
作者介紹
錢芳園,專注數據庫和數據庫自動化領域的工程師,擅長MySQL、redis運維以及基于Go語言的數據庫自動化開發。
一、背景
所謂 MySQL 慢查詢,是指在 MySQL 中執行時間超過指定閾值的語句將被記錄到慢查詢文件中,它是我們 DBA 經常討論的話題。
但在慢查詢方面,做得更多的工作,基本都是集中做一個慢查詢平臺,可以很好的把慢查詢收集起來,然后管理起來,方便查看各種信息,方便和開發溝通,方便看慢查詢的發展趨勢等等。但這些工作,對于解決慢查詢來講,作用比較小,因為久而久之,當我們成功地把慢查詢平臺變為慢查詢海洋時,不管是開發,還是 DBA ,都不知道我應該要去解決哪個慢查詢了,再加上,解決一個慢查詢,本身其周期非常長,比如涉及到發現慢查詢、分析并優化慢查詢、測試優化效果、修改業務代碼、發布上線以及觀察效果等等。這么長的流程,這么長的周期,很明顯給我們解決慢查詢造成了非常大的阻力。
慢查詢太多,對于業務而言,是有很大風險的,可能隨時都會因為某種原因而被觸發,并且根據我們的經驗,數據庫最常出現的問題,都是因為慢查詢導致數據庫慢了,進而導致整個實例雪崩,從而導致了線上故障。
從另外一個角度來考慮,解決慢查詢,是業務和 DBA 雙方面的問題,但通常情況下,業務并不關心自己使用的數據庫是不是有慢查詢,只關心數據庫是不是能返回正確的數據,對數據庫造成什么影響,并不太關注。而這個時候, DBA 只能去“被動接受”,并且只能是在問題出現之后,再去討論解決相應的問題。
可能有人會問,有慢查詢,難道 DBA 不知道嗎?為什么不提前解決,非要等到出了問題才解決,這個問題,就是本文今天的主題,我們如何把被動解決,變為主動。
二、分析
根據上面的背景講述,我們其實知道,為什么不能提前把問題發現并解決呢?主要原因是, DBA 面對慢查詢的海洋時,并不能有效地知道,每個慢查詢對業務影響的嚴重程度,再加上解決慢查詢的周期很長,可能針對一個慢查詢,從開始到解決完成,需要跟蹤半個月都不止,從而造成了慢查詢的被動解決,成為 DBA 內心的痛。
所以,其實最根本的原因是慢查詢太多,同時慢查詢沒有明確的優先級,不知道我們最先應該要解決哪個慢查詢,業務同學也是不知道的。雖然有平臺可查,但他們在面對大量的慢查詢時,解決的意愿就不是太高,最終慢查詢也越積來越多,直到最后影響業務運行。
所以,最有效的解決辦法就是,需要建立一種評分機制,將當前慢查詢系統中的慢查詢進行評分,按照分數給出優先級,然后根據優先級,將慢查詢信息推送給對應的業務方,要求他優先解決可能會對線上產生嚴重問題的慢查詢,再逐步解決次優先級的慢查詢,以此類推。
三、解決思路
通過建立一套評分的模型,給定任何一個慢查詢,根據慢查詢的關鍵屬性,計算出分數。假定總分數為100,分數越高則風險指數越高。
