
近期,關于OpenAI的o3人工智能模型在基準測試上的表現引發了廣泛關注與討論。爭議的核心在于,OpenAI首次發布o3模型時公布的測試結果與外界第三方機構的測試結果存在顯著差異。
去年12月,OpenAI自豪地宣布,其o3模型在極具難度的FrontierMath數學問題集上取得了突破性成績,正確率超過四分之一,遠超其他競爭對手。OpenAI首席研究官Mark Chen在直播中強調,這一成績是在內部激進測試條件下,使用資源更為強大的o3模型版本所得出的。

然而,事情并未如此簡單。負責FrontierMath的Epoch研究所隨后公布的獨立基準測試結果顯示,公開發布的o3模型得分僅為約10%,遠低于OpenAI宣稱的分數。這一發現立即引發了外界對OpenAI透明度和測試實踐的質疑。
值得注意的是,OpenAI在12月公布的測試結果中確實包含了一個與Epoch測試結果相符的較低分數。Epoch在報告中指出,測試設置的差異、評估使用的FrontierMath版本更新,以及可能的計算資源和框架不同,都可能是導致結果差異的原因。
ARC Prize基金會也在X平臺上發布消息,進一步證實了Epoch的報告。ARC Prize指出,公開發布的o3模型是一個針對聊天和產品使用進行了調整的不同版本,且所有發布的o3計算層級都比預發布版本要小。這意味著,盡管o3模型在內部測試中取得了高分,但公開發布的版本在性能上有所妥協。
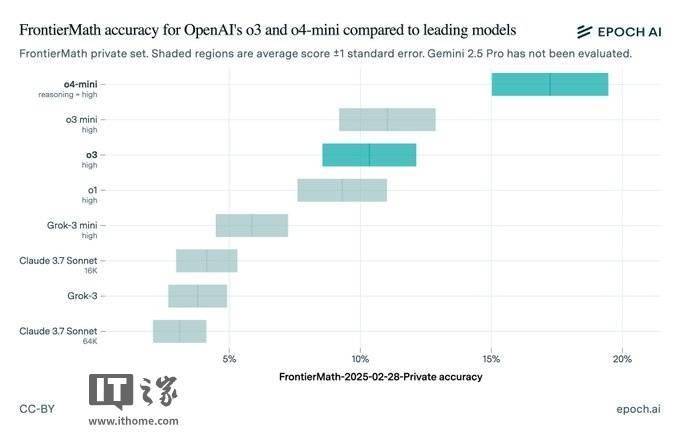
盡管如此,OpenAI并未因此止步。該公司后續推出的o3-mini-high和o4-mini模型在FrontierMath上的表現已經超越了最初的o3模型。同時,OpenAI還計劃在未來幾周內推出更強大的o3版本——o3-pro。
然而,這一系列事件再次凸顯了人工智能基準測試結果的復雜性和不確定性。尤其是當這些結果來自有產品需要銷售的公司時,外界對其真實性和可靠性的質疑聲往往會更加響亮。隨著人工智能行業的競爭加劇,各供應商紛紛急于推出新模型以吸引眼球和市場份額,基準測試“爭議”正變得越來越普遍。
事實上,類似的爭議并非個例。今年1月,Epoch因在OpenAI宣布o3之后才披露其從OpenAI獲得的資金支持而受到批評。許多為FrontierMath做出貢獻的學者直到公開時才知道OpenAI的參與。而最近,埃隆·馬斯克的xAI也被指控為其最新的人工智能模型Grok 3發布了誤導性的基準測試圖表。就在本月,meta也承認其宣傳的基準測試分數所基于的模型版本與提供給開發者的版本不一致。





