
近期,ChatGPT成為人工智能領域現象級熱點。這是由美國OpenAI公司發布的對話機器人,其“投人所好”的回答備受社會各領域關注,甚至產生是否意味人工智能新一輪技術革命、是否具備類人認知、是否演變為“強大而危險的AI”等一系列熱點爭議。
本文剖析ChatGPT的底層技術和演化路徑,總結認為其是近幾年不斷迭代的多種技術疊加而取得的重大成果,屬于重大的組合式創新,而也非根本性創新。同時,ChatGPT是人工智能生成內容(AIGC)的重要產品化應用,是工程化突破,將帶來數字內容生產方式和消費模式的升級,呈現新型虛實融合的數字文明。
一、ChatGPT歷史版本表現不及google BERT模型,堅持技術理想終于實現重要突破,未來Google相應的模型也值得期待
GPT和BERT是近幾年自然語言領域廣受關注的預訓練語言模型。其中,GPT-1由OpenAI于2018年6月發布,Bert是同年10月谷歌AI團隊推出。兩者都是基于Transformer模型架構(2017年6月谷歌團隊提出),但是GPT以生成式任務為目標,主要是完成語言生成,如聊天、寫作等,BERT模型更注重判斷決策,強調語言理解相關的任務,如問答、語義關系抽取等。
表GPT和Bert是兩類語言模型的典型代表
歷史版本上,GPT的模型效果弱于BERT,但OpenAI堅信生成式技術優勢并不斷迭代模型。雖然生成式模型的可控性差、訓練難度高,但OpenAI瞄準生成式模型的通用范式高、訓練過程更接近運用部署等技術應用優勢,始終堅持迭代部署。ChatGPT的研發過程是艱難曲折的,2018年6月發布GPT-1,而4個月后被谷歌的BERT模型全面超過;2019年2月發布GPT-2,整體效果仍不如BERT;2020年5月發布GPT-3,展現了“提升學習”這一新特點,生成效果離實際應用還有很大距離。事實上,業界對BERT模型認可度高,多數沿著“無監督訓練”和“下游任務微調”的研究范式開展開發,但OpenAI依舊堅持以生成式任務為目標,終于在2022年11月發布ChatGPT,產品十分驚艷,是有史以來最短時間用戶量突破1個億的應用。
二、ChatGPT疊加迭代多種技術,是組合式的迭代創新,也非根本性的理論創新
ChatGPT全稱為Chat Generative Pre-Trained Transformer,即聊天型生成式預訓練轉換模型,從算法分類上來講,它屬于生成式的大規模語言模型,其底層的技術,包括Transformer、有監督微調訓練、強化學習等,已在人工智能領域有廣泛的應用,并非算法上的實質性創新。ChatGPT巧妙地疊加這些技術,成功展現了由于模型規模帶來的突現能力,經過近幾年不斷迭代部署,量變的積累產生質變,形成了ChatGPT的語言智能。
本質上,ChatGPT是基于大規模語料訓練的生成式模型,相比于目前廣泛運用的判別式模型,它不局限于在已有的內容的判斷、預測(如人臉識別),而是進一步學習歸納后進行演繹,基于歷史進行模仿式創作,并生成合意的內容(如文本創作)。
具體來看,ChatGPT的訓練原理包含三個步驟,在大語言模型訓練基礎上,往復多次采用有監督的精調學習和基于人工反饋的強化學習,從而不斷加強ChatGPT模型的參數質量,實現模型對話能力關鍵性突破。
表ChatGPT訓練包含的三個步驟

注:PPO(Proximal Policy Optimization),是一種強化學習算法
三、ChatGPT的類人表現基于大量優質的數據語料訓練,實現對話意圖識別和內容生成能力的突破,但具體場景的通用性和魯棒性弱于工業界的判別類模型
在人工智能領域,ChatGPT是AI算法里程碑式的成果。根據ChatGPT的實際使用反饋,ChatGPT的躍遷式進步體現在——它的交互回答與人類意圖的一致性較高,更能“投人所好”,具體表現在它的“意圖理解能力強”并且“生成能力強”,尤其是在多輪對話下能夠領會人類的意圖,融合異構數據,產生有邏輯且多樣化的長文本,遠遠超過了目前其他AI語言模型的使用效果。
