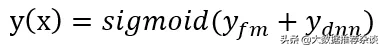擊這里在線咨詢客服")
背景
工業(yè)推薦系統(tǒng)一般包含四個(gè)環(huán)節(jié),分別是召回、粗排、精排和重排。召回階段根據(jù)用戶的興趣和歷史行為,從海量的物品庫(kù)里,快速找回一小部分用戶潛在感興趣的物品,然后交給排序環(huán)節(jié),排序環(huán)節(jié)可以融入較多特征,使用復(fù)雜模型,來(lái)精準(zhǔn)地做個(gè)性化推薦。有時(shí)候因?yàn)槊總€(gè)用戶召回環(huán)節(jié)返回的物品數(shù)量還是太多,怕排序環(huán)節(jié)速度跟不上,所以可以在召回和精排之間加入一個(gè)粗排環(huán)節(jié),通過(guò)少量用戶和物品特征,簡(jiǎn)單模型,來(lái)對(duì)召回的結(jié)果進(jìn)行粗略的排序,在保證一定精準(zhǔn)的前提下,進(jìn)一步減少往后傳送的物品數(shù)量,粗排往往是可選的,可用可不同,跟場(chǎng)景有關(guān)。之后,是精排環(huán)節(jié),使用你能想到的任何特征,可以上你能承受速度極限的復(fù)雜模型,盡量精準(zhǔn)地對(duì)物品進(jìn)行個(gè)性化排序。排序完成后,傳給重排環(huán)節(jié),重排環(huán)節(jié)往往會(huì)上各種技術(shù)及業(yè)務(wù)策略,比如去已讀、去重、打散、多樣性保證、固定類(lèi)型物品插入等等,主要是技術(shù)產(chǎn)品策略主導(dǎo)或者為了改進(jìn)用戶體驗(yàn)的。
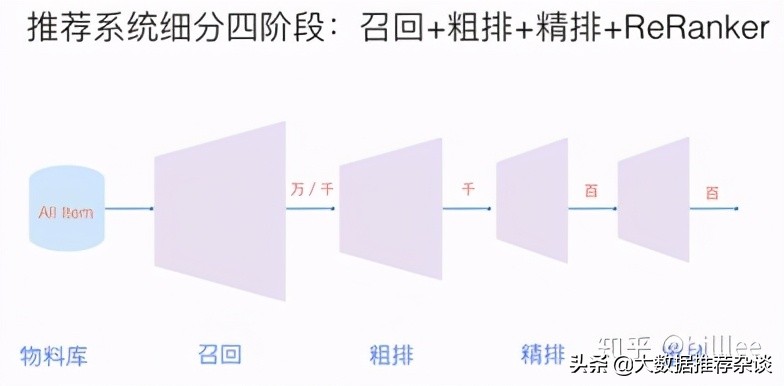
排序環(huán)節(jié)是推薦系統(tǒng)最關(guān)鍵,也是最具有技術(shù)含量的部分, 工業(yè)界應(yīng)用的排序模型,大致經(jīng)歷三個(gè)階段,如下圖所示。
當(dāng)前業(yè)界主流的推薦排序模型是深度學(xué)習(xí)模型,基于深度學(xué)習(xí)模型的多目標(biāo)優(yōu)化、ListWise以及強(qiáng)化學(xué)習(xí)是當(dāng)前最常見(jiàn)的技術(shù)演進(jìn)方向,本文主要介紹工業(yè)界經(jīng)典的推薦排序模型。
LR算法
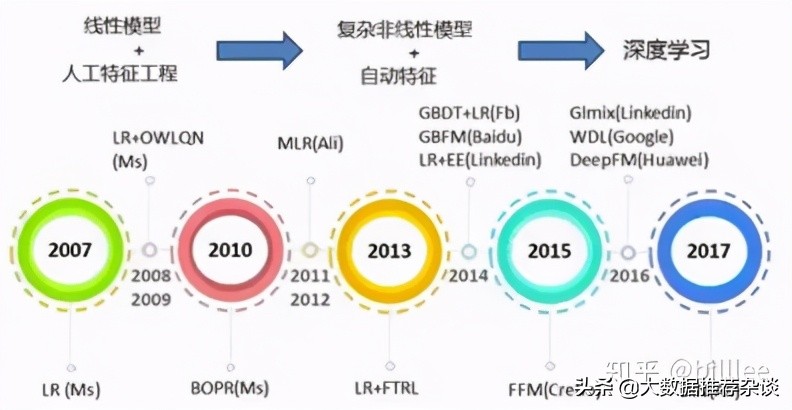
