擊這里在線咨詢客服")
作者:京東科技 宋慧超
一、前言
最近通過 SGM 監(jiān)控發(fā)現(xiàn)有兩個(gè) SQL 的執(zhí)行時(shí)間占該任務(wù)總執(zhí)行時(shí)間的 90%,通過對(duì)該 SQL 進(jìn)行分析和優(yōu)化的過程中,又重新對(duì) SQL 語句的執(zhí)行順序和 SQL 語句的執(zhí)行計(jì)劃進(jìn)行了系統(tǒng)性的學(xué)習(xí),整理的相關(guān)學(xué)習(xí)和總結(jié)如下;
二、SQL 語句執(zhí)行順序
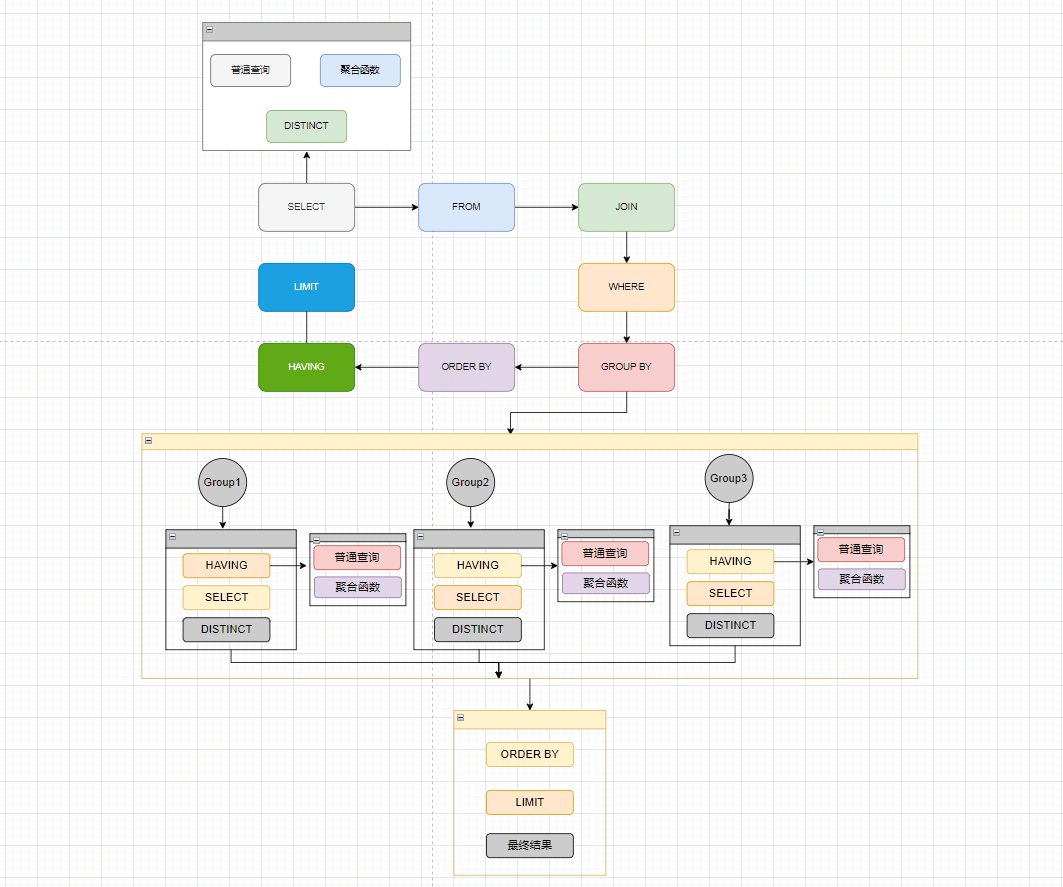
要想優(yōu)化慢 SQL 語句首先需要了解 SQL 語句的執(zhí)行順序,SQL 語句中的各關(guān)鍵詞執(zhí)行順序如下:
?首先執(zhí)行 from、join 來確定表之間的連接關(guān)系,得到初步的數(shù)據(jù)。
?然后利用 where 關(guān)鍵字后面的條件對(duì)符合條件的語句進(jìn)行篩選。
from&join&where:用于確定要查詢的表的范圍,涉及到哪些表。
選擇一張表,然后用 join 連接:
from table1 join table2 on table1.id=table2.id
選擇多張表,用 where 做關(guān)聯(lián)條件:
from table1,table2 where table1.id=table2.id