評分模型可以簡單描述為:
score=func(x)
四、設計模型
1、選取評分項
慢查詢主要因素是由查詢次數( QueryCount )和查詢其他各項指標(例如鎖等待時間、掃描行數、查詢時間、發送數據等)組成。
2、查詢次數
一個慢查詢如果執行時間為 1s ,查詢次數(QueryCount)為 1 和查詢次數為 1000 時,對系統的影響不同,次數越多危害越大,量變會引發質變。QueryCount 最正確的值是這個慢查詢當天執行的的最大執行次數。
但是預測未來并不可靠,對于線上業務沒有人會準確知道下一時刻的查詢次數會有多少,故我們使用昨天的數據,通過計算出單個時間窗口內的執行次數的最大值,來計算出這個慢查詢對當前系統的影響。單個時間窗口選取太小,比如 10s 、1min 等計算出來的 QueryCount 會太小,并不能清楚的反應指標的危害程度;如果選取太大,比如 30min,1hour 會造成計算出來的 QueryCount 太大,顯得指標的危害程度非常高。
故我們選取 10min 作為一個參考值,通過以 10min 為窗口,滑動計算出 QueryCount 的最大值,作為慢查詢評分模型的指標之一。
3、查詢其他各項指標
慢查詢各項因素主要是由慢查詢日志中記錄的各項指標。
mysql的慢查詢說明,慢查詢示例
# Time: 210818 9:54:25
# User@Host: fangyuan.qian[fangyuan.qian] @ [127.0.0.1] Id: 316538768
# Schema: Last_errno: 0 Killed: 0
# Query_time: 3.278988 Lock_time: 0.001516 Rows_sent: 284 Rows_examined: 1341 Rows_affected: 0
# Bytes_sent: 35600
SET timestamp=1629251665;
SELECT
a.ts_min AS slowlog_time,
a.checksum,
SUM(a.ts_cnt) AS d_ts_cnt,
ROUND(SUM(a.Query_time_sum), 2) AS d_query_time,
ROUND(SUM(a.Query_time_sum) / SUM(a.ts_cnt), 2) AS d_query_time_avg,
a.host_max AS host_ip,
a.db_max AS db_name,
a.user_max AS user_name,
b.first_seen AS first_seen_time
FROM mysql_slowlog_192_168_0_84_3306.query_history a force index(idx_ts_min),