LR 模型是 CTR 預(yù)估領(lǐng)域早期最成功的模型,大多早期的工業(yè)推薦排序系統(tǒng)采取 LR 這種 “線性模型 + 人工特征組合引入非線性” 的模式。LR 模型具有訓(xùn)練快、上線快、可解釋性強(qiáng)、容易上規(guī)模等優(yōu)點(diǎn),目前仍然有不少實(shí)際系統(tǒng)采取這種模式。

FTRL算法
普通邏輯回歸不適應(yīng)大規(guī)模稀疏特征的點(diǎn)擊率預(yù)估。一是傳統(tǒng)的邏輯回歸參數(shù)訓(xùn)練過(guò)程都依賴牛頓法或L-BFGS等算法,這些算法并不容易在大規(guī)模數(shù)據(jù)集上得以處理,二是不容易得到稀疏解,而實(shí)際上對(duì)于大規(guī)模稀疏的數(shù)據(jù)來(lái)說(shuō),通常僅有少量特征是被激活的。FTRL梯度優(yōu)化算法改進(jìn)了傳統(tǒng)的LR算法,其核心就是模型的參數(shù)會(huì)在每一個(gè)數(shù)據(jù)點(diǎn)進(jìn)行更新,是一種在線學(xué)習(xí)算法,其參數(shù)更新偽代碼如下:

FM算法
FM算法在 LR 的基礎(chǔ)上加入二階特征組合,即任意兩個(gè)特征進(jìn)行組合,將組合出的特征看作新特征,加到 LR 模型中。組合特征的權(quán)重在訓(xùn)練階段學(xué)習(xí)獲得。但這樣對(duì)組合特征建模,泛化能力比較弱,尤其是在大規(guī)模稀疏特征存在的場(chǎng)景下。FM 模型也直接引入任意兩個(gè)特征的二階特征組合,但對(duì)于每個(gè)特征,學(xué)習(xí)一個(gè)大小為 k 的一維向量,兩個(gè)特征 Xi和 Xj 的特征組合的權(quán)重值,通過(guò)特征對(duì)應(yīng)的向量 Vi 和 Vj 的內(nèi)積 <Vi , Vj> 來(lái)表示。這本質(zhì)上是對(duì)特征進(jìn)行 Embedding化表征,和目前常見(jiàn)的各種實(shí)體 Embedding 本質(zhì)思想是一樣的。

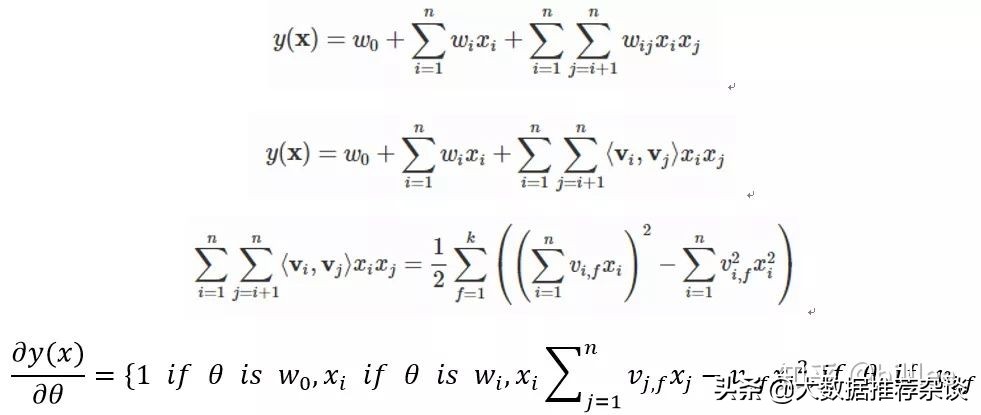
FM 可以模擬二階多項(xiàng)式核SVM,但是FM的訓(xùn)練和預(yù)估復(fù)雜度是線性的,而二階多項(xiàng)式核SVM需要計(jì)算核矩陣,復(fù)雜度為N平方。MF算法相當(dāng)于只有User和Item兩類(lèi)特征的FM模型,而 FM模型可以加入任意特征,比如Context特征。
