擊這里在線咨詢客服")
語(yǔ)音識(shí)別的研究歷史悠久,出現(xiàn)了許多著名的算法和工具。從事語(yǔ)音算法工作兩年期間,我在語(yǔ)音識(shí)別方向做了一點(diǎn)工作,對(duì)此有一些體會(huì)。面對(duì)諸多的算法如何學(xué)習(xí)掌握呢?我認(rèn)為一個(gè)不錯(cuò)的方法是歸納不同算法的異同,形成體系。由于個(gè)人的知識(shí)有限,這里說(shuō)的歸納也是不完全的歸納。但我相信,隨著知識(shí)面不斷拓展,個(gè)人的認(rèn)知會(huì)逐漸從偏到全。
本文主要討論如何從 ASR 的原始的優(yōu)化目標(biāo)出發(fā),以一個(gè)較為統(tǒng)一的視角看待傳統(tǒng) ASR 算法和端到端 ASR 算法,各類算法的具體實(shí)現(xiàn)和訓(xùn)練優(yōu)化留到以后文章再討論。現(xiàn)代成熟的語(yǔ)音識(shí)別系統(tǒng)包含音頻采集、前處理、識(shí)別、后處理等模塊,本文關(guān)注的也僅僅是識(shí)別模塊。

語(yǔ)音識(shí)別 pipeline, 本文關(guān)注點(diǎn)在于 ASR Model
本文目錄
1. 語(yǔ)音識(shí)別問(wèn)題形式化
2. 傳統(tǒng) ASR 算法原理
2.1 動(dòng)態(tài)展開(kāi)的解碼
2.2 引入 WFST 的靜態(tài)圖解碼
2.3 聲學(xué)模型
2.3.1 基于 HMM 的聲學(xué)模型
2.3.2 基于 CTC 的聲學(xué)模型
2.4 語(yǔ)言模型
3. 端到端 ASR 算法原理
3.1 CTC-based E2E Models
3.2 RNN-Transducer、RNA、Neural Transducer 等
3.3 Attention-based E2E Models
3.4 引入了 WFST 的端到端算法
3.5 拓展思考
4. 總結(jié)
5. 參考資料
1. 語(yǔ)音識(shí)別問(wèn)題形式化
語(yǔ)音識(shí)別可以看做是語(yǔ)音內(nèi)容理解的一個(gè)子任務(wù),目的是獲取一段語(yǔ)音中包含的文本內(nèi)容。可以這樣定義語(yǔ)音識(shí)別:根據(jù)特征幀序列 ,窮舉所有可能的 Token 序列
,窮舉所有可能的 Token 序列 , 獲取后驗(yàn)概率最大的序列
, 獲取后驗(yàn)概率最大的序列 , 即
, 即

我們常會(huì)以 字(Char) 或 詞(word)來(lái)作為 Token,此時(shí) 表示字序列或詞序列,
表示字序列或詞序列, 表示所有可能的 Token 序列。
表示所有可能的 Token 序列。
語(yǔ)音識(shí)別也可以看成是一個(gè)搜索任務(wù),搜索的排序準(zhǔn)則是序列后驗(yàn)概率最大,這樣一個(gè)搜索過(guò)程我們稱之為 ASR 的解碼。
2. 傳統(tǒng) ASR 算法原理
傳統(tǒng) ASR 算法基于 Bayes 法則,將后驗(yàn)概率的求解分解成先驗(yàn)概率和修正系數(shù)(似然概率)的形式,從而將 ASR 系統(tǒng)模塊化,并且引入了 WFST 來(lái)簡(jiǎn)化各模塊的實(shí)現(xiàn)。
根據(jù) Bayes 公式,
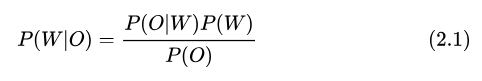
而求最優(yōu)  過(guò)程與
過(guò)程與  無(wú)關(guān),因此有
無(wú)關(guān),因此有
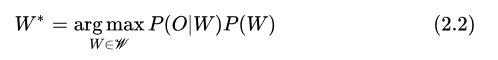
在傳統(tǒng) ASR 算法中, 建模似然概率 的模型稱為聲學(xué)模型,先驗(yàn)概率