mysql_slowlog_192_168_0_84_3306.query_review b
WHERE a.checksum = b.checksum
AND length(a.checksum)>=15
AND ts_min >= '2021-06-04'
AND ts_min < '2021-06-21'
GROUP BY a.checksum;
4、慢查詢字段說明
5、選取評分項
其中 Time、User@Host 、Id、Schema 、Last_errno 都是描述性的信息不會造成查詢變成慢查詢;
Query_time 是真實記錄慢查詢的查詢時間,查詢時間越長對系統的影響越大;
Lock_time 是當前查詢獲取數據時獲取記錄鎖而等待的時間,等待時間越長,越可能造成慢查詢;
Rows_sent 是發送多少行數據給 client ,同一個查詢語句發送的數據行數越大,越可能會造成慢查詢;
Rows_examined 是 server 層檢索的數據,檢索的數據越多,需要的IO和cpu資源也就越多,越可能造成慢查詢,并影響服務穩定性;
Rows_affected 只針對修改請求,由于絕大部分慢查詢都是 select ,并不會修改數據,故此值可以忽略;
Bytes_sent 是發送多少字節數據給 client ,發送的數據量越多,越可能會造成慢查詢;
由于不同的表行大小不同,并且并不是所有列都需要返回,所以一個發送 10 行的數據,可能會比一個發送 100 行數據的查詢更慢,Rows_sent 不如 Bytes_sent 更為直觀,故我們選取 Bytes_sent ,忽略 Rows_sent 。
所以,慢查詢指標中 Query_time、Lock_time 、 Bytes_sent 、 Rows_examined 作為慢查詢評分模型中的指標。
綜上所述,慢查詢評分項共有五項,分別是QueryCount、Query_time、Lock_time、Bytes_sent、Rows_examined。
評分模型可以簡單描述為:
score=sum(評分項*權重)
6、選取評分項邊界
評分模型的評分項確認之后,為了防止單項分數過高,需要對評分項進行百分化,并且所有權重總和為 100 ,根據評分項計分模型可以算出符合增長曲線的分數,這樣評分模型計算出來的總分數為 100 ,故需要確認每項的分數邊界、權重、計分模型。
只有各項的邊界、權重、計分模型確認之后,給定一個慢查詢,評分模型才能計算出合理的分數。評分項的邊界可以根據當前歷史數據設置。計分模型和權重可以首先進行假設,測試完成之后如果不符合預期則修改權重、計分模型,并重復測試-修改過程,直至測試結果符合預期。
