擊這里在線咨詢客服")
Excel提供了排序功能,可以方便地對(duì)選中的列表進(jìn)行排序。本文給出一個(gè)基于公式的排序解決方案,將指定區(qū)域內(nèi)的數(shù)據(jù)按字母順序排序。
如下圖1所示,在單元格區(qū)域A2:A11中是一組未排序的數(shù)據(jù),在單元格區(qū)域B2:B11中是已排序的數(shù)據(jù)。
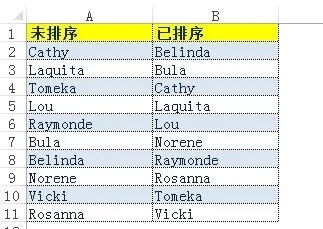
圖1
解決方案
在單元格B2中輸入公式:
=LOOKUP(1,0/FREQUENCY(ROWS($1:1),COUNTIF($A$2:$A$11,”<=”&$A$2:$A$11)),$A$2:$A$11)
向下拉至單元格B11。
工作原理
讓我們以單元格B8中的公式為例來(lái)分析:
=LOOKUP(1,0/FREQUENCY(ROWS($1:7),COUNTIF($A$2:$A$11,”<=”&$A$2:$A$11)),$A$2:$A$11)
與單元格B2中的公式相比,唯一的變化是ROWS函數(shù)內(nèi)由1改成了7。
公式中:
COUNTIF($A$2:$A$11,”<=”&$A$2:$A$11)
對(duì)于該區(qū)域內(nèi)的每個(gè)字符串,返回一個(gè)值數(shù)組,對(duì)應(yīng)該區(qū)域內(nèi)按字母順序位于該字符串之前或等于該字符串的字符串?dāng)?shù)。因此,上述公式轉(zhuǎn)換為:
{3;4;9;5;7;2;1;6;10;8}
例如,所得到的數(shù)組中的第7個(gè)元素是1,是單元格B8中的字符串“Belinda”比較后的結(jié)果:按字母順序,在區(qū)域內(nèi)只有一個(gè)字符串在該字符串之前或等于該字符串,因此該字符串就是“Belinda”自身。
同樣,在所得到的數(shù)組中的第2個(gè)元素是4,對(duì)應(yīng)單元格B3中的“Laquita”比較后的結(jié)果:按字母順序,在區(qū)域內(nèi)有四個(gè)字符串在該字符串之前或等于該字符串,分別是“Belinda”、“Bula”、“Cathy”和“Laquita”自身。
現(xiàn)在,將這個(gè)數(shù)組作為參數(shù)bins_array的值傳遞給FREQUENCY函數(shù),將公式所在單元格對(duì)應(yīng)行的相對(duì)行號(hào)(此處為7,由ROWS($ 1:7)給出)作為參數(shù)data_array的值。這樣:
FREQUENCY(ROWS($1:7),COUNTIF($A$2:$A$11,”<=”&$A$2:$A$11))
轉(zhuǎn)換為:
FREQUENCY(7,{3;4;9;5;7;2;1;6;10;8})
得到:
{0;0;0;0;1;0;0;0;0;0;0}
然后,選擇適當(dāng)?shù)闹祦?lái)調(diào)整該數(shù)組(這里選擇的是0;也可選擇1,這樣的話lookup_value的值應(yīng)為2而不是1更保險(xiǎn)),此時(shí):
0/FREQUENCY(ROWS($1:7),COUNTIF($A$2:$A$11,”<=”&$A$2:$A$11))
轉(zhuǎn)換為:
{#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;0;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!}
將其傳遞給LOOKUP函數(shù),公式:
=LOOKUP(1,0/FREQUENCY(ROWS($1:7),COUNTIF($A$2:$A$11,”<=”&$A$2:$A$11)),$A$2:$A$11)
轉(zhuǎn)換為:
LOOKUP(1,{#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;0;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!;#DIV/0!},$A$2:$A$11)
在數(shù)組中唯一的數(shù)字在第5位,因此可得到結(jié)果:
Raymonde
也可以使用下面的公式獲得同樣的結(jié)果:
=INDEX($A$2:$A$11,MATCH(1,FREQUENCY(ROWS($1:7),COUNTIF($A$2:$A$11,”<=”&$A$2:$A$11)),0))
小結(jié)
雖然可以使用Excel的排序功能,但使用公式可以實(shí)時(shí)更新數(shù)據(jù)。