的模型稱為聲學(xué)模型,先驗(yàn)概率  則由語(yǔ)言模型建模。為了讓系統(tǒng)更加模塊化,可以進(jìn)一步細(xì)化建模單元為音節(jié)/音素。此時(shí)需要增加詞典模型來(lái)建模
則由語(yǔ)言模型建模。為了讓系統(tǒng)更加模塊化,可以進(jìn)一步細(xì)化建模單元為音節(jié)/音素。此時(shí)需要增加詞典模型來(lái)建模  ,優(yōu)化目標(biāo)轉(zhuǎn)化為:
,優(yōu)化目標(biāo)轉(zhuǎn)化為:
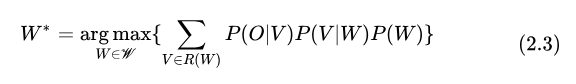
其中  表示序列
表示序列  的所有可能發(fā)音序列。在工程實(shí)現(xiàn)上,我們可以用最大概率的一個(gè)發(fā)音序列來(lái)近似上式,并取 log,即
的所有可能發(fā)音序列。在工程實(shí)現(xiàn)上,我們可以用最大概率的一個(gè)發(fā)音序列來(lái)近似上式,并取 log,即
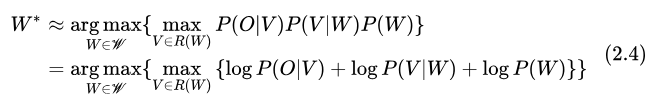
2.1 動(dòng)態(tài)展開(kāi)的解碼
上式的一種窮舉方法是分步驟求解,對(duì)于每個(gè)序列  ,根據(jù)語(yǔ)言模型求
,根據(jù)語(yǔ)言模型求  ,然后根據(jù)詞典模型求最大概率的序列
,然后根據(jù)詞典模型求最大概率的序列  的得分
的得分 ,再聲學(xué)模型得到該發(fā)音序列
,再聲學(xué)模型得到該發(fā)音序列  的聲學(xué)得分
的聲學(xué)得分  ,匯總得分后取得分最高的一個(gè)序列即為
,匯總得分后取得分最高的一個(gè)序列即為  。
。
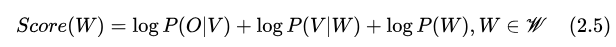
另一種窮舉方式是遍歷每一個(gè)發(fā)音序列  ,先根據(jù)聲學(xué)模型計(jì)算聲學(xué)得分
,先根據(jù)聲學(xué)模型計(jì)算聲學(xué)得分  ,然后獲取發(fā)音對(duì)應(yīng)的 Token 序列與得分
,然后獲取發(fā)音對(duì)應(yīng)的 Token 序列與得分  ,最后每個(gè)序列得分
,最后每個(gè)序列得分  。
。
我們剛才說(shuō)到,這里聲學(xué)模型的建模單元是發(fā)音,因此也相當(dāng)于額外假設(shè)了每一幀輸入  可以描述一個(gè)發(fā)音
可以描述一個(gè)發(fā)音  ,但是對(duì)于每一個(gè)Token
,但是對(duì)于每一個(gè)Token  ,需要多幀
,需要多幀  才能描述,并且每個(gè)人再說(shuō)同一個(gè)字詞的時(shí)候語(yǔ)速都不一樣,因此這個(gè)長(zhǎng)度
才能描述,并且每個(gè)人再說(shuō)同一個(gè)字詞的時(shí)候語(yǔ)速都不一樣,因此這個(gè)長(zhǎng)度  無(wú)法確定,第一種窮舉方式在連續(xù)語(yǔ)音識(shí)別實(shí)現(xiàn)起來(lái)過(guò)于復(fù)雜,幾乎是不可行的,只有在孤立詞、關(guān)鍵詞檢測(cè)等
無(wú)法確定,第一種窮舉方式在連續(xù)語(yǔ)音識(shí)別實(shí)現(xiàn)起來(lái)過(guò)于復(fù)雜,幾乎是不可行的,只有在孤立詞、關(guān)鍵詞檢測(cè)等  長(zhǎng)度固定、數(shù)量有限的任務(wù)里還可以考慮考慮這種方法。
長(zhǎng)度固定、數(shù)量有限的任務(wù)里還可以考慮考慮這種方法。
在傳統(tǒng) ASR 算法里用的是第二種窮舉方法。由于輸入序列  是按時(shí)間逐個(gè)輸入的,隨著