7、邊界選取標準
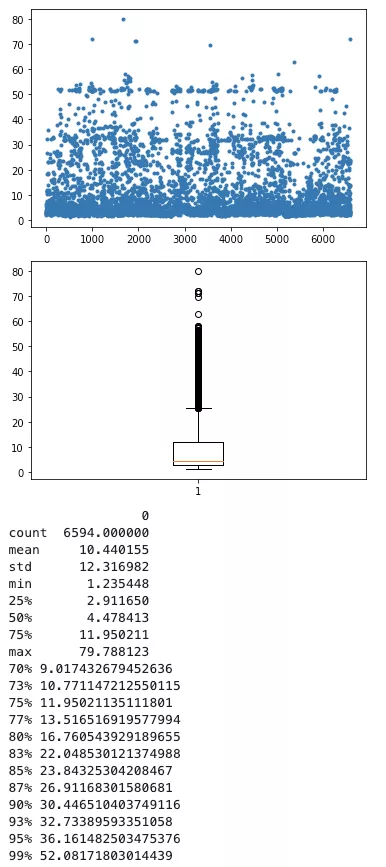
根據當前慢查詢的歷時記錄,由于極值數據可能會存在干擾,導致真實值失真,故需要去除最高部分 5% 的異常值,將 95 分位的值作為每個評分項的最高邊界。如果單項值超過最高邊界的值評分項,單項分數都將被設置為最大分數。
8、查詢時間
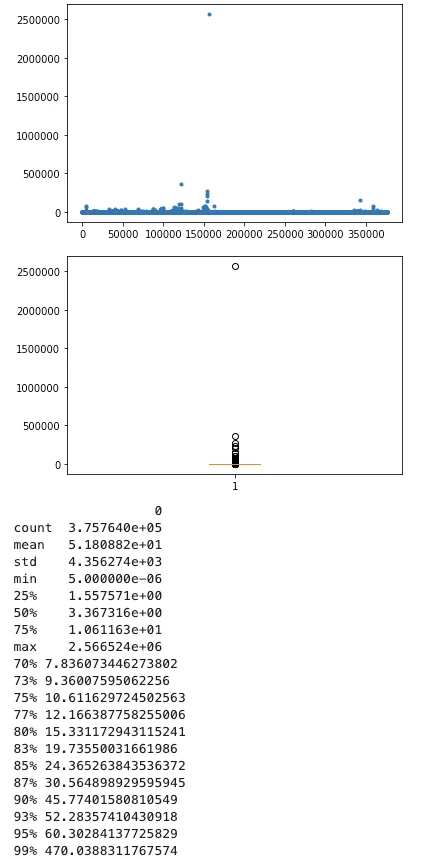
95 分位的 sql 慢查詢耗時約在 60s 左右
9、鎖等待時間
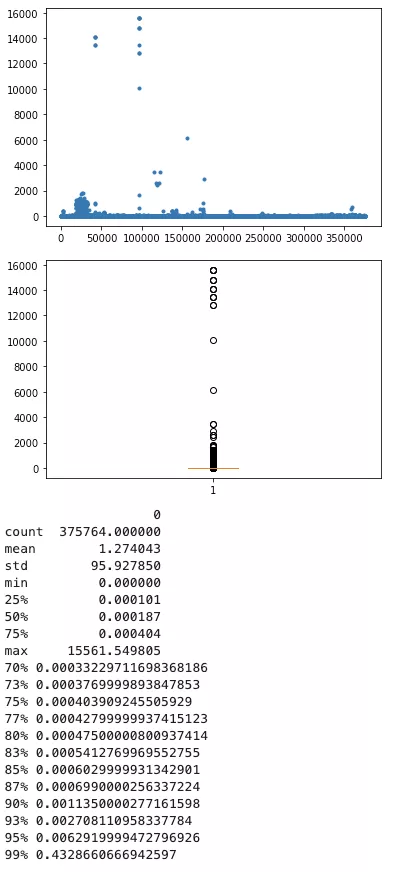
95分位的慢查詢鎖等待時間約為0.00629s
10、掃描行數
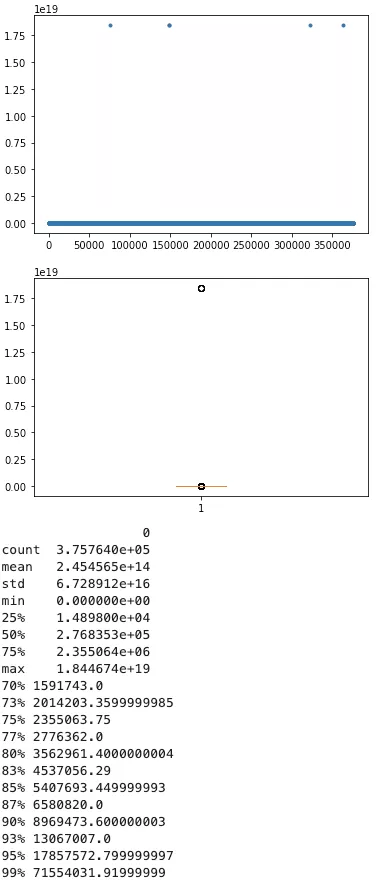
95分位的慢查詢掃描行數約為1785w行
11、查詢次數
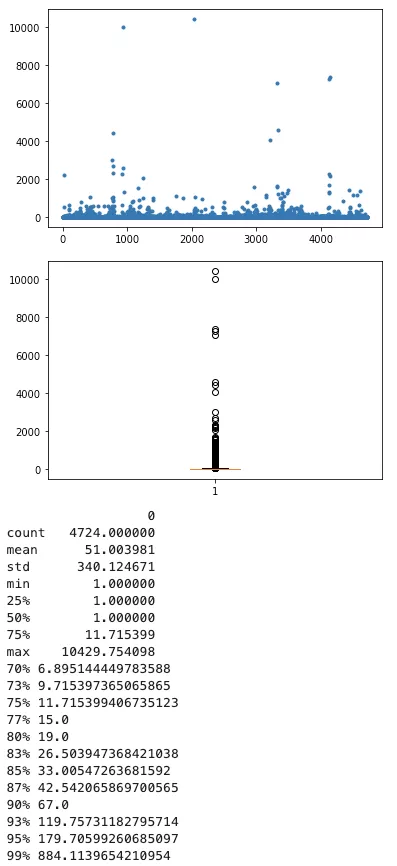
95分位的慢查詢次數約為180個
12、發送流量
由于流量字段缺失,暫時不計入評分系統。
13、計分項邊界值
14、計分模型
每一項計分項的邊界得以確認,值越大分數越高。但是存在以下情況:
某些評分項的值對系統的影響程度并不是成正比例,超過某個臨界點,對系統的壓力會迅速增長。
比如:查詢次數,一條超時為1s的sql,查詢1次、查詢10次、查詢100次,對系統的壓力是不一樣的,量變會引發質變。
設計有一下四種計分模型:
計分代碼如下:
/**
* @Description: 計算單項得分,分數介于最小分數和最大分數之間,可選的計分模型有:類正弦模型、正弦模型、指數模型、正比例模型
* @Param val: 單項當前值
* @Param minVal: 單項最小值
* @Param maxVal: 單項最大值
* @Param minScore: 單項最小得分
* @Param maxScore: 單項最大得分
* @Param calWay: 計分模型方式
* @Return float64: 單項得分
*/
func calSingleScore(val, minVal, maxVal, minScore, maxScore float64, calWay string) float64 {
if maxVal == 0 { // 如果值為0則返回0
return 0
}
if val >= maxVal { // 如果值超過上邊界,則設置為最大分數
return maxScore
}
if val <= minVal { // 如果值低于下邊界,則設置為最小分數
return minScore
}
var scoreRatio float64
switch calWay {