Wide&Deep
Wide&Deep 是推薦領(lǐng)域取得較大成功的最早期深度模型,由 google 于 2016 年提出。Wide&Deep模型包括 Wide 部分和 Deep 部分,Wide 部分為 LR,輸入為one-hot 后的離散型特征和等頻分桶后的連續(xù)性特征,這部分可以對(duì)樣本中特征與目標(biāo)較為明顯的關(guān)聯(lián)進(jìn)行記憶學(xué)習(xí);Deep 部分為 MLP,輸入為Embedding 后的離散型特征和歸一化后的連續(xù)型特征,可以泛化學(xué)習(xí)到樣本中多個(gè)特征之間與目標(biāo)看不到的潛在關(guān)聯(lián)。使用 Wide&Deep 的另一個(gè)優(yōu)勢(shì)在于 Wide 部分的存在,可以沿用之前淺層學(xué)習(xí)的成果,尤其是特征工程部分。
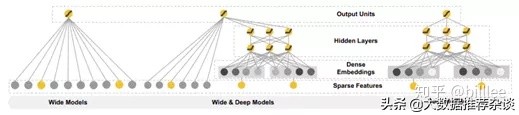
Wide部分是廣義線性模型,可以包括原始特征及轉(zhuǎn)換后的特征,Deep部分是神經(jīng)網(wǎng)絡(luò)。
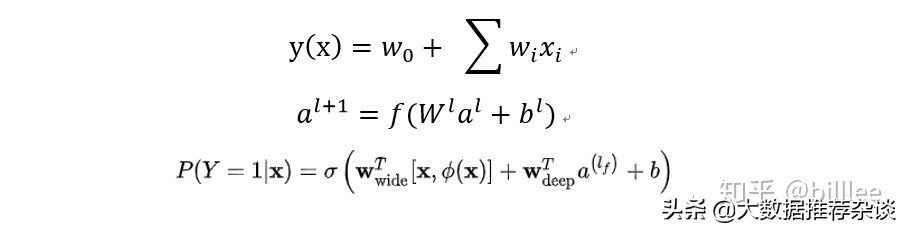
DeepFM
DeepFM 將 Wide&Deep 的Wide 部分 LR 替換成 FM 來(lái)避免人工特征工程。DeepFM 相比 Wide&Deep 模型更能捕捉低階特征信息。同時(shí),Wide&Deep 部分的 Embedding 層需要針對(duì) Deep 部分單獨(dú)設(shè)計(jì),而在 DeepFM 中,F(xiàn)M 和 Deep 部分共享Embedding 層,F(xiàn)M 訓(xùn)練得到的參數(shù)及作為 wide 部分的輸出,也作為 MLP 部分的輸入。DeepFM 支持end-end 訓(xùn)練,Embedding 和網(wǎng)絡(luò)權(quán)重聯(lián)合訓(xùn)練,無(wú)需預(yù)訓(xùn)練和單獨(dú)訓(xùn)練。從個(gè)人實(shí)踐效果來(lái)看,DeepFM算法如果在人工交叉特征已經(jīng)比較豐富的情況下,效果相對(duì)于Wide&Deep算法提升有限。
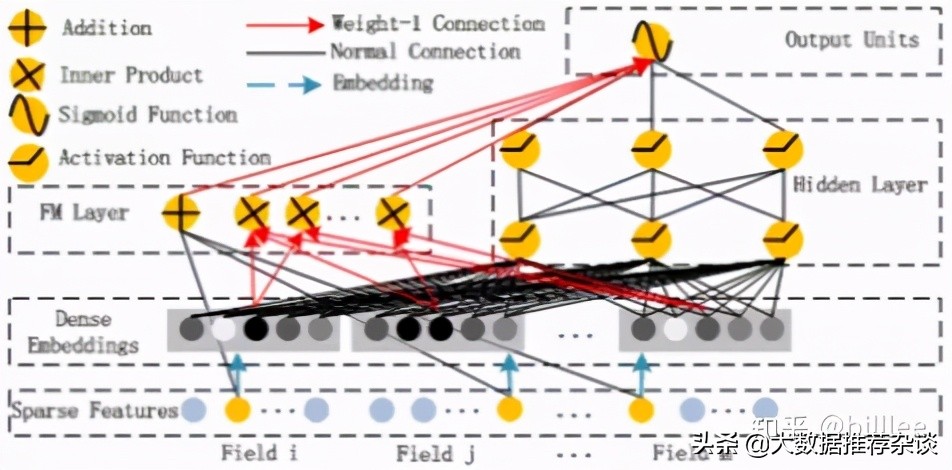
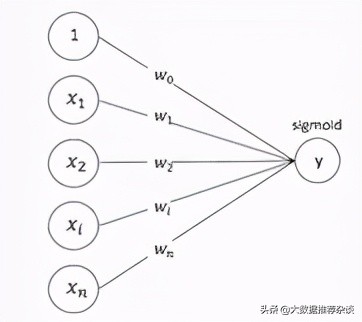
其輸出為: