擊這里在線咨詢(xún)客服")
不做大模型,就沒(méi)有算力用。
這是ChatGPT點(diǎn)燃AI風(fēng)口后,國(guó)內(nèi)某top3高校AI實(shí)驗(yàn)室的殘酷現(xiàn)狀。
同一個(gè)實(shí)驗(yàn)室里,非大模型團(tuán)隊(duì)6人用4塊3090卡,比起同實(shí)驗(yàn)室的大模型團(tuán)隊(duì)10個(gè)人用10塊A800卡,本就已經(jīng)不算富裕。
現(xiàn)在,校企合作也更偏愛(ài)大模型。去年11月ChatGPT發(fā)布后,與非大模型團(tuán)隊(duì)合作的企業(yè)驟減,近期找上門(mén)的,也是張口就問(wèn):
“你們做大模型不?”
做,有高校和企業(yè)的通力支持;不做?那就只能眼睜睜看著算力花落別家。
哪怕某量化私募基金的有10000張A100卡,還對(duì)高校研究團(tuán)隊(duì)開(kāi)放申請(qǐng),也不見(jiàn)得能落一張到你頭上。

“要是我們組能分到一些就好了。”看到這條微博,非大模型團(tuán)隊(duì)帶隊(duì)的數(shù)據(jù)科學(xué)方向博士小哥羨慕不已,因?yàn)槿彼懔Γ汲畹每煅鎏扉L(zhǎng)嘯了:我們也值得投資啊!!!
現(xiàn)在,大伙爭(zhēng)先恐后撲向ChatGPT背后GPT-3.5般的各種大模型,算力流向亦然。
其他AI領(lǐng)域本就不足的算力更荒了,尤其是國(guó)內(nèi)學(xué)界手里的算力分配下來(lái),貧富差距肉眼可見(jiàn)。
一整個(gè)實(shí)驗(yàn)室就4塊3090卡
巨大規(guī)模算力以月為單位的租用成本,對(duì)研究團(tuán)隊(duì)來(lái)說(shuō)不是小數(shù)目。大模型正當(dāng)其道,學(xué)界研究大模型的實(shí)驗(yàn)室或團(tuán)隊(duì)擁有算力資源的優(yōu)先分配權(quán)。
就拿小哥在學(xué)校的親身體驗(yàn)來(lái)說(shuō),在他們研究室,大模型小組10個(gè)人有10塊A800卡可用,而另一個(gè)研究傳統(tǒng)機(jī)器學(xué)習(xí)方向的實(shí)驗(yàn)室,整個(gè)實(shí)驗(yàn)室只有4塊3090卡。
擁抱主流趨勢(shì)是一重原因,另一重原因是實(shí)驗(yàn)室需要運(yùn)轉(zhuǎn)和維護(hù)的經(jīng)費(fèi),獲得撥款的一種形式是申請(qǐng)國(guó)家項(xiàng)目,但必要步驟是提供論文成果。