case "likeSin": // 類正弦曲線
// Y = a + b·X + c·X2 + d·X3 + e·X4 + f·X5
b := 0.0547372760360247
c := -0.0231045458864445
d := 0.00455283203705563
e := -0.000281663561505204
f := 5.57101673606083e-06
// 使用20個函數繪制點位擬合出來的
ratio := (val - minVal) / (maxVal - minVal) * 20
scoreRatio = b*ratio + c*(ratio*ratio) + d*(ratio*ratio*ratio) +
e*(ratio*ratio*ratio*ratio) + f*(ratio*ratio*ratio*ratio*ratio)
case "sin": // 正弦曲線
ratio := (val - minVal) / (maxVal - minVal)
scoreRatio = math.Sin(math.Pi / 2 * ratio)
case "exponent": // 指數曲線
ratio := (val - minVal) / (maxVal - minVal)
a := math.Log2(maxScore - minScore)
scoreRatio = math.Pow(2, a*ratio)
return scoreRatio
default: // 默認是正比例
scoreRatio = (val - minVal) / (maxVal - minVal)
}
return scoreRatio * (maxScore - minScore)
}
模型曲線如下:
我們期望某些計分項在各個不同的階段對分數的影響是不一樣的,故首先假設計分模型和權重如下:
整體的評分模型如下:
慢查詢風險指數 = sum(func(慢查詢評分項) * 權重)
ps:風險指數總分數上限為100
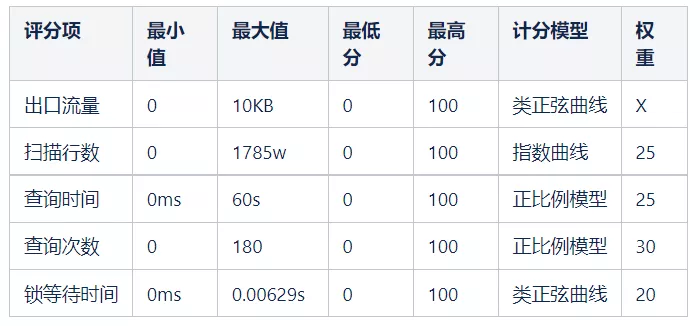
五、測試
1、測試一
1)權重分配
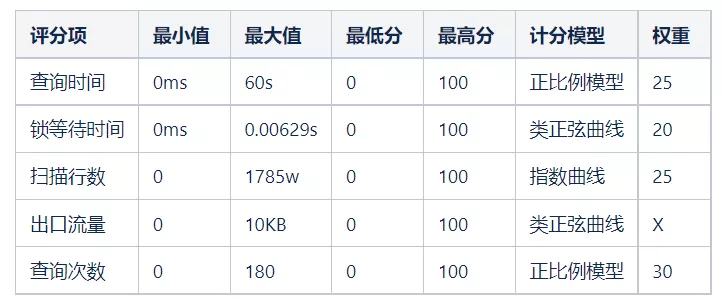
2)計算結果數據分布
3)樣本SQL分析
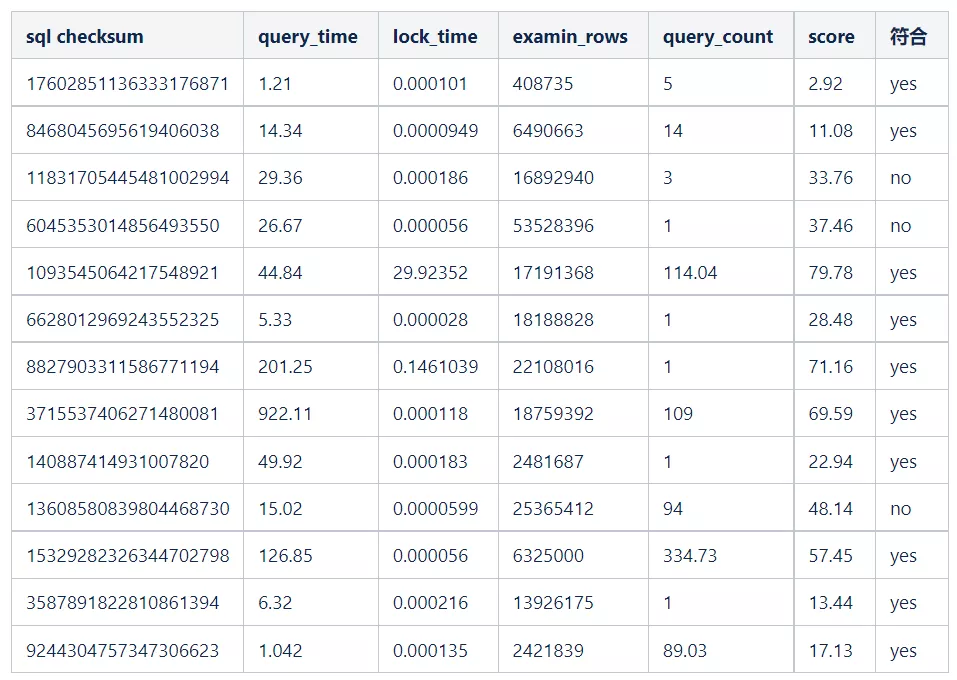
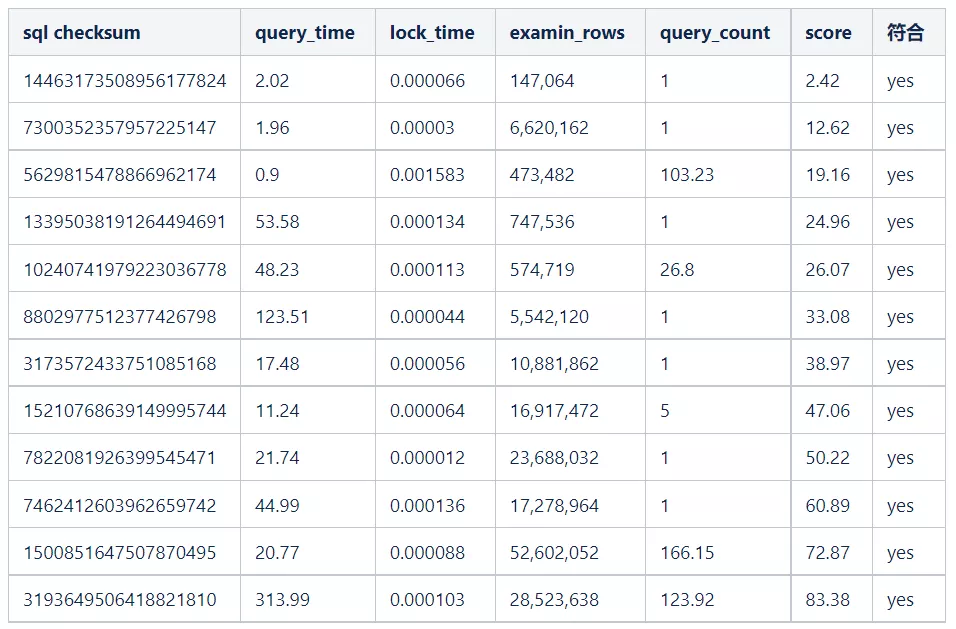
不符合的原因:掃描行數越多對系統的影響越大,所需要的 IO 和 CPU 資源也就越多,系統處于無響應狀態的幾率越大,其影響比例應該要遠高于其他評分項。我們期望掃描行數越多,分值越高,越需要關注,故需要調整各個評分項權重和計分模型。