最終會(huì)得到滿足關(guān)聯(lián)條件的兩張表的數(shù)據(jù),不加關(guān)聯(lián)條件會(huì)出現(xiàn)笛卡爾積。
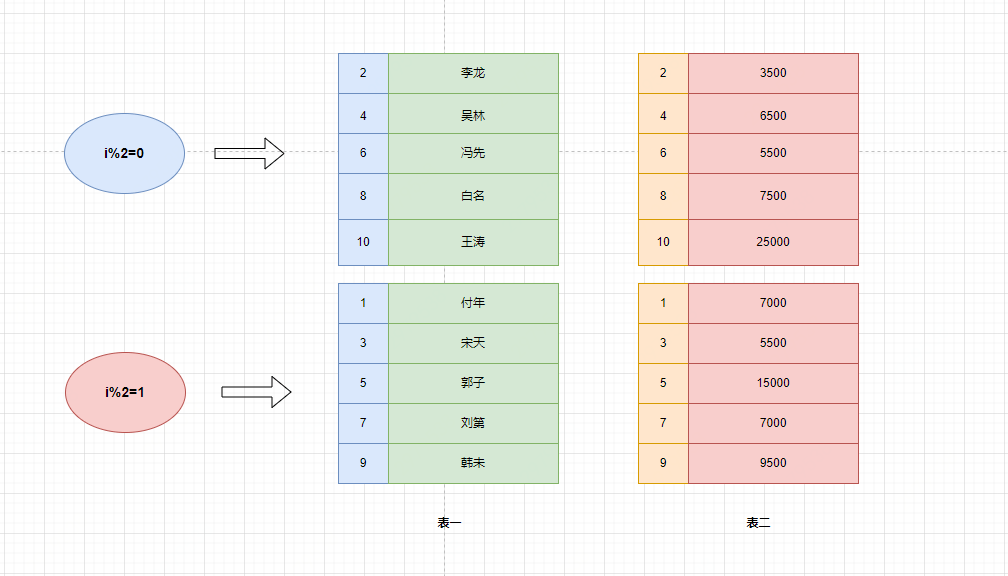
?然后利用 group by 對(duì)數(shù)據(jù)進(jìn)行分組。
按照 SQL 語句中的分組條件對(duì)數(shù)據(jù)進(jìn)行分組,但是不會(huì)篩選數(shù)據(jù)。
下面用按照 id 的奇偶進(jìn)行分組:
?然后分組后的數(shù)據(jù)分別執(zhí)行 having 中的普通篩選或者聚合函數(shù)篩選。
having&where
having 中可以是普通條件的篩選,也能是聚合函數(shù),而 where 中只能是普通函數(shù);一般情況下,有 having 可以不寫 where,把 where 的篩選放在 having 里,SQL 語句看上去更絲滑。
使用 where 再 group by : 先把不滿足 where 條件的數(shù)據(jù)刪除,再去分組。
使用 group by 在 having:先分組再刪除不滿足 having 條件的數(shù)據(jù)。(該兩種幾乎沒有區(qū)別)
比如舉例如下:100/2=50,此時(shí)我們把 100 拆分 (10+10+10+10+10…)/2=5+5+5+…+5=50, 只要篩選條件沒變,即便是分組了也得滿足篩選條件,所以 where 后 group by 和 group by 再 having 是不影響結(jié)果的!
不同的是,having 語法支持聚合函數(shù),其實(shí) having 的意思就是針對(duì)每組的條件進(jìn)行篩選。我們之前看到了普通的篩選條件是不影響的,但是 having 還支持聚合函數(shù),這是 where 無法實(shí)現(xiàn)的。
當(dāng)前的數(shù)據(jù)分組情況
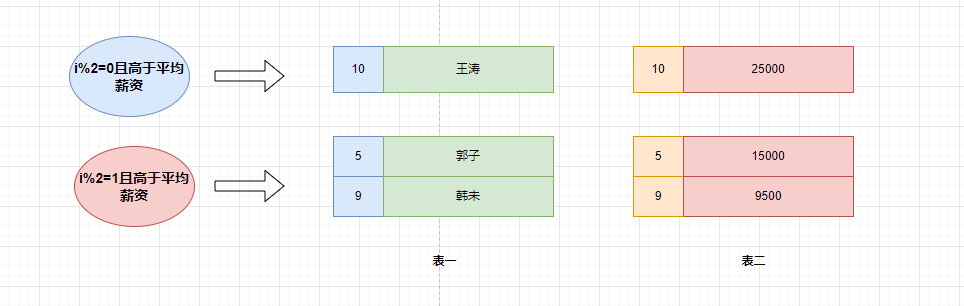
執(zhí)行 having 的篩選條件,可以使用聚合函數(shù)。篩選掉工資小于各組平均工資的 having salary<avg(salary):
然后再根據(jù)我們要的數(shù)據(jù)進(jìn)行 select,普通字段查詢或者聚合函數(shù)查詢,如果是聚合函數(shù),select 的查詢結(jié)果會(huì)增加一條字段。
分組結(jié)束之后,我們?cè)賵?zhí)行 select 語句,因?yàn)榫酆虾瘮?shù)是依賴于分組的,聚合函數(shù)會(huì)單獨(dú)新增一個(gè)查詢出來的字段,這里我們兩個(gè) id 重復(fù)了,我們就保留一個(gè) id,重復(fù)字段名需要指向來自哪張表,否則會(huì)出現(xiàn)唯一性問題。最后按照用戶名去重。
select employee.id,distinct name,salary, avg(salary)

將各組 having 之后的數(shù)據(jù)再合并數(shù)據(jù)。

?然后將查詢到的數(shù)據(jù)結(jié)果利用 distinct 關(guān)鍵字去重。
?然后合并各個(gè)分組的查詢結(jié)果,按照 order by 的條件進(jìn)行排序。
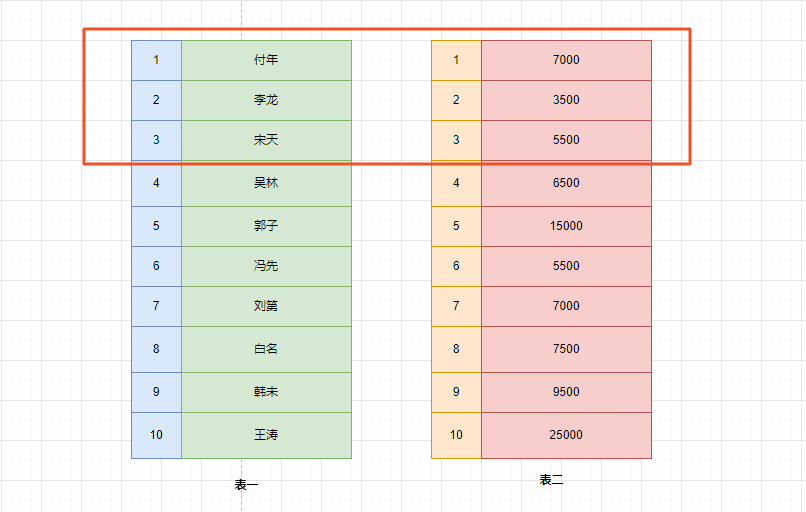
比如這里按照 id 排序。如果此時(shí)有 limit 那么查詢到相應(yīng)的我們需要的記錄數(shù)時(shí),就不繼續(xù)往下查了。
?最后使用 limit 做分頁。
記住 limit 是最后查詢的,為什么呢?假如我們要查詢薪資最低的三個(gè)數(shù)據(jù),如果在排序之前就截取到 3 個(gè)數(shù)據(jù)。實(shí)際上查詢出來的不是最低的三個(gè)數(shù)據(jù)而是前三個(gè)數(shù)據(jù)了,記住這一點(diǎn)。
假如 SQL 語句執(zhí)行順序是先做 limit 再執(zhí)行 order by,執(zhí)行結(jié)果為 3500,5500,7000 了(正確 SQL 執(zhí)行的最低工資的是 3500,5500,5500)。
SQL 查詢時(shí)需要遵循的兩個(gè)順序:
1、關(guān)鍵字的順序是不能顛倒的。
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT
2、select 語句的執(zhí)行順序(在 MySQL 和 Oracle 中,select 執(zhí)行順序基本相同)。
FROM > WHERE > GROUP BY > HAVING > SELECT的字段 > DISTINCT > ORDER BY > LIMIT
以 SQL 語句舉例,那么該語句的關(guān)鍵字順序和執(zhí)行順序如下:
SELECT DISTINCT player_id, player_name, count(*) as num #順序5
FROM player JOIN team ON player.team_id = team.team_id #順序1
WHERE height > 1.80 #順序2
GROUP BY player.team_id #順序3
HAVING num > 2 #順序4
ORDER BY num DESC #順序6
LIMIT 2 #順序7
三、SQL 執(zhí)行計(jì)劃
• 為什么要學(xué)習(xí) SQL 的執(zhí)行計(jì)劃?
