
一、開篇
經過上次文章的鋪墊,相信大家對 JAVA 的 NIO 有了一些感性的認識,也初步了解了它的 API 了,可以開始去閱讀 Kafka Producer 端的發送消息的部分了。
突然想感嘆一下,閱讀 Kafka 這個全世界著名的開源項目,多多少少會讓人賞心悅目
二、發送消息的八個主流程
先大致掃一眼,發送消息的八個主流程,然后再逐個擊破。
發送消息的主流程主要是在 Sender 方法里的,Sender 是一個后臺線程,在構造 Producer 的時候,就已經被啟動在后臺運行了。所以我們主要看它的 run 方法。
run 方法是一個 while 循環,我們看里面的 run 方法。(當前位置:Sender 類)
步驟一:獲取集群的元數據。(當前位置:Sender 類)
在上一篇文章可以知道,我們已經在 KafkaProducer 類的 doSend 方法中,完成了元數據的拉取,所以這里是可以獲取到元數據的了。
步驟二:判斷哪些 partition 有消息可以發送。(當前位置:Sender 類)
步驟三:標識還沒有拉取到元數據的 topic,這些 topic 需要再次拉取一次元數據。(當前位置:Sender 類)
這個是一些容錯
步驟四:檢查與要發送消息的主機的網絡連接是否建立好了(當前類:Sender 類)
步驟五:把發往同一臺機器的不同批次的消息合并成一個請求
步驟六:處理超時的批次
步驟七:創建請求
步驟八:真正的發送消息出去的網絡請求,包括:發送請求,接收和處理響應,拉取元數據等
三、消息可以發送出去的條件
(1)首先我們來到這個 ready 方法里面(當前位置:RecordAccumulator)
(2)來看這一行:
boolean exhausted = this.free.queued() > 0;
free 是指 BufferPool,queued 方法:
waiters 里面是 Condition,表示是否有等待釋放內存的線程,如果有,那么就是內存不足的意思。
也就是說,內存不足,exhausted 為 true,否則 為 false。
(3)遍歷所有的分區和批次
拿出一個批次出來,下面開始判斷是否可發送的條件:
(4)第一次發送為 false;下次重試時間到了,false;重試時間沒到,true。
boolean backingOff = batch.attempts > 0 && batch.lastAttemptMs + retryBackoffMs > nowMs;
batch.attempts :表示是否嘗試過了
batch.lastAttemptMs :表示分區的上次嘗試時間,初始值為當前時間
retryBackOffMs :表示重試的時間間隔,默認為 100 ms
nowMs:表示當前時間
那么這句是什么意思?
- 如果消息是第一次發送,那么這個 backingOff 就是 false;
- 如果消息第一次發送失敗,進入重試,并且還沒到下次重試的時間,這個 backingOff 就是 true,如果到了重試的時間,那么 backingOff 就是 false。
這句話可能不好理解,可以假設,上次重試時間點是 10:00:00.000,重試的時間間隔是 100ms,下次重試時間是 10:00:00.100,而當前時間是 10:00:00.020,即還沒到下次重試的時間。
那么 batch.lastAttemptMs + retryBackoffMs > nowMs 為 true,即還沒到下次重試時間。
(5)計算出已經等待的時間
long waitedTimeMs = nowMs - batch.lastAttemptMs;
nowMs:表示當前時間
batch.lastAttemptMs:上次重試時間
waitedTimeMs:已經等待的時間
(6)等待的時間
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
retryBackoffMs :表示重試的時間間隔,默認是 100 ms
lingerMs:這個值默認是 0,即來一條發送一條。所以在生產上,一定要配置這個值,充分利用 batch 來緩存批次,避免過多和服務器的通信。
如果是第一次發送,backingOff 為 false,那么 timeToWaitMs 為 lingerMs。
(7)還需要等待多久
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
timeToWaitMs:一共需要等待的時間
waitedTimeMs:已經等待的時間
timeLeftMs:還需要等待的時間
(8)是否有批次滿了
boolean full = deque.size() > 1 || batch.records.isFull();
如果隊列里的批次數量大于 1,則表示已經有批次已經滿了。
如果批次數量為 1,但是這個批次的消息已經滿了
(9)是否超時,即已經等待的時長,是否大于一共需要等待的時長
boolean expired = waitedTimeMs >= timeToWaitMs;
(10)最后是發送條件,下面的五個條件是或的關系,任意一個滿足,都可以發送
boolean sendable = full || expired || exhausted || closed || flushInProgress();
- 如果批次已經滿了
- 等待的時間到了
- 內存滿了
- 客戶端關閉,但仍然有消息沒發送
(11)如果達到了發送消息的條件,并且重試的時間到了(或者是第一次發送)
則把當前消息所在的分區的 Leader Partition 對應的主機,加到 readyNodes 數據結構中來
if (sendable && !backingOff) {
readyNodes.add(leader);
}
至此,已經找到了需要發送消息的主機,那么接下來就是建立到這臺主機的連接。
四、Kafka Producer 對于 Java NIO 的封裝
到建立網絡連接的時候,看到這段代碼:
可以看到具體的實現是在 NetwordClient 里面
第一個條件就是發送消息不能是在更新元數據的時候;
第二個條件點進去:
發現這邊有個核心的對象,selector,它是 NetworkClient 里的一個屬性。(NetworkClient 是 Kafka 網絡連接的一個很重要的對象!):
我們再點進去,找它的實現類,Selector:
可以看到有兩個核心屬性,第一個 nIOSelector 就是對于 Java 的 Nio 的封裝。
第二個是一個 Map,Map 的 key 是 broker 的編號,value 是 KafkaChannel,KafkaChannel 可以理解為是 SocketChannel。
好,然后再繼續看一下 KafkaChannel:
最終,如下圖所示:
五、檢查并建立網絡連接
我們從第四步的代碼開始看:
第一個條件,表示是否建立好了連接,如果建立好了,會在 nodeState 的結構中緩存起來的。
第二個條件:通道是否準備好了:
第三個條件:
max.in.flight.requests.per.connection
這個參數,是在初始化 NetworkClient 對象的時候,傳遞進來的,默認值是 5.
