
隨著移動互聯網技術的快速發展,在新業務、新領域、新場景的驅動下,基于傳統大型機的服務部署方式,不僅難以適應快速增長的業務需求,而且持續耗費高昂的成本,從而使得各大生產廠商以及企業只能望洋興嘆。此時,分布式系統的出現無疑給大家帶來了些許振奮。而后隨著大數據、區塊鏈技術以及云計算技術的蓬勃發展,將分布式系統推向新的高潮。
據不完全統計,截止目前,幾乎在全球的任何一家互聯網企業,無論規模大小,或多或少都有使用到分布式技術。基于不同的業務場景以及實現方案,有些可能注重計算,有些或許注重存儲。無論是基于具體哪種場景、模型,無不表明分布式系統在企業技術發展過程中的重要性以及必要性。
在本文中,我將主要圍繞 Etcd 這一個分布式 K-V 數據庫為主,探討一下分布式存儲技術的核心原理以及源碼實現。
首先,我們來了解下什么是Etcd ?
Etcd 是一個分布式的,一致的 Key-Value 存儲,主要用于共享配置和服務發現。Etcd由 CoreOS 開發并維護,通過 Raft 一致性算法處理日志復制以保證強一致性。Raft 是一個來自 Stanford 的新的一致性算法,適用于分布式系統的日志復制,Raft 通過選舉的方式來實現一致性,在 Raft 中,任何一個節點都可能成為 Leader。google 的容器集群管理系統Kubernetes、開源 PaaS 平臺 Cloud Foundry 以及 CoreOS 的 Fleet 均已廣泛使用Etcd。
正如上述所述,Etcd 是一個 K-V 存儲,其 Etcd Server 采用樹形的結構來組織儲存數據,類似 linux 的文件系統,其也具備目錄和文件的分層結構,我們稱之為 Nodes 。下面我們了解下 Etcd Key 的相關操作以及目錄情況,具體如下所示:
[administrator@JAVALangOutOfMemory ~ ]% Docker exec etcd /bin/sh -c "/usr/local/bin/etcd --version"
etcd Version: 3.3.8
Git SHA: 33245c6b5
Go Version: go1.9.7
Go OS/Arch: linux/amd64
[administrator@JavaLangOutOfMemory ~ ]% docker exec etcd /bin/sh -c "export ETCDCTL_API=3 ; /usr/local/bin/etcdctl endpoint health"
127.0.0.1:2379 is healthy: successfully committed proposal: took = 3.0925ms
[administrator@JavaLangOutOfMemory ~ ]% docker exec etcd /bin/sh -c "export ETCDCTL_API=3 ; /usr/local/bin/etcdctl put /luga/foo /luga/bar"
OK
[administrator@JavaLangOutOfMemory ~ ]% docker exec etcd /bin/sh -c "export ETCDCTL_API=3 ; /usr/local/bin/etcdctl get / --prefix "
/luga/foo
/luga/bar
基于上述的命令行操作,我們可以看出,當創建某個 Key 時,若不指定路徑,則默認創建到根目錄 “/” 下面,若指定目錄的話,則創建的 Key 位于所指定的目錄下。
我們現在了解下 Etcd 的架構,具體簡要架構如下圖所示:
基于上述架構圖,基于分層的形式,我們可以將 Etcd 分為以下4層,依次為表現層、網絡層、應用層、數據層。具體如下:
表現層
此層級主要包含相關命令行操作工具,以及 Restful 的 Api。客戶端可以通過命令行或者是 Restful Api 的方式與 Etcd 集群進行通信。
網絡層
此層級主要包含代理和 SDK ,ETCD 提供了基于三種協議的通信方式,分別為 HTTP、TCP以及 gRPC等。
應用層
應用層主要包含Raft協議、復制狀態機、多版本并發控、Watch、K-V 數據存儲、分布式事務等核心功能。強一致性算法的具體實現,是Etcd 的核心算法。
數據層
數據層主要涉及兩部分內容:一部分為內存數據,一部分為磁盤數據。其中內存中維護的數據主要是 Key 與 Revision 之間的 B-tree 索引。磁盤里面存儲的文件有三部分,一部分就是核心的數據文件,在 Snap下面的 db 文件中保存,還有就是 Raft 協議依賴的Wal 日志文件 和 Snap 快照文件。
針對架構圖中的關鍵組件進行簡要描述如下:
HTTP Server:接受客戶端發出的 API 請求以及其它 Etcd 節點的同步與心跳信息請求。
Store:用于處理 Etcd 支持的各類功能的事務,包括數據索引、節點狀態變更、監控與反饋、事件處理與執行等等,是 Etcd 對用戶提供的大多數 API 功能的具體實現。
Raft:強一致性算法的具體實現,是 Etcd 的核心算法。
WAL(Write Ahead Log,預寫式日志):是 Etcd 的數據存儲方式,Etcd 會在內存中儲存所有數據的狀態以及節點的索引,此外,Etcd 還會通過 WAL 進行持久化存儲。WAL 中,所有的數據提交前都會事先記錄日志。其中,Snapshot 是為了防止數據過多而進行的狀態快照;而 Entry 則表示存儲的具體日志內容。
通常情況下,一個完整的工作流主要涉及以下活動:一個用戶的請求發送過來,會經由 HTTP Server 轉發給 Store 進行具體的事務處理,如果涉及到節點數據的修改,則交給 Raft 模塊進行狀態的變更、日志的記錄,然后再同步給別的 Etcd 節點以確認數據提交,最后進行數據的提交,再次同步。
那么,Etcd 主要應用于哪些場景呢?