是按時(shí)間逐個(gè)輸入的,隨著  的不斷輸入,我們保留的中間結(jié)果也逐漸增多,相關(guān)的
的不斷輸入,我們保留的中間結(jié)果也逐漸增多,相關(guān)的  序列不斷地進(jìn)行樹(shù)狀擴(kuò)展,因此這種遍歷方式可以稱之為動(dòng)態(tài)展開(kāi)的解碼。需要注意的是窮舉的方式,暴力窮舉的復(fù)雜度是指數(shù)級(jí)。幸好在 ASR 的解碼過(guò)程中,當(dāng)前時(shí)刻的結(jié)果可以認(rèn)為只和之前時(shí)刻相關(guān),可以通過(guò)動(dòng)態(tài)規(guī)劃的方式來(lái)窮舉,可以把時(shí)間復(fù)雜度降低到多項(xiàng)式級(jí)別。
序列不斷地進(jìn)行樹(shù)狀擴(kuò)展,因此這種遍歷方式可以稱之為動(dòng)態(tài)展開(kāi)的解碼。需要注意的是窮舉的方式,暴力窮舉的復(fù)雜度是指數(shù)級(jí)。幸好在 ASR 的解碼過(guò)程中,當(dāng)前時(shí)刻的結(jié)果可以認(rèn)為只和之前時(shí)刻相關(guān),可以通過(guò)動(dòng)態(tài)規(guī)劃的方式來(lái)窮舉,可以把時(shí)間復(fù)雜度降低到多項(xiàng)式級(jí)別。
2.2 引入 WFST 的靜態(tài)圖解碼
是否可以進(jìn)一步簡(jiǎn)化、優(yōu)化上述的解碼過(guò)程呢?我們的前輩引入了一個(gè)相當(dāng)高級(jí)的工具:加權(quán)有限狀態(tài)轉(zhuǎn)換機(jī)(Weighted Finite-State Transducer, WFST)[1]。我們把要優(yōu)化的目標(biāo)函數(shù)做一點(diǎn)修改,
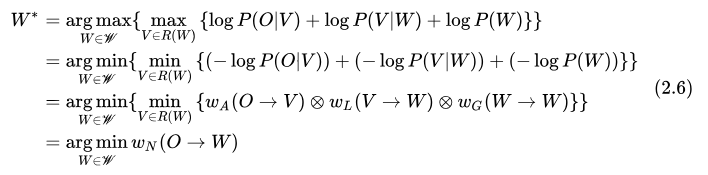
可以看到, WFST 視角下的 ASR 是一個(gè)從輸入音頻特征幀序列  到詞序列
到詞序列  的一個(gè)轉(zhuǎn)換任務(wù)。ASR 系統(tǒng)中的每一個(gè)模塊可以用不同的 WFST 來(lái)表示,其信息可以編碼到 WFST 的跳轉(zhuǎn)弧上。聲學(xué)模型對(duì)應(yīng)的 WFST 把聲學(xué)模型建模單元的 id 序列轉(zhuǎn)化為對(duì)應(yīng)的發(fā)音序列
的一個(gè)轉(zhuǎn)換任務(wù)。ASR 系統(tǒng)中的每一個(gè)模塊可以用不同的 WFST 來(lái)表示,其信息可以編碼到 WFST 的跳轉(zhuǎn)弧上。聲學(xué)模型對(duì)應(yīng)的 WFST 把聲學(xué)模型建模單元的 id 序列轉(zhuǎn)化為對(duì)應(yīng)的發(fā)音序列  ,得分用跳轉(zhuǎn)弧權(quán)重表示
,得分用跳轉(zhuǎn)弧權(quán)重表示  。詞典模型對(duì)應(yīng)的 WFST 把發(fā)音單元 id 序列轉(zhuǎn)化為 Token 序列,
。詞典模型對(duì)應(yīng)的 WFST 把發(fā)音單元 id 序列轉(zhuǎn)化為 Token 序列,  。語(yǔ)言模型對(duì)應(yīng)的 WFST 主要編碼詞序列的語(yǔ)言得分,
。語(yǔ)言模型對(duì)應(yīng)的 WFST 主要編碼詞序列的語(yǔ)言得分,  。
。
之前說(shuō)的幾個(gè)模塊動(dòng)態(tài)展開(kāi)的窮舉,通過(guò) WFST 的合并操作(Compose)可以簡(jiǎn)化為單一的 WFST 的靜態(tài)圖搜索,可以說(shuō)在很大程度上簡(jiǎn)化了 ASR 的解碼。同時(shí),運(yùn)用 WFST 的一些優(yōu)化操作,可以優(yōu)化搜索路徑,讓這個(gè)搜索過(guò)程效率更高。