表示最多默認有多少次請求沒有得到服務端的響應。
這里第三個條件,就是說,是否小于 5 個請求發送出去了,沒有得到響應。
但現在我們是第一次判斷與主機的網絡是否連接好,網絡肯定是沒有建立好的,所以這個方法會返回 false。
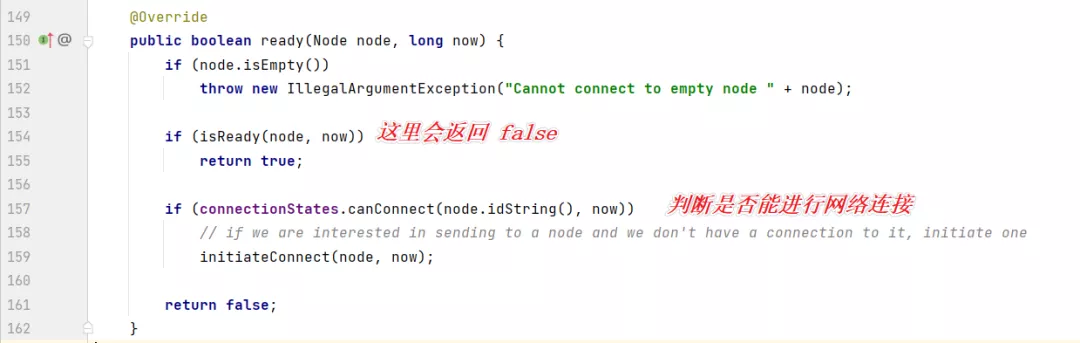

然后就開始初始化網絡連接了:
這里連接的代碼和平時寫的 Java NIO 的代碼是一樣的
socket.setTcpNoDelay(true);
注意,他這里有一句這個代碼,這個默認值是 false,意思是它會把網絡中的一些小的數據包收集起來,組合成一個大的數據包然后再發送出去。
它認為如果網絡中有大量小的數據包,會影響網絡擁塞。
所以這里,一定是要把它設置為 true 的。因為有時候,數據包就是比較小,這里不幫我們發送,明細是不合適的。
這里,建立網絡連接,最終往 selector 上綁定了一個 OP_CONNECT 事件,和我們平時寫的代碼是一樣的。
最終這個方法返回了 false:
那么回到主流程上,返回 false 之后,這些主機都會被移除。
然后是步驟七,創建一個請求。
最后執行到這里:
點進去看,核心代碼在這里:
繼續往里面看,核心代碼在這里:
點進去:
再點進去,(當前位置:PlaintextTransportLayer)
這里,如果已經連接網絡了,則移除 OP_CONNECT 事件,并且增加 OP_READ 事件,這樣的話,就可以讀取到 服務端發送回來的響應了。
到這里位置,第一遍就建立好了網絡連接。
六、準備發送消息
剛剛我們第一遍執行,建立好了網絡連接,現在開始第二次執行
這里網絡已經準備好了,所以 if 的方法不執行,節點也不會被移除了
這個時候是可以合并批次的,因為這個 nodes 不為空
然后創建一個請求,并且發送這個請求:
點進去:
在點進去 send 方法里,這里有一個很重要的操作,綁定了 OP_WRITE 事件
綁定了 OP_WRITE 事件,才能把數據發送出去!!
