擊這里在線咨詢客服")
作為當(dāng)前最火的AI應(yīng)用,ChatGPT在積累了1億用戶之后開(kāi)始嘗試商業(yè)運(yùn)營(yíng)了,昨天正式發(fā)布了API,企業(yè)可以付費(fèi)接入,75萬(wàn)單詞只要2美元,成本比之前降低了90%。
實(shí)際上昨天開(kāi)放的業(yè)務(wù)還有一個(gè),那就是語(yǔ)音轉(zhuǎn)文字的API,基于公司的Whisper大模型,去年9月份首次推出Whisper Large-v1模型,12月開(kāi)源了升級(jí)版的Whisper Large-v2模型。
這次商業(yè)化之后,Whisper API的收費(fèi)也很低廉,每分鐘只要0.006美元,人民幣約為4分錢(qián),預(yù)計(jì)會(huì)讓很多語(yǔ)音相關(guān)的企業(yè)壓力很大。
Whisper API支持對(duì)語(yǔ)音文件進(jìn)行轉(zhuǎn)錄和翻譯,并支持包括英語(yǔ)、中文、阿拉伯語(yǔ)、日語(yǔ)、德語(yǔ)、西班牙語(yǔ)等幾十種語(yǔ)言。
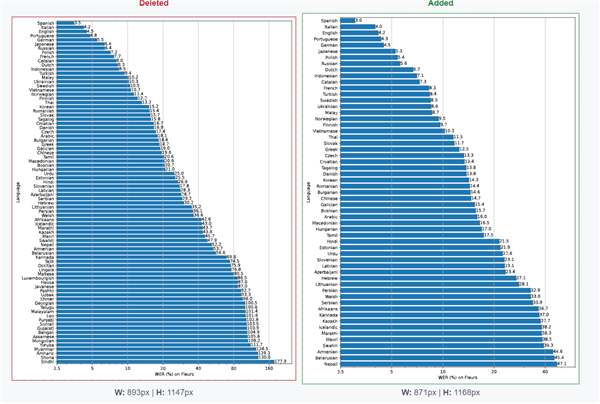
不過(guò)不同語(yǔ)言的準(zhǔn)確率差別不小,Whisper large-v2模型在識(shí)別西語(yǔ)、英語(yǔ)、意大利語(yǔ)、德語(yǔ)等語(yǔ)言單詞錯(cuò)誤率都能控制在5%以內(nèi),這種語(yǔ)言轉(zhuǎn)文字之后只需要用戶簡(jiǎn)單修改就好。
至于中文,v1模型的錯(cuò)誤率就有19.6%,v2略微提升到14.7%,改進(jìn)不大,錯(cuò)誤率比英文、西語(yǔ)之類的高很多,用戶使用起來(lái)有些麻煩,需要校正的地方就多。
至于為何有這樣的差距,除了中文自身的特點(diǎn)之外,很可能跟訓(xùn)練使用的中文語(yǔ)料較少有關(guān),畢竟網(wǎng)上的內(nèi)容主要還是外文。
來(lái)源:快科技