實(shí)際上這里 代表描述了聲學(xué)模型得分、聲學(xué)建模單元與發(fā)音之間的關(guān)聯(lián),如果采用 HMM 聲學(xué)模型則
代表描述了聲學(xué)模型得分、聲學(xué)建模單元與發(fā)音之間的關(guān)聯(lián),如果采用 HMM 聲學(xué)模型則 ,如果采用 CTC-based 聲學(xué)模型,則
,如果采用 CTC-based 聲學(xué)模型,則 。其中
。其中 和
和 編碼的都只是聲學(xué)建模單元與發(fā)音之間的關(guān)聯(lián)。
編碼的都只是聲學(xué)建模單元與發(fā)音之間的關(guān)聯(lián)。
那  中的聲學(xué)得分在哪呢?在解碼過(guò)程中,
中的聲學(xué)得分在哪呢?在解碼過(guò)程中,  (在 kaldi 中以 Lattice 形式存儲(chǔ))的跳轉(zhuǎn)弧權(quán)重包含兩個(gè)值,一個(gè)是預(yù)留的"聲學(xué)得分" acoustic_cost,由聲學(xué)模型計(jì)算并動(dòng)態(tài)賦值。另一個(gè)是由詞典得分、語(yǔ)言得分經(jīng)過(guò) FST Compose 之后合并成了靜態(tài)的"圖得分" graph_cost。
(在 kaldi 中以 Lattice 形式存儲(chǔ))的跳轉(zhuǎn)弧權(quán)重包含兩個(gè)值,一個(gè)是預(yù)留的"聲學(xué)得分" acoustic_cost,由聲學(xué)模型計(jì)算并動(dòng)態(tài)賦值。另一個(gè)是由詞典得分、語(yǔ)言得分經(jīng)過(guò) FST Compose 之后合并成了靜態(tài)的"圖得分" graph_cost。
2.3 聲學(xué)模型
2.3.1 基于 HMM 的聲學(xué)模型
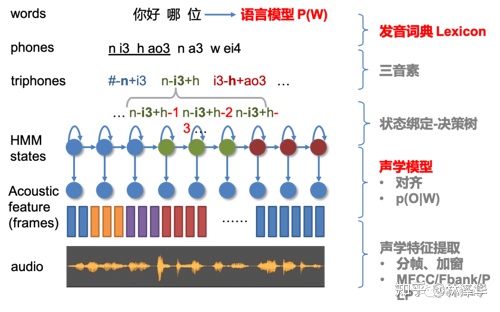
目前 kaldi [14] 是采用隱馬爾可夫模型(HMM)[2] 來(lái)實(shí)現(xiàn)聲學(xué)模型,并且 kaldi 的聲學(xué)模型建模的是比音素更細(xì)粒度的單元,即 HMM 狀態(tài)。不同音素可以用不同的 HMM 來(lái)描述,每一個(gè) HMM 都包含指定數(shù)量的狀態(tài)。采用 HMM 作為聲學(xué)模型,對(duì)于某一個(gè)觀測(cè)序列  ,其似然概率的計(jì)算方式為:
,其似然概率的計(jì)算方式為:
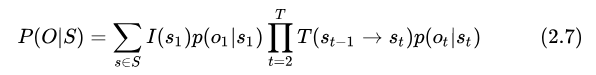
其中  表示 HMM 拓?fù)渲兴锌赡艿臓顟B(tài)序列,
表示 HMM 拓?fù)渲兴锌赡艿臓顟B(tài)序列,  表示以
表示以  為初始狀態(tài)的概率,
為初始狀態(tài)的概率,  表示從狀態(tài)
表示從狀態(tài)  到狀態(tài)
到狀態(tài)  的轉(zhuǎn)移概率,
的轉(zhuǎn)移概率,  為狀態(tài) 發(fā)射概率。
為狀態(tài) 發(fā)射概率。
此時(shí) ASR 總的優(yōu)化目標(biāo)可以表示為
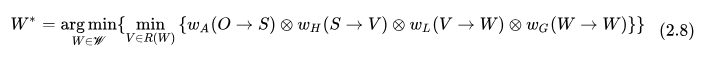
其中,狀態(tài)之間的跳轉(zhuǎn)關(guān)系通過(guò) WFST 表示,也就是  ,初始概率、轉(zhuǎn)移概率以權(quán)重編碼在跳轉(zhuǎn)弧上,最終成為圖得分 graph_cost 的一部分。
,初始概率、轉(zhuǎn)移概率以權(quán)重編碼在跳轉(zhuǎn)弧上,最終成為圖得分 graph_cost 的一部分。