因?yàn)橐粋€(gè) sql 的執(zhí)行計(jì)劃可以告訴我們很多關(guān)于如何優(yōu)化 sql 的信息 。通過一個(gè) sql 計(jì)劃,如何訪問表中的數(shù)據(jù) (是使用全表掃描還是索引查找?)一個(gè)表中可能存在多個(gè)不同的索引,表中的類型是什么、是否子查詢、關(guān)聯(lián)查詢等…
• 如何獲取 SQL 的執(zhí)行計(jì)劃?
在 SQL 語句前加上 explain 關(guān)鍵詞皆可以得到相應(yīng)的執(zhí)行計(jì)劃。其中:在 MySQL8.0 中是支持對(duì) select/delete/inster/replace/update 語句來分析執(zhí)行計(jì)劃,而 MySQL5.6 前只支持對(duì) select 語句分析執(zhí)行計(jì)劃。 replace 語句是跟 instert 語句非常類似,只是插入的數(shù)據(jù)和表中存在的數(shù)據(jù)(存在主鍵或者唯一索引)沖突的時(shí)候 **,****replace** 語句會(huì)把原來的數(shù)據(jù)替換新插入的數(shù)據(jù),表中不存在唯一的索引或主鍵,則直接插入新的數(shù)據(jù)。
• 如何分析 SQL 語句的執(zhí)行計(jì)劃?
下面對(duì) SQL 語句執(zhí)行計(jì)劃中的各個(gè)字段的含義進(jìn)行介紹并舉例說明。

?id 列
id 標(biāo)識(shí)查詢執(zhí)行的順序,當(dāng) id 相同時(shí),由上到下分析執(zhí)行,當(dāng) id 不同時(shí),由大到小分析執(zhí)行。
id 列中的值只有兩種情況,一組數(shù)字(說明查詢的 SQL 語句對(duì)數(shù)據(jù)對(duì)象的操作順序)或者 NULL(代表數(shù)據(jù)由另外兩個(gè)查詢的 union 操作后所產(chǎn)生的結(jié)果集)。
explain
select course_id,class_name,level_name,title,study_cnt
from imc_course a
join imc_class b on b.class_id=a.class_id
join imc_level c on c.level_id =a.level_id
where study_cnt > 3000

返回 3 行結(jié)果,并且 ID 值是一樣的。由上往下讀取 sql 的執(zhí)行計(jì)劃,第一行是 table c 表作為驅(qū)動(dòng)表 ,等于是以 C 表為基礎(chǔ)來進(jìn)行循環(huán)嵌套的一個(gè)關(guān)聯(lián)查詢。 (4 *100*1 =400 總共掃描 400 行等到數(shù)據(jù))
?select_type 列
值含義SIMPLE不包含子查詢或者 UNION 操作的查詢(簡(jiǎn)單查詢)PRIMARY查詢中如果包含任何子查詢,那么最外層的查詢則被標(biāo)記為 PRIMARYSUBQUERYselect 列表中的子查詢DEPENDENT SUBQUERY依賴外部結(jié)果的子查詢UNIONunion 操作的第二個(gè)或者之后的查詢值為 unionDEPENDENT UNION當(dāng) union 作為子查詢時(shí),第二或是第二個(gè)后的查詢的值為 select_typeUNION RESULTunion 產(chǎn)生的結(jié)果集DERIVED出現(xiàn)在 from 子句中的子查詢(派生表)
例如:查詢學(xué)習(xí)人數(shù)大于 3000, 合并 課程是 MySQL 的記錄。
EXPLAIN
SELECT
course_id,class_name,level_name,title,study_cnt
FROM imc_course a
join imc_class b on b.class_id =a.class_id
join imc_level c on c.level_id = a.level_id
WHERE study_cnt > 3000
union
SELECT course_id,class_name,level_name,title,study_cnt
FROM imc_course a
join imc_class b on b.class_id = a.class_id
