阿里巴巴近日正式推出了其通義千問家族的最新成員——Qwen2.5-Omni-7B,這是一款具備端到端多模態處理能力的旗艦模型。該模型能夠即時處理包括文本、圖像、音頻和視頻在內的多種輸入形式,并以實時流式的方式輸出文本與自然語音合成內容。
Qwen2.5-Omni-7B已在Hugging Face、魔搭、DashScope等平臺以Apache 2.0開源協議發布,其相關論文也全面開源,向公眾詳細揭示了背后的技術創新。用戶不僅能夠通過Demo體驗互動功能,還能在Qwen Chat平臺上像進行電話和視頻通話一樣與Qwen進行實時交流。
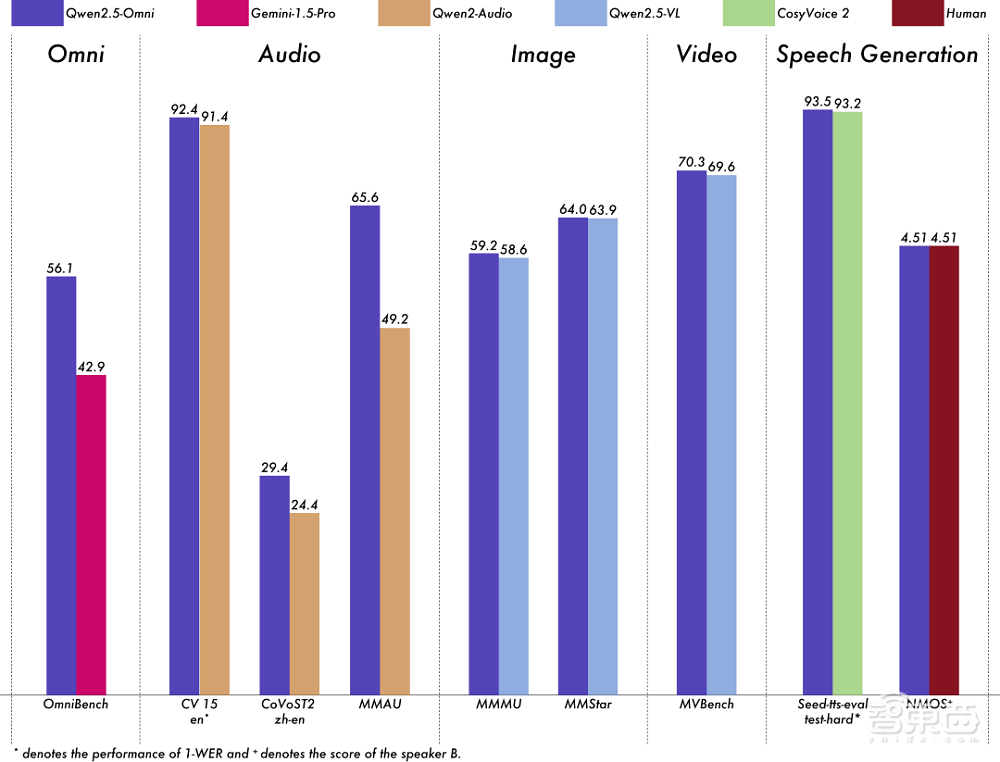
千問團隊表示,Qwen2.5-Omni采用了創新的Thinker-Talker架構,這一架構不僅支持跨模態理解,還能實現流式文本和語音響應,同時支持分塊輸入和即時輸出。在與同規模模型的基準測試中,Qwen2.5-Omni展現出了顯著優勢,超越了包括Gemini 1.5 Pro和GPT-4o-mini在內的閉源模型。
在音頻處理能力上,Qwen2.5-Omni相較于同體積的Qwen2-Audio更為出色,與Qwen2.5-VL-7B保持相當水平。在權威的多模態理解測試OmniBench上,Qwen2.5-Omni更是取得了SOTA表現,超越了Gemini 1.5 Pro,提升幅度高達30.8%。
Qwen2.5-Omni在端到端語音指令跟隨方面的表現與文本輸入處理同樣出色,在MMLU通用知識理解和GSM8K數學推理等基準測試中均取得了不俗的成績。Qwen2.5-Omni在現實世界的多模態場景中也有著廣泛的應用潛力。
例如,在烹飪場景中,用戶只需向Qwen2.5-Omni展示食材,它就能迅速提供食譜建議。Qwen2.5-Omni還能聽懂音樂,分析歌曲風格并提出創作建議。在繪畫時,它能根據草圖判斷繪畫內容并提供構圖建議。無論是戶外天氣判斷,還是學習輔助解題和論文閱讀,Qwen2.5-Omni都展現出了強大的通用多模態能力。
Qwen2.5-Omni的Thinker模塊負責處理多模態輸入,生成高層語義表征及對應文本內容,而Talker模塊則負責以流式方式接收Thinker的輸出,并流暢合成語音。這種Thinker-Talker雙核架構,結合創新的TMRoPE位置編碼技術,使得Qwen2.5-Omni在多模態理解基準測試中取得了卓越表現。
在OmniBench測試中,Qwen2.5-Omni的得分為56.13%,遠超第二名的42.91%。在視頻到文本任務上,Qwen2.5-Omni也超越了原本的開源SOTA模型和GPT-4o-mini。在其他基準測試中,如語音識別、翻譯、音頻理解、圖像推理、視頻理解以及語音生成等方面,Qwen2.5-Omni的成績均超過了Qwen家族的其他單模態模型。
Qwen2.5-Omni的推出,無疑為阿里巴巴在多模態人工智能領域樹立了新的里程碑。隨著技術的不斷進步,Qwen2.5-Omni未來有望在更多領域發揮重要作用,為用戶提供更加智能、便捷的服務。