通過官網定義,Etcd 是一個高可用強一致性的鍵值數據庫在很多分布式系統架構中得到了廣泛的應用,其最經典的使用場景就是服務發現。那么有人問了,Zookeeper不香嗎?基于 Zookeeper 當前的業務使用場景,結合微服務體系及 云原生K8S 生態支持層面,綜合對比分析, Zookeeper 仍存在以下相關缺陷,具體如下:
1、復雜性,Zookeeper 基于Paxos 強一致性算法也以復雜難懂而聞名于世,除此之外,ZooKeeper 的使用也比較復雜,需要安裝客戶端,而且官方只提供了 Java 和 C 兩種語言的接口,其移植性及可擴展性有限。
2、生態發展滯后,無論是基于項目版本的更新還是所擁抱的生態,都表現的差強人意,尤其是在容器化生態中。
3、笨重,Zookeeper 基于Java 語言開發,面向企業級應用,故基于Java 生態體系時不時會引入大量的依賴,從而使得維護交往笨重。
相比較而言,Etcd 雖作為后起之秀,但其已經融入云原生生態領域,并且基于 Go 語言開發,高性能,基于 HTTP 作為接口使用簡單、方便,使用 Raft 算法保證強一致性讓用戶易于理解。除此,基于 Etcd 所默認的持久化機制與安全機制使得其在云原生生態領域能夠得到進一步的發展。
為什么 Etcd 在服務發現領域能夠獨占鰲頭呢?具體主要涉及以下:
1、強一致性、高可用。基于 Raft 算法的 Etcd 就是一個強一致性高可用的服務存儲目錄。
2、注冊服務和監控服務健康狀態的機制。用戶可以在 Eetcd 中注冊服務,并且對注冊的服務設置 key TTL,定時保持服務的心跳以達到監控健康狀態的效果。
3、查找和連接服務的機制。通過在 Etcd 指定的主題(由服務名稱構成的服務目錄)下注冊的服務也能在對應的主題下查找到。
那么,Etcd 如何保證數據一致性呢?
首先,Etcd 使用 Raft 協議來維護 Cluster 內各個 Nodes 狀態的一致性。也就是說,Etcd Cluster 是一個分布式系統,由多個 Nodes 相互通信構成整體對外服務,每個 Node 都存儲了完整的數據,并且通過 Raft 協議保證每個 Node 維護的數據是一致的。
其次,Etcd Cluster 中的每個 Node 都維護了一個狀態機,并且任意時刻,Cluster 中至多存在一個有效的主節點,即:Leader Node。由 Leader 處理所有來自客戶端寫操作,通過 Raft 協議保證寫操作對狀態機的改動會可靠的同步到其他 Follower Nodes。具體可參考下 Etcd 算法機制,如下所示:
基于數據一致性問題,分布式系統中常見的三種一致性模型:
1、強一致性:當更新操作在某個副本上執行成功后,之后所有的讀操作都要能夠獲得最新的數據。
2、弱一致性:當更新某數據時,用戶讀到最新的數據需要一段時間的延遲。
3、最終一致性:它是一種特殊的弱一致性,當某個數據更新后,在經過一個時間片段,所有后續的操作能夠獲得新數據,在這個時間片段內,數據可能是不一致的。
Raft 是分布式領域中的強一致性算法,當其中某個節點收到客戶端的一組指令時,它必須與其它節點溝通,以保證所有的節點以相同的順序收到相同的指令,最終所有的節點會產生一致的結果。
如何選舉 Leader 節點?
