3.5系列支持多種語言,并采用了組查詢注意力機制和塊稀疏注意力模塊,以提高訓練和推理速度。
Phi-3.5-mini專為遵守指令而設計,支持快速推理任務,適合在內(nèi)存或計算資源受限的環(huán)境中執(zhí)行代碼生成、數(shù)學問題求解和基于邏輯的推理任務等。Phi-3.5-MoE則采用了混合專家架構(gòu),將多個不同類型的模型組合成一個,每個模型專門處理不同的任務,適合處理復雜的多語言和多任務場景。Phi-3.5-vision則繼續(xù)發(fā)揮其多模態(tài)優(yōu)勢,在圖像和文本推理方面表現(xiàn)出色。
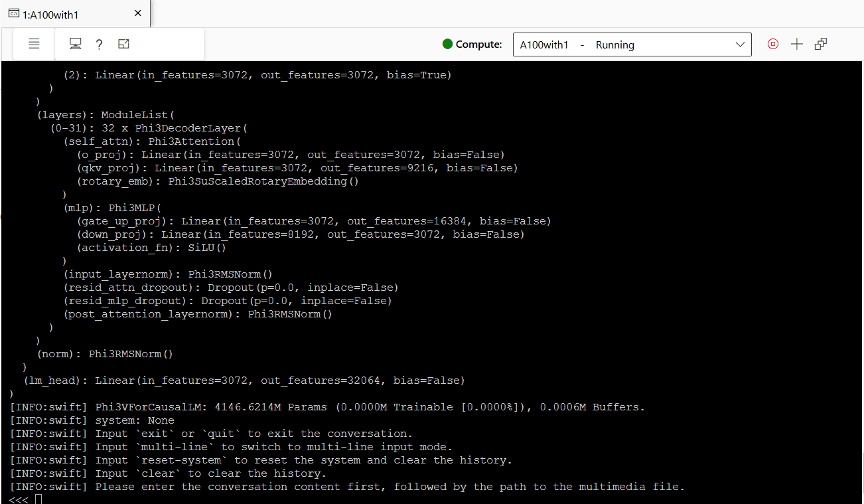
以Phi-3.5-vision為例,我們展示了其在GPU上的推理部署和測試過程。在Azure Machine Learning平臺上,我們創(chuàng)建了一臺A100 GPU,并安裝了必要的軟件和庫。通過運行推理模型,我們實現(xiàn)了與Phi-3.5-vision的交互,包括文本問答和多模態(tài)問答。在測試過程中,Phi-3.5-vision展現(xiàn)了出色的性能和準確性,同時保持了較低的GPU顯存占用。