我們通常看到的 GMM-HMM、DNN-HMM 里的 GMM、DNN 建模的是發(fā)射概率,解碼過(guò)程中動(dòng)態(tài)賦值的也是發(fā)射概率(轉(zhuǎn)移概率等已經(jīng)編碼成了圖得分了,這個(gè)設(shè)計(jì)很好地抽象出了聲學(xué)得分的接口)。其中 GMM 通直接過(guò)統(tǒng)計(jì)數(shù)據(jù)分布的方式建模,DNN 對(duì)狀態(tài)后驗(yàn)概率  建模,并通過(guò)以下公式近似得到 HMM 發(fā)射概率
建模,并通過(guò)以下公式近似得到 HMM 發(fā)射概率
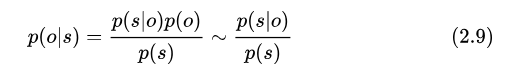
另外,在實(shí)現(xiàn)上,常常考慮發(fā)音單元的上下文關(guān)聯(lián)/協(xié)同發(fā)音,把建模的發(fā)音單元從上下文無(wú)關(guān)的單音素(Context-Independent Phoneme, CI-Phone),更改為上下文相關(guān)音素  (Context-Dependent Phoneme, CD-Phone),并增加一個(gè)上下文音素轉(zhuǎn)換為單音素的 WFST。
(Context-Dependent Phoneme, CD-Phone),并增加一個(gè)上下文音素轉(zhuǎn)換為單音素的 WFST。
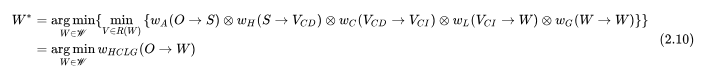
因此我們最常見(jiàn)的傳統(tǒng) ASR 系統(tǒng)架構(gòu)如下圖所示:
2.3.2 基于 CTC 的聲學(xué)模型
CTC 拓?fù)淇梢钥醋魇且环N特殊的 HMM 結(jié)構(gòu),不過(guò)由于其特殊性,這里單獨(dú)列出來(lái)討論。例如清華大學(xué)提出的 CTC-CRF 模型,建模直接為單音素  ,并且用一個(gè) WFST 來(lái)描述音素、blank之間的跳轉(zhuǎn)關(guān)系。
,并且用一個(gè) WFST 來(lái)描述音素、blank之間的跳轉(zhuǎn)關(guān)系。

CTC-CRF 中的 CTC 拓?fù)浣Y(jié)構(gòu)[4]
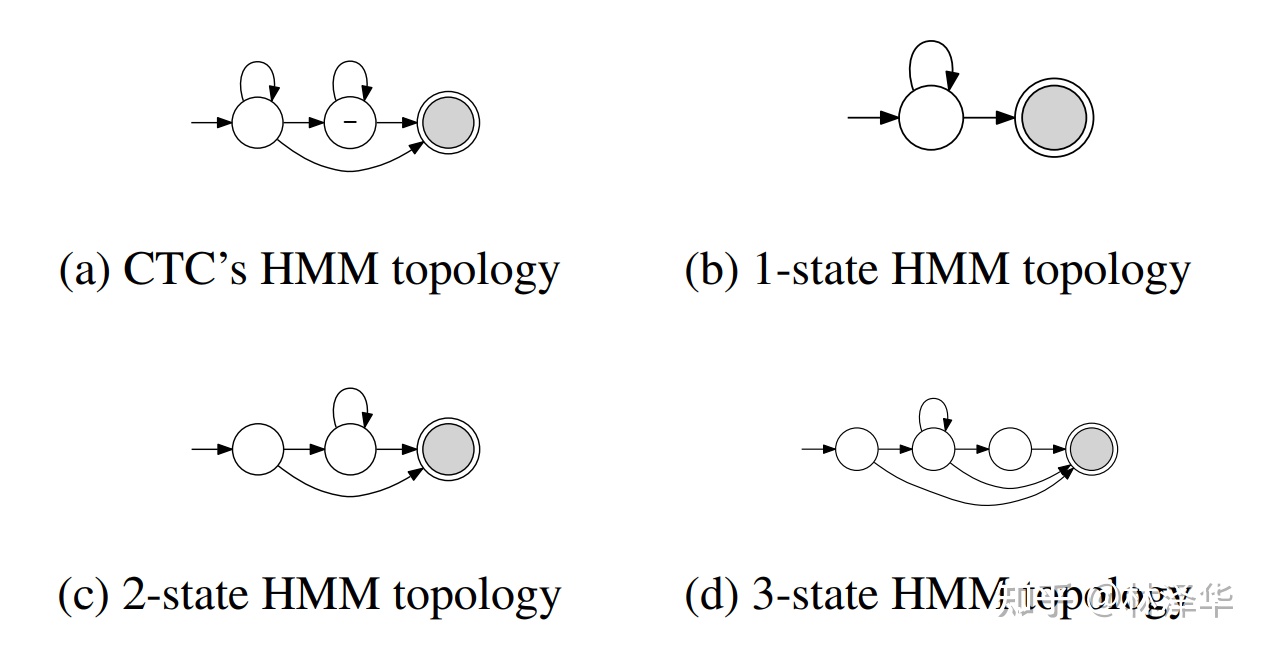
不同的 HMM,CTC 可以看作特殊的 HMM [5]
2.4 語(yǔ)言模型
ASR 中用到的語(yǔ)言模型在形式上較簡(jiǎn)單,建模的是根據(jù)歷史 Token 預(yù)測(cè)下一個(gè) Token 的概率。常用的有 RNN 語(yǔ)言模型和 n-gram 語(yǔ)言模型,建模方式分別為:
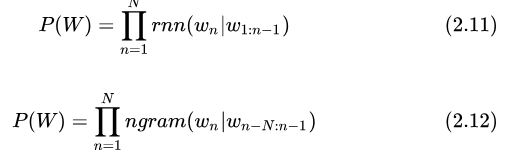
3. 端到端 ASR 算法原理
端到端 ASR 算法直接求解后驗(yàn)概率
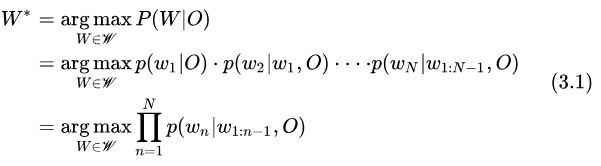
即:序列整體的后驗(yàn)概率可以通過(guò) Token 的后驗(yàn)概率累積得到。但這里也做了簡(jiǎn)化,假設(shè)當(dāng)前 Token  只依賴于之前出現(xiàn)的 Token
只依賴于之前出現(xiàn)的 Token  ,這個(gè)假設(shè)在我看來(lái)是合理的。
,這個(gè)假設(shè)在我看來(lái)是合理的。
從這個(gè)觀點(diǎn)出發(fā)看不同的端到端算法。
3.1 CTC-based E2E 模型
基于 CTC [6] 的模型,通過(guò)引入 blank Token 實(shí)現(xiàn)軟對(duì)齊,并且假設(shè)每一幀之間的 Token 相互獨(dú)立,

序列 CAT 的所有可能的軟對(duì)齊路徑
可以得到:
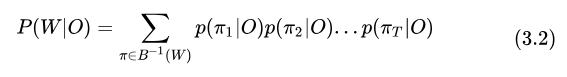