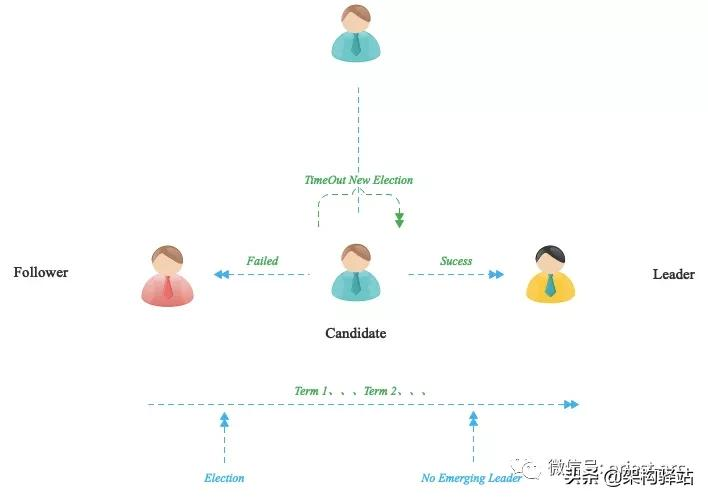
針對 Etcd ,Raft 通過『領導選舉機制』選舉出一個 Leader,由它全權管理日志復制來實現一致性。一個 Raft 集群包含若干個服務器節點,每一個節點都有一個唯一標識 ID,并且在任何時刻,每一個服務器節點都處于下面三個狀態之一:
1、Leader(領導人):Leader 處理所有的客戶端請求,在通常情況下,系統中只有一個Leader 并且其他節點都是 Follower。
2、Follower(跟隨者):Follower 不會發送任何請求,只是簡單地響應來自 Leader
Candidate 的請求,如果一個客戶端與 Follower 聯系,那么 Follower 會把請求重定向至 Leader。
3、Candidate(候選人):如果 Follower 接收不到來自 Leader 的消息,那么它就會變成 Candidate 并發起一次選舉,獲得集群中大多數選票(超過 n/2+1)的候選人將成為新的Leader。
假設 Etcd Cluster 中有 3 個 Node,Cluster 啟動之初并沒有被選舉出的 Leader。此時,Raft 算法使用隨機 Timer 來初始化 Leader 選舉流程。比如說上面 3 個 Node 上都運行了 Timer(每個 Timer 的持續時間是隨機的),而 Node1 率先完成了 Timer,隨后它就會向其他兩個 Node 發送成為 Leader 的請求,其他 Node 接收到請求后會以投票回應然后第一個節點被選舉為 Leader。成為 Leader 后,該 Node 會以固定時間間隔向其他 Node 發送通知,確保自己仍是 Leader。有些情況下當 Follower 們收不到 Leader 的通知后,比如說 Leader 節點宕機或者失去了連接,其他 Node 就會重復之前的選舉流程,重新選舉出新的 Leader。具體可參考如下所示:
針對如何判斷寫入是否成功?
Etcd 通常情況下默認為寫入請求被 Leader 處理并分發給了其他的 “多數節點” 后,就是一個成功的寫入。“多數節點” 的數量的計算公式是 Quorum=N/2+1,N 為總結點數。也就是說,Etcd 并發要將數據寫入所有節點才算一次寫,而是寫入 “多數節點” 即可。
最后,我們來看下如何確定 Etcd Cluster 的節點數?
基于多數節點的計算公式,可以簡單理解,Etcd Cluster 推薦最少節點數為 3 個,因為 1 和 2 個 Instance 的容錯節點數都是 0,一旦有一個節點宕掉整個集群就不能正常工作了。
進一步的講,當我們需要決定 Etcd Cluster 中 Instances 的數量時,強烈推薦奇數數量的節點,比如:3、5、7、…等,具體依據實際的業務場景進行決策。
因時間有限,源碼解析以及剩余的部分內容暫未在本文中詳述,后續將進行進一步的深入解析。