2、測試二
1)權重分配
重新分片權重并修改計分模型之后,整體模型如下:
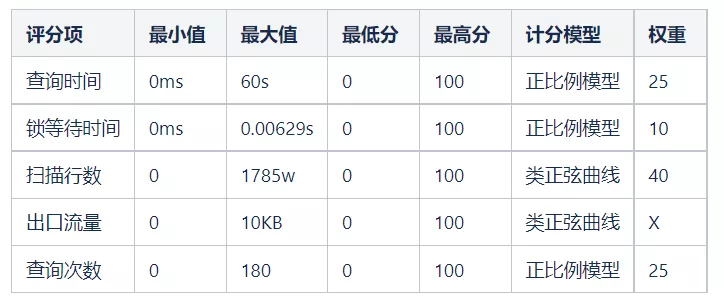
2)計算結果數據分布
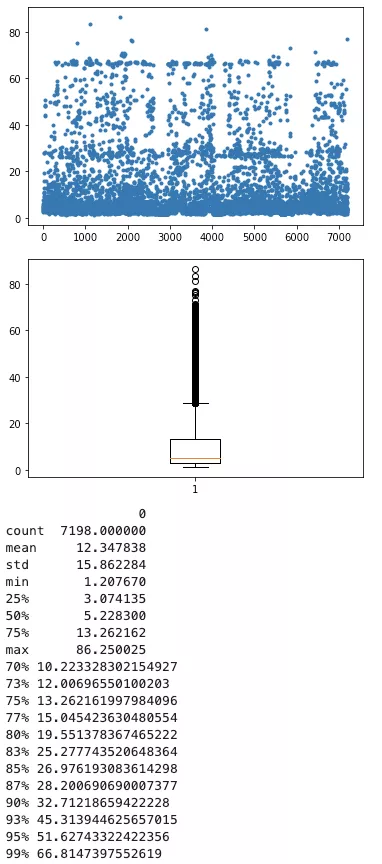
3)樣本sql分析
六、結論
評分模型
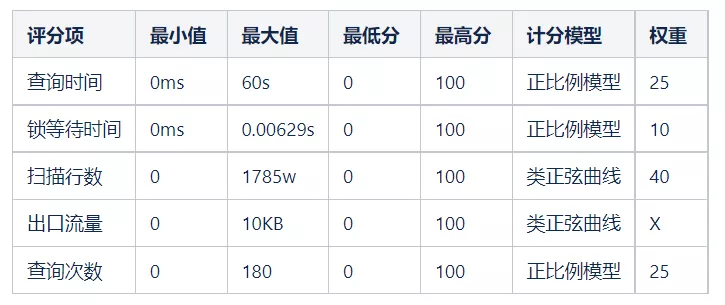
采用權重分配二,需要重點關注所有分數為50以上的慢查詢。
七、展望
1、更合理的評分模型
percona sever/mariadb 版本的mysql可以有更豐富的統計項
percona server/mariadb的慢查詢示例
# Time: 210818 9:54:57
# User@Host: fangyuan.qian[fangyuan.qian] @ [127.0.0.1] Id: 316541341
# Schema: Last_errno: 0 Killed: 0
# Query_time: 2.777965 Lock_time: 0.000289 Rows_sent: 284 Rows_examined: 1341 Rows_affected: 0
# Bytes_sent: 35600 Tmp_tables: 1 Tmp_disk_tables: 0 Tmp_table_sizes: 1044920
# InnoDB_trx_id: 52AFB919
# QC_Hit: No Full_scan: Yes Full_join: No Tmp_table: Yes Tmp_table_on_disk: No
# Filesort: Yes Filesort_on_disk: No Merge_passes: 0
# InnoDB_IO_r_ops: 0 InnoDB_IO_r_bytes: 0 InnoDB_IO_r_wait: 0.000000
# InnoDB_rec_lock_wait: 0.000000 InnoDB_queue_wait: 0.000107
# InnoDB_pages_distinct: 1862
SET timestamp=1629251697;
SELECT
a.ts_min AS slowlog_time,
a.checksum,
SUM(a.ts_cnt) AS d_ts_cnt,
ROUND(SUM(a.Query_time_sum), 2) AS d_query_time,
ROUND(SUM(a.Query_time_sum) / SUM(a.ts_cnt), 2) AS d_query_time_avg,
