
一、 前言導讀
TiDB作為NewSQL,其在對MySQL(SQL92協議)的兼容上做了很多,MySQL作為當下使用較廣的事務型數據庫,在IT界尤其是互聯網間使用廣泛,那么對于開發人員來說,1)兩個數據庫產品在SQL開發及調優的過程中,都有哪些差異?在系統遷移前需要提前做哪些準備? 2)TiDB的執行計劃如何查看,如何SQL調優? 本文做了一個簡要歸納,歡迎查閱交流。
二、 建表SQL語法差異&優化建議
分類
MySQL寫法
TiDB寫法
注意事項
建表
alter table A add column phone bigint(20),add column address varchar(100);
alter table A add column phone bigint(20); alter table A add column address varchar(100);
1.一個DDL腳本僅支持一個字段修改 2.新建表時,盡量提前規劃好相應字段
建表
create table A(`id` bigint(20) NOT NULL AUTO_INCREMEN)
create table A(`id` bigint(20) NOT NULL AUTO_INCREMEN)
TiDB自增主鍵全局唯一,但不嚴格遞增(僅各Server內部連續) 需要嚴格連續自增主鍵時,業務系統自己生成寫入
建表
create table A as select * from B
不支持
建表
create temporary table A
不支持
不支持臨時表
SQL DML提交前,建議結合explain和explain analyze命令和業務場景,確認執行計劃
三、 查詢SQL語法差異&優化建議
分類
MySQL寫法
TiDB寫法
注意事項
查詢 (結果條數統計)
select * from A select count(*) from A
select name,age,address from A select count(age) from A
1.避免全量字段查詢,節省網絡帶寬 2.當開啟TiFlash統計行數據時,TiDB會使用列模式提升查詢性能
查詢 (閉區間查詢)
select name,age from A where age>10
select name,age from A where age>10 and id<99
TiDB針對限定數據范圍的閉區間查詢,能減少全表掃描概率
查詢 (時間排序)
select name,age from A order by id(主鍵)
select name,age from A order by create_time(時間索引)
分布式數據庫主鍵不再連續,需要時間順序排序時,可新增時間字段
查詢 (結果字段分堆)
select name,age from A group by name
select name,age from A group by name,age
需要分堆的所有字段,在SQL中必須顯示標識
查詢 (結果字段排序)
select name,age from A order by name
select name,age from A order by name,age
需要排序的所有字段,在SQL中必須顯示標識
查詢 (索引優化)
select name,age from A where name=‘張三’ and age>110 and cityName!='北京'