關于強大的對話能力,除了在“大模型、高算力、算法調優”方面的優勢外,數據側的整理、清洗、人工標注等工程化細節啟到了關鍵核心作用。ChatGPT的訓練語料主要來自Common Crawl、各類網頁、書籍及維基百科,而目前OpenAI公司并未公布更多數據處理和工程化過程,包括(1)數據篩選方法,如何在海量網頁文本進行數據的質量判斷和選取;(2)數據收集設置細節,如何確定網頁文本、代碼、公式和論文的比例,以用于第一步訓練大語言模型;(3)粗加工技術,例如對千億級tokens的編碼技術;(4)精加工技術,例如如何在第二步訓練中選擇和確定進行人工標注的1.5萬個問題。
由此,ChatGPT的知識來源于數據庫語料,回答的準確性以及是否合乎倫理道德都會受到訓練數據的影響,并且難以完成訓練數據庫以外的任務。
總的來說,GPT和BERT針對的任務和場景不同,但在各自方向中都有很好的表現,都是非常強大的語言模型,
四、ChatGPT進步的關鍵技術之一是基于人工反饋的強化學習,但 “強化學習”在工業界復活的判斷還為時過早
基于人工反饋的強化學習使ChatGPT的類人表現更進一步,但這并不意味著強化學習將立刻在工業界重新獲得廣泛運用。主要出于以下幾點原因:一是雖然OpenAI在強化學習上做了大量工作,但是強化學習的兩個應用核心痛點尚未有效解決:數據使用效率仍舊不高,強化學習仍有太多超參數需要調節;二是對于現在強化學習在ChatGPT中起到作用的相關效果評價還不夠完整,需要剔除僅由增加數據帶來的增益;三是強化學習模型的必要性仍需驗證,在增加第二步訓練中數據量的情況下,第三步訓練是否仍然必要,或是可以用更簡單直接的算法利用第三步中的增量標注數據去迭代優化原模型的參數,都還有待進一步驗證。
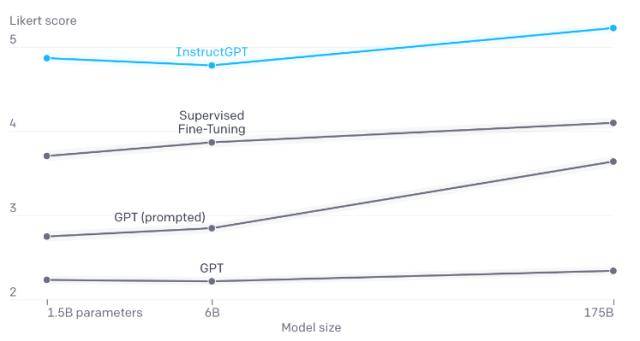
圖:各階段訓練在ChatGPT模型上產生的效果評價
圖表來源:openAI的官方博客
五、AI技術演化不會趨于單一化,而是“分久必合,合久必分”
人工智能技術作為數字時代新一輪科技革命和產業變革的重要戰略引擎,整體呈現“分久必合,合久必分”的動態上升趨勢。
從機器學習的模型訓練來講,目前經歷“有監督學習→自監督學習→有監督學習”的技術演變過程,也就是從“標注數據→海量無標注數據+大模型→高質量標注數據”,技術發展從追逐模型大小回歸到提升數據質量,這并不是全盤否定自監督學習的技術意義,簡單回歸機器學習的技術原點,而是技術的螺旋式上升過程。
從整個AIGC(人工智能生成內容)技術的發展來講,已經進入即分又合的時代。從開始“多頭并進”演變為“多點發力”,同時在“文本→文本”、“文本→圖片”、“文本→代碼”、“文本→聲音”、“文本→視頻”五個領域同時探索,但是共性關鍵技術有一致性,等于同一技術在同時做五個試驗,技術迭代成功率增加至五次方倍,所有這些方面的技術進步將助推AIGC技術的成熟,豐富人們的數字生活。
六、機器和未來人類的關系會出現重大轉變,且更加以人為中心
數字時代下,以ChatGPT為代表的人工智能生成內容(AIGC)將不斷革新數字內容的生產方式和消費模式,呈現人工智能強大的生產力變革效能。
首先是信息交互方式將發生重大改變,目前信息的交互以搜索引擎為主,ChatGPT將成為人工智能行業的基礎設施,帶來信息處理能力和內容生成能力的極大提升,致使文本理解、知識挖掘和表征、知識存儲和檢索等方面產生根本性的成本效率改善。