其中  是將軟對(duì)齊序列轉(zhuǎn)換為最終序列的操作,包含去除相鄰重復(fù) Token 和去除 blank,
是將軟對(duì)齊序列轉(zhuǎn)換為最終序列的操作,包含去除相鄰重復(fù) Token 和去除 blank,  是序列
是序列  的所有可能的對(duì)齊序列,
的所有可能的對(duì)齊序列,  是其中一個(gè)序列。
是其中一個(gè)序列。
上述是針對(duì)某一個(gè)已知序列  的后驗(yàn)概率,但是在解碼的時(shí)候,
的后驗(yàn)概率,但是在解碼的時(shí)候,  是待求解的未知量,求解的方法是先求最大概率的對(duì)齊序列
是待求解的未知量,求解的方法是先求最大概率的對(duì)齊序列  ,再轉(zhuǎn)換得到
,再轉(zhuǎn)換得到  。
。
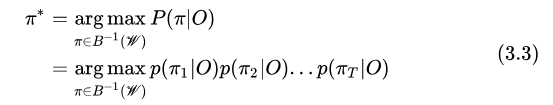
3.2 RNN-Transducer、RNA、Neural Transducer 等
這里討論一下 RNNT 和CTC-based Models 的區(qū)別。
首先,RNNT 也包含軟對(duì)齊,但是它和 CTC-based Models 對(duì)齊的方式/topo 不同;
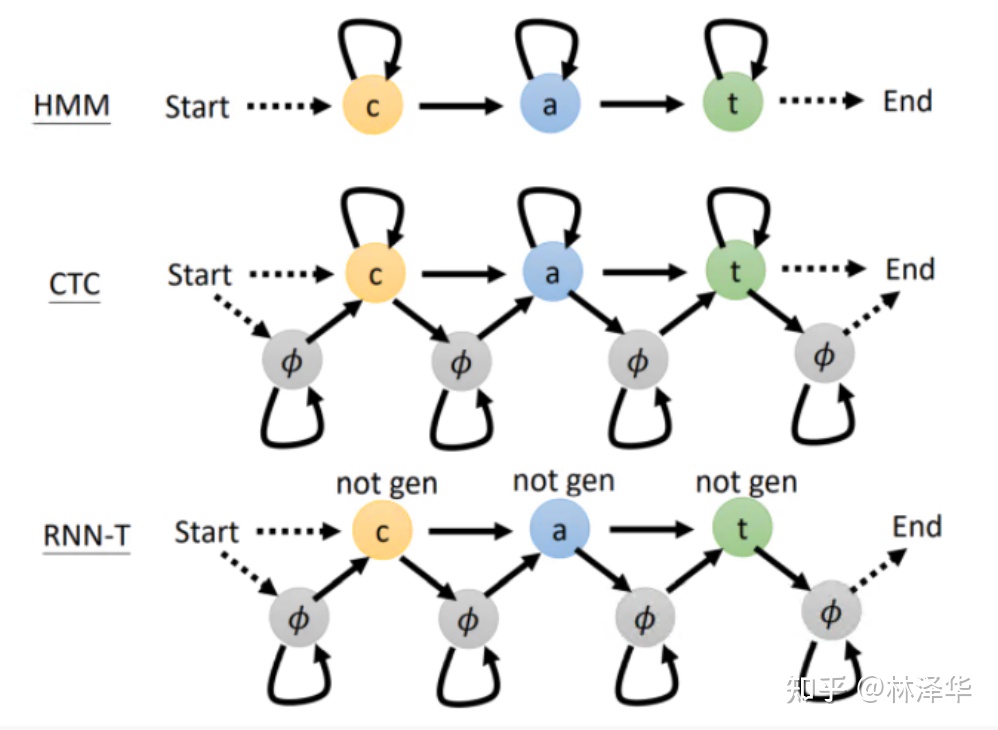
不同算法的軟對(duì)齊的狀態(tài)機(jī)表示[7]
其次,RNNT 引入了語(yǔ)言模型和一個(gè) JointNet 用于融合聲學(xué)和語(yǔ)言得分,其解碼過(guò)程的計(jì)算可以寫(xiě)作下式
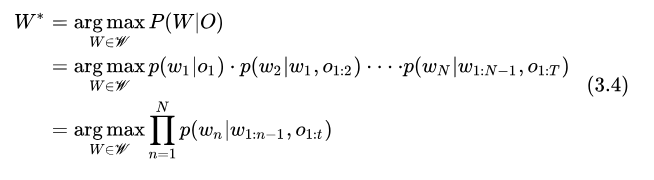
式中的 t 是解碼過(guò)程中動(dòng)態(tài)確定的,因?yàn)?RNNT 設(shè)計(jì)的解碼算法中,一幀輸入是可以對(duì)應(yīng)多個(gè)輸出的。式中每一個(gè) Token 的后驗(yàn)概率計(jì)算過(guò)程為:先由 Encoder(聲學(xué)模型)、PredictorNet(語(yǔ)言模型)獨(dú)立計(jì)算得到聲學(xué)特征和語(yǔ)言特征:
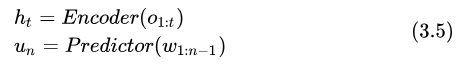
最后由 JointNet 融合兩者得到最終結(jié)果
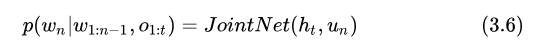
RNNT 通過(guò) PreditorNet 和 JointNet 引入了 Token 之間的相關(guān)性,可以看到,RNNT 的優(yōu)化目標(biāo)和 ASR 最初的目標(biāo)是很接近的,這也是它優(yōu)于 CTC-based Models 的內(nèi)在原因。
RNA、Neural Transducer 這兩種模型[8]是基于 RNNT 的:
- RNA 放棄不確定的
 ,假設(shè)每一幀只輸出一個(gè) Token 。
,假設(shè)每一幀只輸出一個(gè) Token 。 - Neural Transducer 則以特征幀序列 window 作為輸入,而不是一幀一幀輸入,每接受一個(gè) window
 ,依然可以對(duì)應(yīng)多個(gè)輸出。
,依然可以對(duì)應(yīng)多個(gè)輸出。
3.3 Attention-based E2E Models
Attention-based 模型的常見(jiàn)架構(gòu)為 Encoder-Decoder ,例如 LAS[9]、Transformer [10] 等。

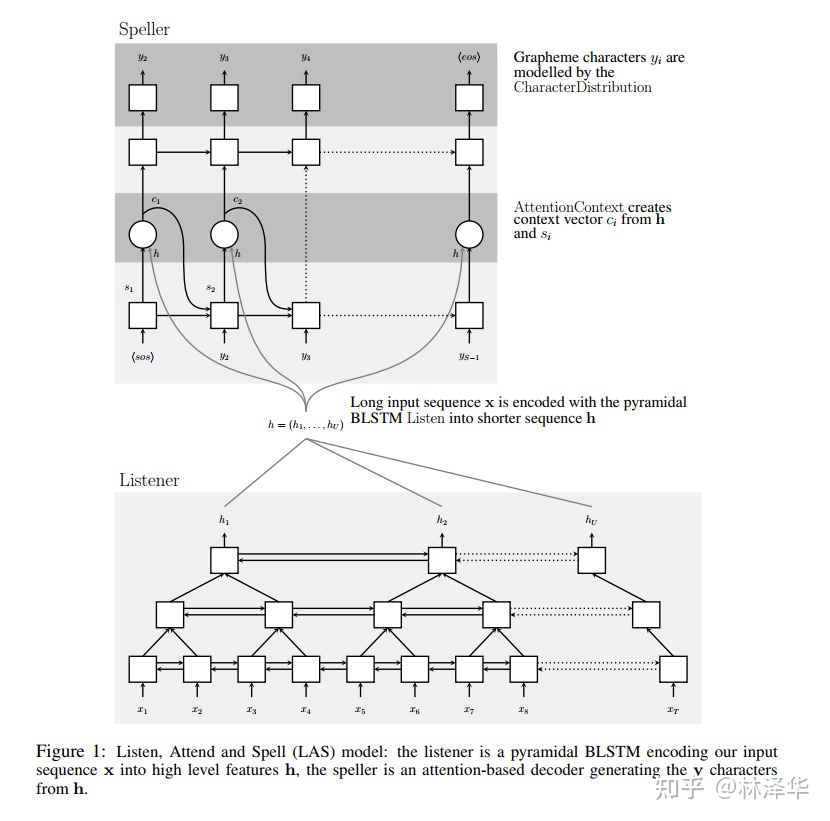
Encoder 用于提取音頻的高層次特征