join imc_level c on c.level_id = a.level_id
WHERE class_name ='MySQL'

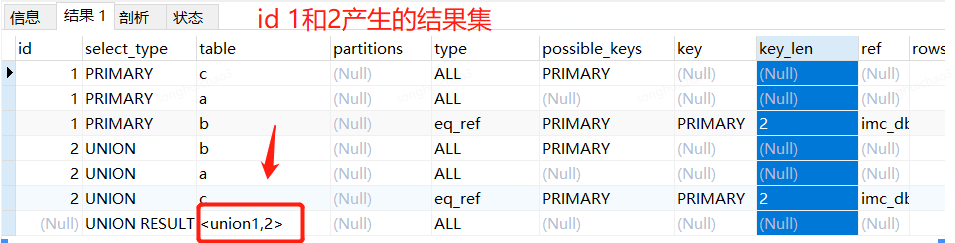
分析數(shù)據(jù)表:先看 id 等于 2
id=2 則是查詢 mysql 課程的 sql 信息,分別是 b,a,c 3 個(gè)表,是 union 操作,selecttype 為是 UNION。
id=1 為是查詢學(xué)習(xí)人數(shù) 3000 人的 sql 信息,是 primary 操作的結(jié)果集,分別是 c,a,b3 個(gè)表,select_type 為 PRIMARY。
最后一行是 NULL, select_type 是 UNION RESULT 代表是 2 個(gè) sql 組合的結(jié)果集。
?table 列
指明是該 SQL 語句從哪個(gè)表中獲取數(shù)據(jù)
值含義<table name>展示數(shù)據(jù)庫(kù)表名(如果表取了別名顯示別名)<unionM, N>由 ID 為 M、N 查詢 union 產(chǎn)生的結(jié)果集<dirived N> / <subquery N>由 ID 為 N 的查詢產(chǎn)生的結(jié)果(通常也是一個(gè)子查詢的臨時(shí)表)
EXPLAIN
SELECT
course id,class name,level name,title,study cnt
FROM imc course a
join imc class b on b.class id =a.class id
join imc level c on c.level id = a.level id
WHERE study cnt > 3000
union
SELECT course id,class name,level name,title,study _cnt
FROM imc course a
join imc class b on b.class id = a.class id
join imc level c on c.level id = a.level id
WHERE class name ='MySOL'
?type 列
注意: 在 MySQL 中不一定是使用 JOIN 才算是關(guān)聯(lián)查詢,實(shí)際上 MySQL 會(huì)認(rèn)為每一個(gè)查詢都是連接查詢,就算是查詢一個(gè)表,對(duì) MySQL 來說也是關(guān)聯(lián)查詢。
type 的取值是體現(xiàn)了 MySQL 訪問數(shù)據(jù)的一種方式。type 列的值按照性能高到低排列 system > const > eq_ref > ref > ref_or_null > index_merge > range > index > ALL
值含義systemconst 連接類型的特例,當(dāng)查詢的表只有一行時(shí)使用const表中有且只有一個(gè)匹配的行時(shí)使用,如隊(duì)逐漸或唯一索引的查詢,這是效率最高的連接方式eq_ref唯一索引或主鍵查詢,對(duì)應(yīng)每個(gè)索引建,表中只有一條記錄與之匹配【A 表掃描每一行 B 表只有一行匹配滿足】ref_or_null類似于 ref 類型的查詢,但是附加了對(duì) NULL 值列的查詢index_merge表示使用了索引合并優(yōu)化方法range索引范圍掃描,常見于 between、>、< 這樣的查詢條件indexFULL index Scan 全索引掃描,同 ALL 的區(qū)別是,遍歷的是索引樹ALLFULL TABLE Scan 全表掃描,效率最差的連接方式

• 如果 where like “MySQL%”,type 類型為?
雖然 class_name 加了索引 ,但是使用 where 的 like% 右統(tǒng)配, 所以會(huì)走索引范圍掃描。
EXPLAIN
SELECT
course id,class name,level name,title,study_cnt
FROM imc course a
join imc class b on b.class id= a.class id
join imc level c on c.level id = a.level id
WHERE class namelike'MySQL%'

• 如果 where like “% MySQL%”,type 類型為?