現在我們再退回到 這個方法:
點到 poll 方法里來:
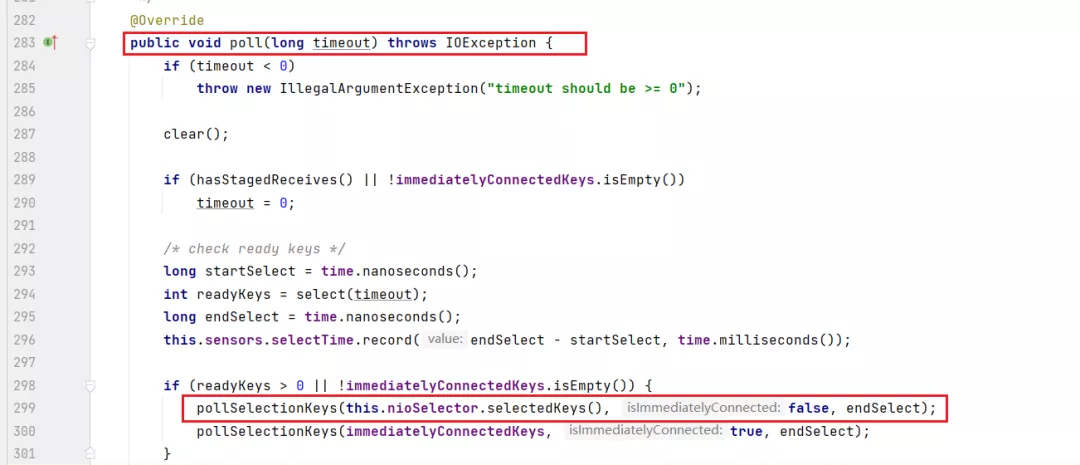
然后這里會從 selector 上拿到 SelectionKey,如果是寫事件:
點到 send 方法里來:
把消息寫出去,并且移除 OP_WRITE 事件。
到此為止,消息終于發送出去了。
七、獲取服務端的響應,拆包和粘包處理
我們可以想到,客戶端發送出去的肯定是多個請求,那么服務端返回的也是多個請求,那客戶端如何從響應中解析出這多個請求呢?這就是拆包處理。
比如,服務端返回的響應是這樣的:
響應成功響應失敗
我們要拆分成:
響應成功
響應失敗
但是,由于網絡原因,返回的可能是這樣的
響應成
功響應失敗
也就是分兩次發回給客戶端
客戶端該如何處理?
Kafka 是在響應消息的前面加上了每個響應的長度編碼
40響應成功30響應失敗
那這個長度會發生拆包嗎?也很簡單,申請一定長度的字節,比如2個字節來存長度,把這個2字節的長度滿了,就是長度了。
等到讀滿了2字節,就轉換成 int 類型,再申請這個 int 類型長度的內存,再去接收這么多長度的字節,一直到讀滿為止。
然后來看看 Kafka 的代碼如何處理的,看到 poll 方法里處理 OP_READ 的方法的部分
最終,拆包和粘包的代碼:
size.hasRemaining, size 是一個 4 字節的 ByteBuffer
然后開始讀4個字節的數據
int bytesRead = channel.read(size);
讀取完了之后,再看有沒有剩余空間了,如果讀滿了,那么把這個4字節的數變成一個 int 值,并且繼續分配這個 int 值大小的 ByteBuffer
if (!size.hasRemaining()) {
size.rewind();
int receiveSize = size.getInt();
if (receiveSize < 0)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + ")");
if (maxSize != UNLIMITED && receiveSize > maxSize)
throw new InvalidReceiveException("Invalid receive (size = " + receiveSize + " larger than " + maxSize + ")");
this.buffer = ByteBuffer.allocate(receiveSize);
}
然后一直讀取內容:
if (buffer != null) {
int bytesRead = channel.read(buffer);
if (bytesRead < 0)
throw new EOFException();
read += bytesRead;
}
然后再來看:
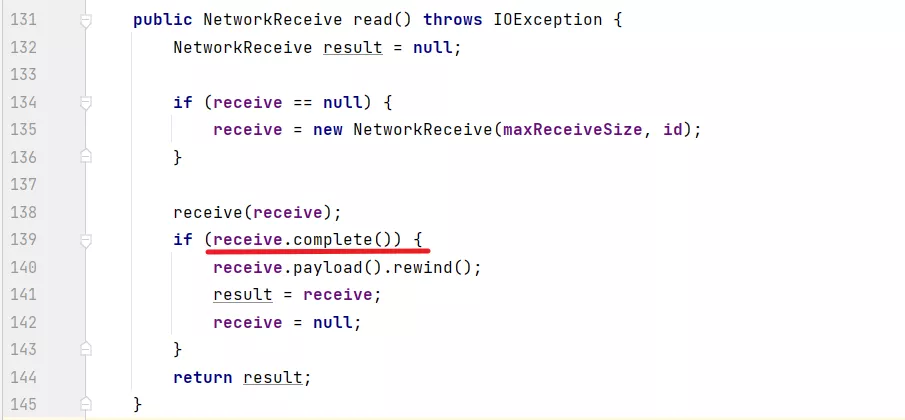
這個 complete 方法,是判斷 size 已經讀滿了,并且 內容也已經讀滿了,那么就表示讀取到了一個完整的響應了。
那么這就是完整的拆包和粘包的處理了,大概也就是20行代碼,也是很精彩的。
八、總結
本次我們完整的看了 Sender 線程發送消息的完整過程,里面包括了 Kafka 如何封裝 Java NIO 代碼,并且合理的建立連接,綁定 OP_READ,OP_WRITE 事件,并且讀取服務端的響應,代碼質量還是非常高的,看起來也是賞心悅目。
希望大家對著源碼再好好看一遍,一定會有收貨的。