雙重原因下,本就不多的算力資源,不得不優(yōu)先分配給大模型這樣熱門(mén)且相對(duì)容易出成果的研究。哪怕對(duì)學(xué)界來(lái)說(shuō),訓(xùn)一個(gè)大模型其實(shí)練不太動(dòng)——因?yàn)閿?shù)據(jù)、算力和資金都有些捉襟見(jiàn)肘。
為了獲得更多的資源,有的非大模型實(shí)驗(yàn)室甚至額外專(zhuān)門(mén)成立研究大模型的團(tuán)隊(duì)。
當(dāng)然,想要獲得資金和資源,校企合作也是不可或缺的一種方式。
這種推動(dòng)產(chǎn)研融合的重要支撐形式持續(xù)已久,2020年,KDD中校企合作論文占比超過(guò)50%,這個(gè)比例在ICCV中達(dá)到45%。
舉例來(lái)說(shuō),2021年,清華大學(xué)KEG、PACMAN(并行與分布式計(jì)算機(jī)系統(tǒng))、NLP等實(shí)驗(yàn)室著手推進(jìn)訓(xùn)練千億參數(shù)的稠密模型,但團(tuán)隊(duì)用于訓(xùn)練模型的計(jì)算資源并不充足。最終,校外企業(yè)智譜AI租用了近百臺(tái)A100的服務(wù)器,免費(fèi)提供所需算力,這才有了雙語(yǔ)預(yù)訓(xùn)練語(yǔ)言大模型GLM-130B的誕生。
GLM-130B的任務(wù)表現(xiàn)
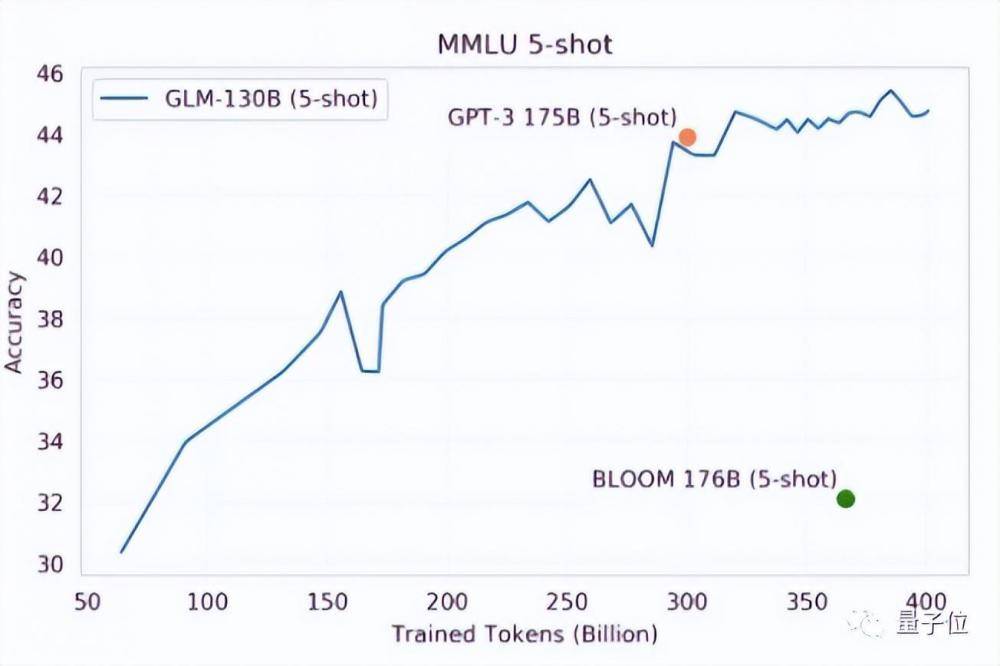
但在眾人爭(zhēng)先恐后撲向GPT-3.5般大模型的當(dāng)下,非大模型團(tuán)隊(duì)開(kāi)始不太好談這類(lèi)合作了。
去年11月ChatGPT發(fā)布后,與小哥所在團(tuán)隊(duì)洽談校企合作事宜的公司數(shù)量急劇減少。在其他高校,AI領(lǐng)域的非大模型團(tuán)隊(duì)也總是面臨企業(yè)詢(xún)問(wèn),“要不要/會(huì)不會(huì)做大模型”。
本就稀缺的算力,在學(xué)界有成為追逐熱點(diǎn)的砝碼的傾向,算力資源分配的馬太效應(yīng)由此逐漸擴(kuò)大,帶給學(xué)術(shù)研究很大困擾。
ChatGPT加劇算力分配貧富分化
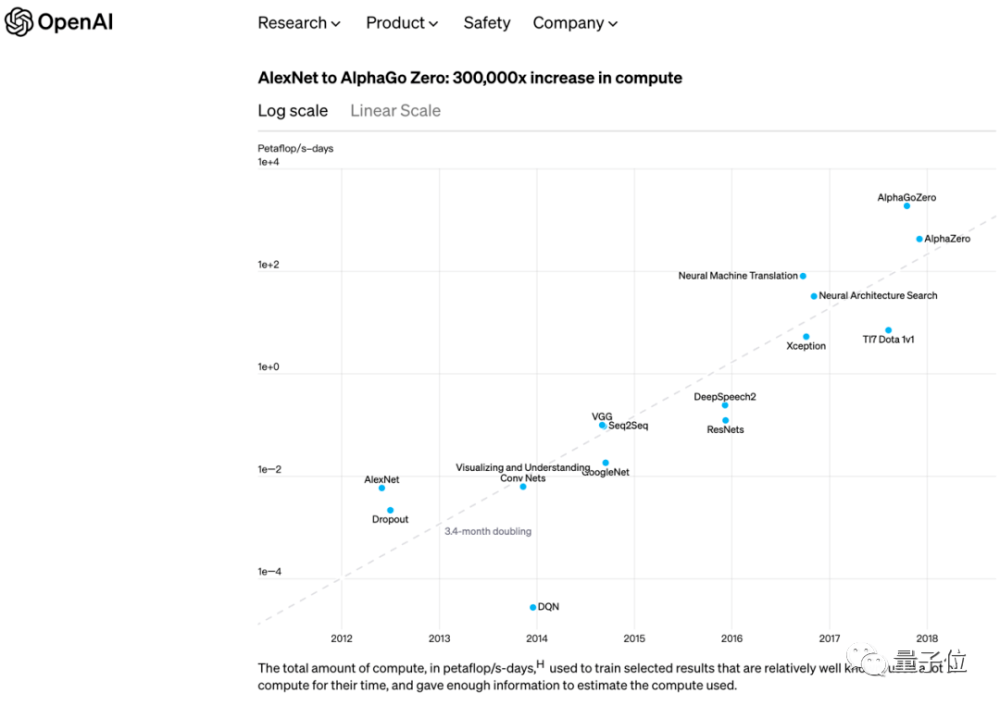
算力是AI飛速發(fā)展必不可少的指標(biāo),2018年,OpenAI發(fā)布的報(bào)告中點(diǎn)出一個(gè)算力趨勢(shì):
自2012年以來(lái),AI訓(xùn)練任務(wù)所運(yùn)用的算力每3.43個(gè)月就會(huì)翻倍。到2018年,AI算力需求增長(zhǎng)了30萬(wàn)倍。
產(chǎn)學(xué)研對(duì)算力需求暴增,我們能提供的算力有多少?
據(jù)中國(guó)算力集團(tuán)統(tǒng)計(jì),截至2022年6月底,我國(guó)數(shù)據(jù)中心機(jī)架使用總規(guī)模超過(guò)590萬(wàn)標(biāo)準(zhǔn)機(jī)架,服務(wù)器規(guī)模約2000萬(wàn)臺(tái),算力總規(guī)模排名全球第2。
這個(gè)排名還算不錯(cuò),但攤開(kāi)來(lái)看仍舊遠(yuǎn)遠(yuǎn)不夠,畢竟放眼全球,沒(méi)有哪個(gè)國(guó)家不是嗷嗷待哺,等著更多的算力資源“投喂”。
再退一步講,買(mǎi)得起顯卡,擁有的算力上去了,電費(fèi)也是天文數(shù)字。
況且我國(guó)還有特殊情況——
開(kāi)放原子開(kāi)源基金會(huì)業(yè)務(wù)發(fā)展部部長(zhǎng)朱其罡在本月舉辦的CCF YOCSEF上發(fā)言闡述現(xiàn)狀稱(chēng),超算領(lǐng)域的核心技術(shù),一個(gè)是IBM LSF超算系統(tǒng),一個(gè)是開(kāi)源系統(tǒng)。目前,國(guó)內(nèi)多數(shù)超算中心都基于開(kāi)源系統(tǒng)做封裝,但這個(gè)版本調(diào)度資源的效率和能力都有很大的提升空間。
以及,因?yàn)楸娝苤脑颍珹100、H100這倆目前性能最強(qiáng)的GPU,還沒(méi)找到可規(guī)模替代的方案。
綜上,算力不夠已是積弊,但ChatGPT時(shí)代,算力需求劇烈擴(kuò)張,除了大量訓(xùn)練算力,大量推理算力也需要支撐。
所以現(xiàn)在的情況是,因?yàn)镃hatGPT顯示出大模型的推理能力,訓(xùn)練和研究大模型的算力需求增加;同時(shí)因?yàn)榇竽P蜔岫缺铮鋼碇链竽P偷乃懔Y源也增加。
分配給大模型領(lǐng)域的算力資源豐富起來(lái),其他AI領(lǐng)域缺衣少食的情況逐漸加劇,研發(fā)能力受到掣肘。
可以說(shuō),ChatGPT成為如今的AI屆白月光后,加劇了算力分配的貧富分化。
這般“富”甲一方的大模型,是不是AI研究路徑上最好的?還沒(méi)人能夠回答。
但值得引起注意和重視的是,GPT系列為首的大模型不應(yīng)該吸引全部目光,整個(gè)AI領(lǐng)域還有各種各樣的研究方向,還有更加細(xì)分的垂直領(lǐng)域,以及帶來(lái)更多生產(chǎn)力的模型和產(chǎn)品。
當(dāng)ChatGPT的熱度趨于平緩,學(xué)界的算力資源分配差距會(huì)縮小嗎?
所有非大模型方向的實(shí)驗(yàn)室和團(tuán)隊(duì),恐怕都在期待之中。
衡宇 發(fā)自 凹非寺
量子位 | 公眾號(hào) QbitAI