Decoder 有兩種不同的模式,自回歸(AutoRegressive)模式的根據(jù)高層特征和歷史輸出進(jìn)行解碼
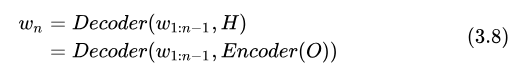
非自回歸(Non-AutoRegressive)的模型需要對(duì) Encoder 的輸出做進(jìn)一步處理得到初步結(jié)果,Decoder 大多只作為一個(gè)糾錯(cuò)或重打分模塊,這里暫時(shí)不展開(kāi)敘述。
我們看自回歸的解碼計(jì)算過(guò)程,可以歸納為
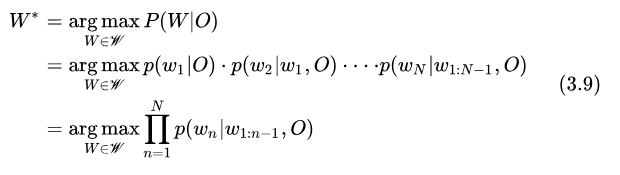
上式中,每一項(xiàng)  由 Decoder 直接建模,比 RNNT 更簡(jiǎn)潔。這與我們描述的端到端 ASR 最初的優(yōu)化目標(biāo)如出一轍,因此我認(rèn)為這一類模型在理論上最好地闡釋了“端到端”概念的。
由 Decoder 直接建模,比 RNNT 更簡(jiǎn)潔。這與我們描述的端到端 ASR 最初的優(yōu)化目標(biāo)如出一轍,因此我認(rèn)為這一類模型在理論上最好地闡釋了“端到端”概念的。
However, unlike the RNN transducer, in which the encoder and the prediction network are modeled independently and combined in the joint network, an attention-based model uses a single decoder to produce a distribution over the labels conditioned on the full sequence of previous predictions and the acoustics.[11]
在具體實(shí)現(xiàn)上,Encoder,Decoder 可以采取不同的模型結(jié)構(gòu)。LAS 模型采用了 BLSTM 實(shí)現(xiàn) Encoder, LSTM 實(shí)現(xiàn) Decoder。近幾年,出現(xiàn)更多的是采用基于自注意力機(jī)制的網(wǎng)絡(luò)結(jié)構(gòu)實(shí)現(xiàn) Encoder Decoder,現(xiàn)在最有名氣的莫過(guò)于 Transformer 了。
3.4 引入了 WFST 的端到端算法
端到端 ASR 模型引入語(yǔ)言模型的方式有幾種,包括在解碼過(guò)程中加入語(yǔ)言得分的 On-the-fly Rescore 的方式、對(duì) n-best 結(jié)果 Rescore 的方式、以及采用 WFST 解碼圖的方式。
目前開(kāi)源的項(xiàng)目中,采用 WFST 解碼圖的有 ESSEN[13]、WeNet[12],它把 Ngram 語(yǔ)言模型得分、詞典(字->詞)得分、以及 CTC topo 都編碼在 的跳轉(zhuǎn)弧上,聲學(xué)模型的作用是提供聲學(xué)得分給
的跳轉(zhuǎn)弧上,聲學(xué)模型的作用是提供聲學(xué)得分給 解碼,這很好地借鑒了傳統(tǒng) ASR 解碼器,區(qū)別在于聲學(xué)模型的建模單元不再是狀態(tài)或音素,而是更大粒度的字、子詞。其優(yōu)化過(guò)程可以寫(xiě)作
解碼,這很好地借鑒了傳統(tǒng) ASR 解碼器,區(qū)別在于聲學(xué)模型的建模單元不再是狀態(tài)或音素,而是更大粒度的字、子詞。其優(yōu)化過(guò)程可以寫(xiě)作
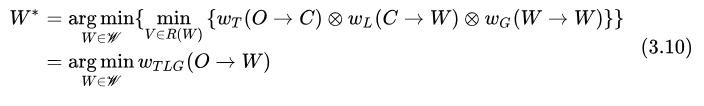
式中 指代 Token 序列,如字序列、子詞序列等,
