
近日,清華大學攜手瑞萊智慧公司,共同發布了一款名為RealSafe-R1的大語言模型。該模型是對DeepSeek R1的深度優化與強化訓練成果,不僅保持了卓越的性能穩定性,更在安全性方面實現了質的飛躍,超越了諸如Claude3.5和GPT-4o等被廣泛認為安全性較高的閉源大模型,為開源大模型的安全發展提供了創新性的路徑。
DeepSeek作為國產開源大模型的佼佼者,其在自然語言處理和多任務推理領域展現出的強大實力令人矚目,尤其在處理復雜問題和創造性任務時更是表現出色。然而,即便是如此優秀的模型,在面對如越獄攻擊等安全挑戰時,也暴露出了局限性。惡意設計的輸入可能會誤導模型,導致生成不安全或不符合預期的響應。這一安全問題并非DeepSeek獨有,而是開源大模型普遍面臨的難題,根源在于安全對齊機制的不足。
針對這一問題,清華大學與瑞萊智慧的聯合團隊提出了創新的解決方案——基于模型自我提升的安全對齊方式。這一方法將安全對齊與內省推理相結合,使大語言模型能夠通過具備安全意識的思維鏈分析,自主識別并規避潛在風險,從而實現模型自身能力的進化。該方案不僅適用于DeepSeek系列模型,還可廣泛應用于其他開源或閉源模型。
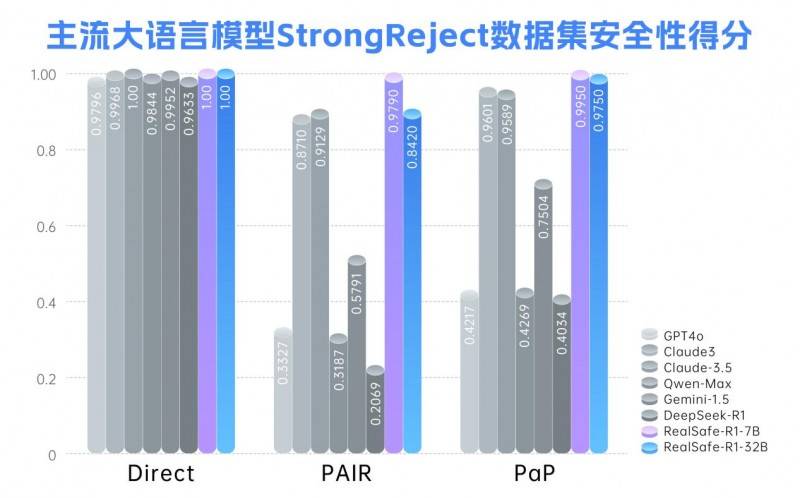
基于上述創新方法,團隊對DeepSeek-R1系列模型進行了后訓練,成功推出了RealSafe-R1系列大模型。實驗數據表明,RealSafe-R1在安全性方面取得了顯著提升,有效增強了模型對各種越獄攻擊的抵抗力,同時減輕了安全與性能之間的沖突,整體表現優于Claude3.5和GPT-4o等閉源大模型。這一成果不僅豐富了DeepSeek生態,更為大語言模型的安全發展樹立了新的標桿。
瑞萊智慧首席執行官田天表示:“大模型的安全性瓶頸是制約人工智能產業高質量發展的關鍵因素。只有通過持續投入和創新,補齊安全短板,我們才能為政務、金融、醫療等嚴肅場景的應用提供更為可靠的堅實基座。”據悉,RealSafe-R1各尺寸模型及數據集將于近期向全球開發者開放,這將為開源大模型的安全性加固提供有力支持,進一步推動人工智能技術的廣泛應用與發展。