a.host_max AS host_ip,
a.db_max AS db_name,
a.user_max AS user_name,
b.first_seen AS first_seen_time
FROM mysql_slowlog_192_168_0_84_3306.query_history a force index(idx_ts_min),
mysql_slowlog_192_168_0_84_3306.query_review b
WHERE a.checksum = b.checksum
AND length(a.checksum)>=15
AND ts_min >= '2021-06-04'
AND ts_min < '2021-06-21'
GROUP BY a.checksum;
未來可以將更多的指標納入評分模型,評分維度會更多,模型也會更精確,慢查詢風險指數也會更合理。
2、與業務相結合
針對不同的業務,需要關注的慢查詢風險指數也應該是不一樣的,核心業務的慢查詢風險指數應該比較低。不同的業務之間慢查詢風險指數相同的其表示的影響程度也不一定相同。
故引入一個「業務等級權重」,目的是將所有業務的慢查詢風險指數量化為同一個標準。高優先級的業務其「業務等級權重」也會越高,低優先級的業務其「業務等級權重」也會越低。按照AppCode維度,將每個appCode的慢查詢TopN發送給業務方,指數越高業務應該越優先處理。同時需要設置慢查詢平臺的「慢查詢風險安全指數」水位線,超過這個水位線的所有慢查詢都需要關注。
最終慢查詢風險指數 = 慢查詢風險指數 * 業務等級權重
八、總結
通過我們的慢查詢分級模型,可以很好的把一個慢查詢抽象化為一個具體的數字,將其數字化,給我們的運維帶來了非常大的便捷性,這個數字,我們可以稱之為“慢查詢業務風險指數”。
有了數字化慢查詢,我們就可以很好地去界定一個慢查詢是不是真的有風險,或者風險有多大,這樣就可以以上帝視角的方式,來管理所有的慢查詢, 這樣自上而下地去解決問題,相比讓DBA整天盯著一個個具體的慢查詢去解決的話,效率會非常高。
根據我們抽象化出來的風險指數(慢查詢業務風險指數),我們可以按照一定的周期,將風險大的慢查詢,推送給對應的具體的負責人,然后不斷地解決,不斷地迭代,最終實現解決慢查詢從“被動”到“主動”的完美轉換。
我們最終的目標是,讓所有慢查詢的風險指數的中位數,或者90%、70%分位數,不斷地下降,最終處于一個良性的狀態。
作者丨去哪兒網DBA團隊
來源丨公眾號:Qunar技術沙龍(ID:QunarTL)
dbaplus社群歡迎廣大技術人員投稿,投稿郵箱:[email protected]
關注公眾號【dbaplus社群】,獲取更多原創技術文章和精選工具下載