指代 Token 序列,如字序列、子詞序列等, 描述不同 Token 之間的跳轉(zhuǎn)方式,上面介紹的 CTC-CRF 類似。
描述不同 Token 之間的跳轉(zhuǎn)方式,上面介紹的 CTC-CRF 類似。
3.5 拓展思考
端到端 ASR 算法的解碼也可以用 WFST 搜索的形式來(lái)描述,但原始的搜索圖是沒(méi)有經(jīng)過(guò)優(yōu)化的,其結(jié)構(gòu)僅僅類似于 。從這個(gè)角度看,傳統(tǒng) ASR 和端到端 ASR 的解碼都可以用 WFST 框架來(lái)描述,可見(jiàn) WFST 確實(shí)是一個(gè)強(qiáng)大的工具。
。從這個(gè)角度看,傳統(tǒng) ASR 和端到端 ASR 的解碼都可以用 WFST 框架來(lái)描述,可見(jiàn) WFST 確實(shí)是一個(gè)強(qiáng)大的工具。
4. 總結(jié)
圍繞求解最大后驗(yàn)概率 的問(wèn)題,傳統(tǒng) ASR 算法將求解過(guò)程分解成多個(gè)步驟,將系統(tǒng)模塊化后分別優(yōu)化,各模塊任務(wù)明確;端到端 ASR 算法則直接求解后驗(yàn)概率,系統(tǒng)更加簡(jiǎn)潔。不同的算法包含了不同的前提假設(shè),前提不同,那么算法的適用場(chǎng)景就會(huì)有所區(qū)別,因此不能簡(jiǎn)單地說(shuō)孰優(yōu)孰劣。
的問(wèn)題,傳統(tǒng) ASR 算法將求解過(guò)程分解成多個(gè)步驟,將系統(tǒng)模塊化后分別優(yōu)化,各模塊任務(wù)明確;端到端 ASR 算法則直接求解后驗(yàn)概率,系統(tǒng)更加簡(jiǎn)潔。不同的算法包含了不同的前提假設(shè),前提不同,那么算法的適用場(chǎng)景就會(huì)有所區(qū)別,因此不能簡(jiǎn)單地說(shuō)孰優(yōu)孰劣。
在文章末尾,我也提到,不同的 ASR 算法在實(shí)現(xiàn)上都可以用同一個(gè)框架來(lái)描述,是否可以說(shuō),眾多的 ASR 算法從同一個(gè)起點(diǎn)出發(fā),走不同的路,最終又殊途同歸了呢?
參考資料
- WFST: https://cs.nyu.edu/~mohri/postscript/csl01.pdf
- HMM: https://cogsci.ucsd.edu/~ajyu/Readings/Tutorials/hmm.pdf
- 傳統(tǒng)ASR架構(gòu): 3人半年打造語(yǔ)音識(shí)別引擎--58同城語(yǔ)音識(shí)別自研之路
- 清華大學(xué)CTC-CRF: http://oa.ee.tsinghua.edu.cn/~ouzhijian/pdf/ctc-crf.pdf
- Chain topo: http://www.danielpovey.com/files/2018_interspeech_end2end.pdf
- CTC: Sequence Modeling with CTC
- e2e topo: HMM, CTC和RNN-Transducer對(duì)齊方式的差異
- 李宏毅 e2e: https://zhuanlan.zhihu.com/p/130899095
- LAS 模型: https://arxiv.org/abs/1508.01211v2
- Transformer: https://arxiv.org/abs/1706.03762v5
- google e2e: https://www.isca-speech.org/archive/Interspeech_2017/pdfs/0233.PDF
- WeNet: wenet-e2e/wenet
- ESSEN: srvk/eesen
- Kaldi: kaldi-asr/kaldi