雖然 class_name 加了索引 ,但是使用 where 的 %like% 左右統(tǒng)配, 所以會(huì)走全索引掃描,如果不加索引的話,左右統(tǒng)配會(huì)走全表掃描。
EXPLAIN
SELECT
course id,class name,level name,title,study_cnt
FROM imc course a
join imc class b on b.class id= a.class id
join imc level c on c.level id = a.level id
WHERE class namelike'%MySQL%'

?possible_key、key 列
possible_keys 說明表可能用到了哪些索引,而 key 是指實(shí)際上使用到的索引。基于查詢列和過濾條件進(jìn)行判斷。查詢出來都會(huì)被列出來,但是不一定會(huì)是使用到。
如果在表中沒有可用的索引,那么 key 列 展示 NULL,possible_keys 是 NULL,這說明查詢到覆蓋索引。
?key_len 列
實(shí)際用的的索引使用的字節(jié)數(shù)。
注意,在聯(lián)合索引中,如果有 3 列,那么總字節(jié)是長(zhǎng)度是 100 個(gè)字節(jié)的話,那么 key_len 值數(shù)據(jù)可能少于 100 字節(jié),比如 30 個(gè)字節(jié),這就說明了查詢中并沒有使用聯(lián)合索引的所有列。而只是利用到某一些列或者 2 列。
key_len 的長(zhǎng)度是由表中的定義的字段長(zhǎng)度來計(jì)算的,并不是存儲(chǔ)的實(shí)際長(zhǎng)度,所以滿足數(shù)據(jù)最短的實(shí)際字段存儲(chǔ),因?yàn)闀?huì)直接影響到生成執(zhí)行計(jì)劃的生成 。
?ref 列
指出那些列或常量被用于索引查找
?rows 列
( 有 2 個(gè)含義)1、根據(jù)統(tǒng)計(jì)信息預(yù)估的掃描行數(shù)。
2、另一方面是關(guān)聯(lián)查詢內(nèi)嵌的次數(shù),每獲取匹配一個(gè)值都要對(duì)目標(biāo)表查詢,所以循環(huán)次數(shù)越多性能越差。
因?yàn)閽呙栊袛?shù)的值是預(yù)估的,所以并不準(zhǔn)確。
?filtered 列
表示返回結(jié)果的行數(shù)占需讀取行數(shù)的百分比。
filtered 列跟 rows 列是有關(guān)聯(lián)的,是返回預(yù)估符合條件的數(shù)據(jù)集,再去取的行的百分比。也是預(yù)估的值。數(shù)值越高查詢性能越好。
?Extra 列
包括了不適合在其他列中所顯示的額外信息。
值含義Distinct優(yōu)化 distinct 操作,在找到第一匹配的元組后即停止找同樣值得動(dòng)作Not exists使用 not exisits 來優(yōu)化查詢Using filesort使用文件來進(jìn)行排序,通常會(huì)出現(xiàn)在 order by 或 group by 查詢中Using index使用了覆蓋索引進(jìn)行查詢【查詢所需要的信息用所用來獲取,不需要對(duì)表進(jìn)行訪問】Using temporaryMySQL 需要使用臨時(shí)表來處理,常見于排序、子查詢和分組查詢Using where需要在 MySQL 服務(wù)器層使用 where 條件來過濾數(shù)據(jù)select tables optimized away直接通過索引來獲取數(shù)據(jù),不用訪問表
四、SQL 索引失效
?最左前綴原則:要求建立索引的一個(gè)列都不能缺失,否則會(huì)出現(xiàn)索引失效。
?索引列上的計(jì)算,函數(shù)、類型轉(zhuǎn)換(列類型是字符串在條件中需要使用引號(hào),否則不走索引)、均會(huì)導(dǎo)致索引失效。
?索引列中使用 is not null 會(huì)導(dǎo)致索引列失效。
?索引列中使用 like 查詢的前以 % 開頭會(huì)導(dǎo)致索引列失效。
?索引列用 or 連接時(shí)會(huì)導(dǎo)致索引失效。
五、實(shí)際優(yōu)化慢 SQL 中遇到問題
下面是在慢 SQL 優(yōu)化過程中所遇到的一些問題。
•MySQL 查詢到的數(shù)據(jù)排序是穩(wěn)定的么?
•force_index 的使用方式?
• 為什么有時(shí)候 order by id 會(huì)導(dǎo)致索引失效?
•........ 未完整理中......
六、總結(jié)
通過本次對(duì)慢 SQL 的優(yōu)化的需求進(jìn)而發(fā)現(xiàn)有關(guān) SQL 語句執(zhí)行順序、執(zhí)行計(jì)劃、索引失效場(chǎng)景、底層 SQL 語句執(zhí)行原理相關(guān)知識(shí)還存在盲區(qū),得益于此次需求的開發(fā),有深入的對(duì)相關(guān)知識(shí)進(jìn)行學(xué)習(xí)和總結(jié)。接下來會(huì)對(duì) SQL 底層是如何執(zhí)行 SQL 語句