其次,人工智能行業將會發生生態顛覆,部分傳統人工智能產業將展現新的生命力,但同時部分行業也將面臨淘汰的威脅。智能客服將受到最為直接的影響,其靈活性和人性化服務能力顯著提升,在非深度專業服務方面能力接近于或超過真人客服,而且是所有公司都將會低成本普遍獲得的一種能力。相應地,對于垂直但領域的行業特性不強的公司,以及沒有數據和行業壁壘、僅提供通用文本處理能力的公司,都會受到降維打擊,例如“根據標題+關鍵詞生成營銷文案”、“郵件自動填寫”、“AI寫作助手”等。
由此,機器和未來人類的關系會出現重大轉變,ChatGPT將成為“大眾秘書”,提高人的生產效率,替代人的簡單重復性勞動,實現社會生產效率的提升。人工智能為廣泛社會群體快速實現“草稿準備”、“文字歸納”、“專家型知識獲取”等功能,并且專屬機器秘書像私人管家一樣,結合相關主體偏好,輔助形成個性化復雜決策建議。同時,技術發展將營造新的職業機會,人類的數字文明更進一步。
七、實現國產中文版仍存挑戰,數據量是關鍵要素,高質量的數據將是最大優勢
短期內,憑借市場力量即刻推出國產中文版ChatGPT仍存在不小挑戰。單就語種而言,中文語料訓練難度大,在數據質量上,中文網頁質量比英文網頁質量差很多,在訓練要求上,由于中國文化多樣性和悠久性,語言訓練難度較英文高,即使在目前在ChatGPT的語料庫里中文也僅占5%,ChatGPT在中文環境的交流效果遠弱于英文環境。
并且,國內主體短期攻關相關技術也需要一定時間。在人工智能技術方法論上,目前國內研究者多數依循谷歌的研究路徑,即“模型+算力+優化”,需要進行研究范式的轉變。在相關AI理論的攻關和參數的實驗上,也需要進行不斷的嘗試和經驗的積累,難以一蹴而就。
八、馬上消費乘ChatGPT之勢,鍛造沉浸式數智體驗
馬上消費持續研究并拓展人工智能生成內容(AIGC)的創新應用,在類ChatGPT技術上,取其算法要義精華,專注消費金融領域的模型精調,實現專業領域的AI內容生成,并成功為用戶提供豐富多樣的數字金融服務。
在大模型研究方面,公司聚焦垂直領域的專業化。自成立以來,馬上消費專設人工智能研究院,獲批建設國家級博士后科研工作站、國家應用數學中心、智慧金融與大數據分析重點實驗室等科研平臺。基于消費金融領域的專業知識,使用來自人類反饋的強化學習來訓練語言模型;在大模型控制方面,完善算法框架,實現在圈定的“常識+專業知識”上進行對話和推理;在大模型的學習能力方面,聚焦自問自答得遞歸加深理解功能,由機器人生成問題,并自行回答或搜索答案,最后根據這些自問自答生成最終答案。
同時,克服GPU的不足、經驗的欠缺,探索大小模型的‘精調訓練’和‘推理使用’的能力。大模型的訓練和應用離不開數據,馬上消費擁有超1.6億注冊用戶,構建完成高度自適的消費金融數據資產管理體系。在充分釋放自身數據要素價值的條件下,探索適應消費金融行業實際的大模型訓練與應用實際。設計基于公司數據的訓練“問答對”,既保留原有大語言模型的常識和通用推理能力,又獨有垂直細分數據上產生類似的能力擴展。公司在大模型應用主要是數據加工、模型優化、表征生成三個方面,結合大模型“超級打標員”技術對數據進行標注,并生成“偽數據”以加強下游任務訓練;將大模型作為母模型,蒸餾訓練出效果類似的小模型;利用大模型對內部文本生成更好的表征,這些表征可以用來做下游知識抽取,知識注入等。就目前的實踐成果來看,公司高度擬人的虛擬客服完成重復問題簡單快速處理,達到95%準確率、85%自助率,降低金融服務成本,提升了用戶體驗。
并且,基于“科技讓生活更美好”的愿景,公司積極推動人工智能生成內容(AIGC)標準的制定,從規范約束和風險監控兩個方面來保證機器智能生成內容的可信合規,助力內容生成產業高質量發展。
整體而言,馬上消費堅持在構建高可信數據資產體系的基礎上,不斷研發多模態、多場景、持續學習的類ChatGPT應用,為用戶鍛造沉浸式AI交互服務。
馬上消費金融股份有限公司副總經理兼首席信息官蔣寧
來源:金融界資訊