盡可能的將使用頻率高的,經常被點查使用的列排在前面,將經常進行范圍查詢的列排在后面
查詢 (顯示優化規則) DBA不建議
select name,age from A where name='張三'
select name,age from A where name='張三' use index(name_age)
顯示通知TiDB優化器,使用name_age索引
查詢 (覆蓋索引)
select name,age from A where name='張三' order by age
ORDER BY,GROUP BY,DISTINCT 的字段需要添加在索引的后面,形成覆蓋索引
查詢 (顯示優化規則) DBA不建議
select name,age from A where name='張三'
select /*+ read_from_storage(tiflash[A]) */ name,age from A where name='張三'
顯示通知TiDB優化器,使用TiFlash提升性能
MySQL常見SQL優化規則(如not in,like ‘abc%’,減少查詢返回列,避免在索引列使用函數),對于TiDB同樣適用
四、 SQL執行計劃差異&優化建議
分類
MySQL寫法
TiDB寫法
注意事項
執行計劃
explain select count(*) from A
explain select count(*) from A explain analyze select count(*) from A
1.TiDB提供explain和explain analyze兩種查詢計劃分析,前者不會執行,后者會實際執行 2.explain參考:
https://docs.pingcap.com/zh/tidb/stable/explain-walkthrough 3.explain analyze參考:https://docs.pingcap.com/zh/tidb/stable/sql-statement-explain-analyze/
查詢 (結果分析優化)
operator中包含stats:pseudo
SQL對應表統計信息已失真,執行analyze tableName修復即可(注:關注數據期間卡表修復對業務的影響)
查詢 (類型優化)
select name,age from A where zip=0 (其中zip為bit類型)
select name,age from A where zip=0 (修改zip為int類型)
TiDB字段盡量使用常見mysql類型
注意:analyze tableName對TiDB集群的影響較大,執行前千萬與DBA做好溝通評估,臨時情況可通過顯示指定索引(USE INDEX)繞開流量高峰期
五、 TiDB執行計劃分析簡介
1. 在開始實際案例分析前,我們先看下執行計劃中每列的含義:
引自:
https://docs.pingcap.com/zh/tidb/stable/sql-statement-explain和https://docs.pingcap.com/zh/tidb/stable/sql-statement-explain-analyze
屬性名
含義
id
算子的 ID,是算子在整個執行計劃中唯一的標識。在 TiDB 2.1 中,ID 會格式化地顯示算子的樹狀結構。數據從孩子結點流向父親結點,每個算子的父親結點有且僅有一個。
estRows
算子預計將會輸出的數據條數,基于統計信息以及算子的執行邏輯估算而來。
actRows
算子實際輸出的數據條數
task
算子屬于的 task 種類。目前的執行計劃分成為兩種 task,一種叫 root task,在 tidb-server 上執行,一種叫 cop task,在 TiKV 或者 TiFlash 上并行執行。當前的執行計劃在 task 級別的拓撲關系是一個 root task 后面可以跟許多 cop task,root task 使用 cop task 的輸出結果作為輸入。cop task 中執行的也即是 TiDB 下推到 TiKV 或者 TiFlash 上的任務,每個 cop task 分散在 TiKV 或者 TiFlash 集群中,由多個進程共同執行。
access object
算子所訪問的數據項信息。包括表 table,表分區 partition 以及使用的索引 index(如果有)。只有直接訪問數據的算子才擁有這些信息。
execution info
算子的實際執行信息。time 表示從進入算子到離開算子的全部 wall time,包括所有子算子操作的全部執行時間。如果該算子被父算子多次調用 (loops),這個時間就是累積的時間。loops 是當前算子被父算子調用的次數。
operator info
算子的其它信息。各個算子的 operator info 各有不同,可參考下面的示例解讀。
memory
算子占用內存空間的大小
disk
算子占用磁盤空間的大小
2. 執行計劃優化的幾個關鍵點:
1) 重點觀察算子類型,盡量控制優化器選擇性能較優的算子,讀取磁盤記錄的幾個算子性能:TableFullScan>TableRangeScan>TableRowIDScan,IndexFullScan>IndexRangeScan
2) 盡量減小root層執行動作,下放至tikv或tiflash執行,執行計劃中task屬性包括root task和cop task,其中root標識動作由tidb聚合層執行(此操作除了需要等待各分片結果外,一般部署結構中tidb資源也較tikv或tiflash少),cop標識動作下放至tikv或tiflash各分片單獨執行
3) 保證表分析數據完整性,避免大批量數據短時間內新增/刪除,estRows為執行引擎根據情況返回的預估記錄條數,特別注意:若operator info出現stats:pseudo,則標識表基本信息不完善(無法提供準確執行計劃評估),后續可通過analyze表重新收集分析數據,或顯示use index對sql顯示優化
4) 根據實際業務(如:列模式數據統計),增加tiflash模塊,通過空間換時間,提升結構化查詢和實時分析能力
3. 實際場景分析
下面我們通過2個實際SQL說說TiDB的執行計劃:
l SQL1
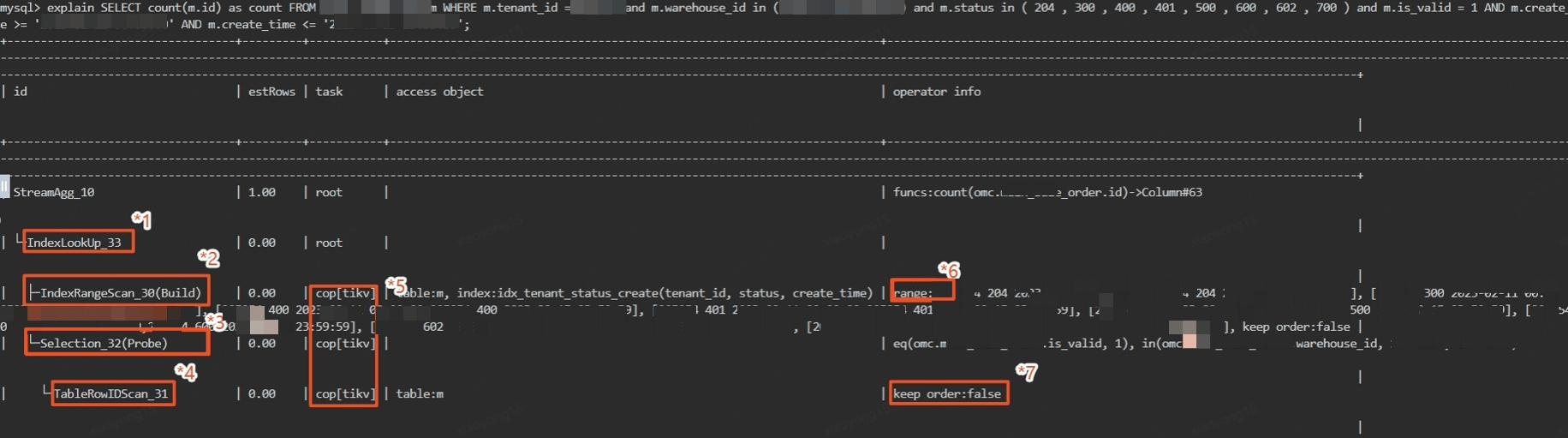
*1:IndexLookUp算子:根據索引獲取結果記錄
*2 & *3:Build算子總是優先于Probe算子執行,*2 算子根據條件從索引中獲取數據,*3算子在結果中匹配結果
*4:TableRowIdScan:通過 *3 算子結果中的表主鍵id從TiKV獲取行記錄
*5:cop【tikv】標識將計算邏輯從tidb下放到tikv執行,同理還會有cop【tiflash】
*6:tikv通過范圍索引掃描出對應記錄
*7:根據id獲取行記錄后直接返回上層,無需排序
------------------------------------------------------------------------------------------------------------------------------
l SQL2
優化前,兩表直接join:
explain analyze SELECT m.id AS id, m.order_id AS orderId, s.status AS status,m.sendpay_map as sendPayMap FROM tableA m LEFT JOIN tableB s on m.order_id = s.order_id WHERE m.id >= 100 AND m.id <= 100000000 and m.warehouse_id in (111,222) and s.status in (100, 200, 300, 400) and m.is_valid = 1 order by m.id desc limit 20,20;

*1:IndexJoin算子:根據表s索引,與表m關聯起來
*2 & *3:Build算子總是優先于Probe算子執行,*2 算子從表m匹配相關記錄,*3算子通過表s索引獲取join管理數據
*4 & *5:基于*3算子join后的結果,篩選匹配s表條件的記錄
*6 & *7:可以看到此處表記錄查詢使用了TableReader,耗時6.41s(其中cop_task共424個,且使用了大量索引proc_keys),Selection_98根據索引回表查詢更是讀取了3.03GB記錄
總結:整體sql因為是先join在limit,tidb無法將limit操作下推,導致主表大量回表查詢,影響性能
優化后,先子查詢再join:
explain analyze select * from (SELECT m.id AS id, m.order_id AS orderId,m.sendpay_map as sendPayMap FROM tableA m WHERE m.id >= 100 AND m.id <= 100000000 and m.warehouse_id in (111 ,222) and m.is_valid = 1 order by m.id desc limit 20,20) t LEFT JOIN tableB s on t.orderId = s.order_id WHERE s.status in (100 ,200, 300, 400)
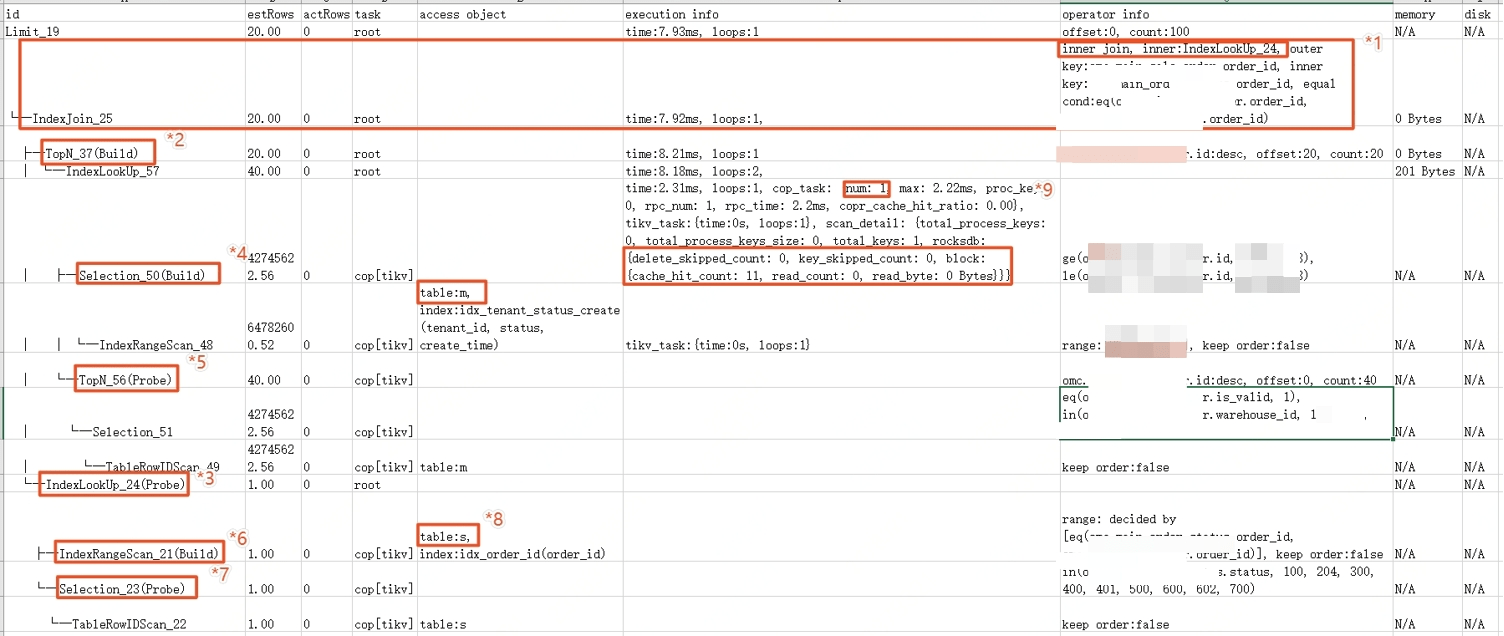
*1:IndexJoin算子:根據表s索引,與表m關聯起來
*2:從m表結果中獲取前20條記錄
*3:通過表s索引獲取join管理數據
*4:根據條件,從表m的索引中獲取記錄
*5:從*4算子結果中獲取40條記錄(tikv3副本,從2個分片各獲取20條,共40條)
*6 & *7:基于*3算子join后的結果,篩選匹配s表條件的記錄
*9:可以看到,此處是直接從IndexLookUp_57索引中查詢數據,cop_task=1,且rocksdb中命中了緩存cache_hit_count=11
總結:整體sql因為是先limit再join,tidb將limit下推至tikv,大大較少了主表的回表查詢數據量,提升性能
六、 小結
本文旨在通過TiDB和MySQl在SQL層面的差異性講解,幫助讀者在DB遷移和評估前,清楚了解雙方的差異,避免遺漏。同時,針對TiDB的執行計劃,通過簡介和2個案例,幫助大家快速分析SQL執行情況,以便針對性優化。





