
什么是深度學習
深度學習有如下一些眾所周知且被廣泛接受的定義。
(1)深度學習是機器學習的子集。
(2)深度學習使用級聯的多層(非線性)處理單元,稱為人工神經網絡(ANN),以及受大腦結構和功能(神經元)啟發的算法。每個連續層使用前一層的輸出作為輸入。
(3)深度學習使用ANN進行特征提取和轉換,處理數據,查找模式和開發抽象。
(4)深度學習可以是監督的(如分類),也可以是無監督的(如模式分析)。
(5)深度學習使用梯度下降算法來學習與不同抽象級別相對應的多個級別的表示,由此構成概念的層次結構。
(6)深度學習通過學習將世界表示為概念的嵌套層次來實現強大的功能和靈活性,每個概念都是根據更簡單的概念定義的,更抽象的表示是根據較不抽象的概念計算來的。
例如,對于圖像分類問題,深度學習模型使用其隱藏層架構以增量方式學習圖像類。
首先,它自動提取低層級的特征,例如識別亮區或暗區;之后,提取高層級特征(如邊緣);其次,它會提取最高層級的特征(如形狀),以便對它們進行分類。
每個節點或神經元代表整個圖像的某一細微方面。如果將它們放在一起,就描繪了整幅圖像。而且它們能夠將圖像完全表現出來。此外,網絡中的每個節點和每個神經元都被賦予權重。這些權重表示神經元的實際權重,它與輸出的關聯強度相關。這些權重可以在模型開發過程中進行調整。
經典學習與深度學習
(1)手工特征提取與自動特征提取。為了用傳統ML技術解決圖像處理問題,最重要的預處理步驟是手工特征(如HOG和SIFT)提取,以降低圖像的復雜性并使模式對學習算法更加可見,從而使其更好地工作。深度學習算法最大的優點是它們嘗試以增量方式訓練圖像,從而學習低級和高級特征。這消除了在提取或工程中對手工制作的特征的需要。
(2)部分與端到端解決方案。傳統的ML技術通過分解問題,首先解決不同的部分,然后將結果聚合在一起提供輸出來解決問題,而深度學習技術則使用端到端方法來解決問題。例如,在目標檢測問題中,諸如SVM的經典ML算法需要一個邊界框目標檢測算法,該算法將識別所有可能的目標,將HOG作為ML算法的輸入,以便識別正確的目標。但深度學習方法(如YOLO網絡)將圖像作為輸入,并提供對象的位置和名稱作為輸出。
(3)訓練時間和高級硬件。與傳統的ML算法不同,深度學習算法由于有大量的參數且數據集相對龐大,需要很長時間來訓練,因此應該始終在GPU等高端硬件上訓練深度學習模型,并記住訓練一個合理的時間,因為時間是有效訓練模型的一個非常重要的方面。
(4)適應性和可轉移性。經典的ML技術有很大的局限性,而深度學習技術則應用廣泛,且適用于不同的領域。其中很大一部分用于轉移學習,這使得人們能夠將預先訓練的深層網絡用于同一領域內的不同應用。例如,在圖像處理中,通常使用預先訓練的圖像分類網絡作為特征提取的前端來檢測目標和分割網絡。
現在來看看ML和深度學習模型在圖像分類(如貓和狗的圖像)方面的區別。傳統的ML有特征提取和分類器,可以用來解決任何問題,如圖10-1所示。
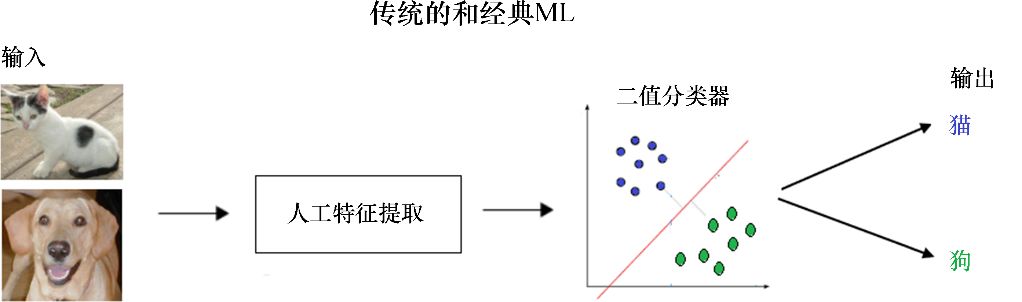
圖10-1 傳統的和經典的ML
圖10-2所示的是深度學習網絡,通過深度學習,可以看到前面討論過的隱藏層以及實際決策過程。

圖10-2 深度學習網絡
10.1.3 為何需要深度學習
如前所述,如果有更多的數據,那么最好的選擇就是使用性能更好的深度網絡來處理。很多時候,使用的數據越多,結果就越準確。經典的ML方法需要一組復雜的ML算法,而更多的數據只會影響其精度,需要使用復雜的方法來彌補較低準確性的缺陷。此外,學習也受到影響——當添加更多的訓練數據來訓練模型時,學習幾乎在某個時間點停止。圖10-3所示的圖形描述了深度學習算法與傳統的機器學習算法的性能差異。
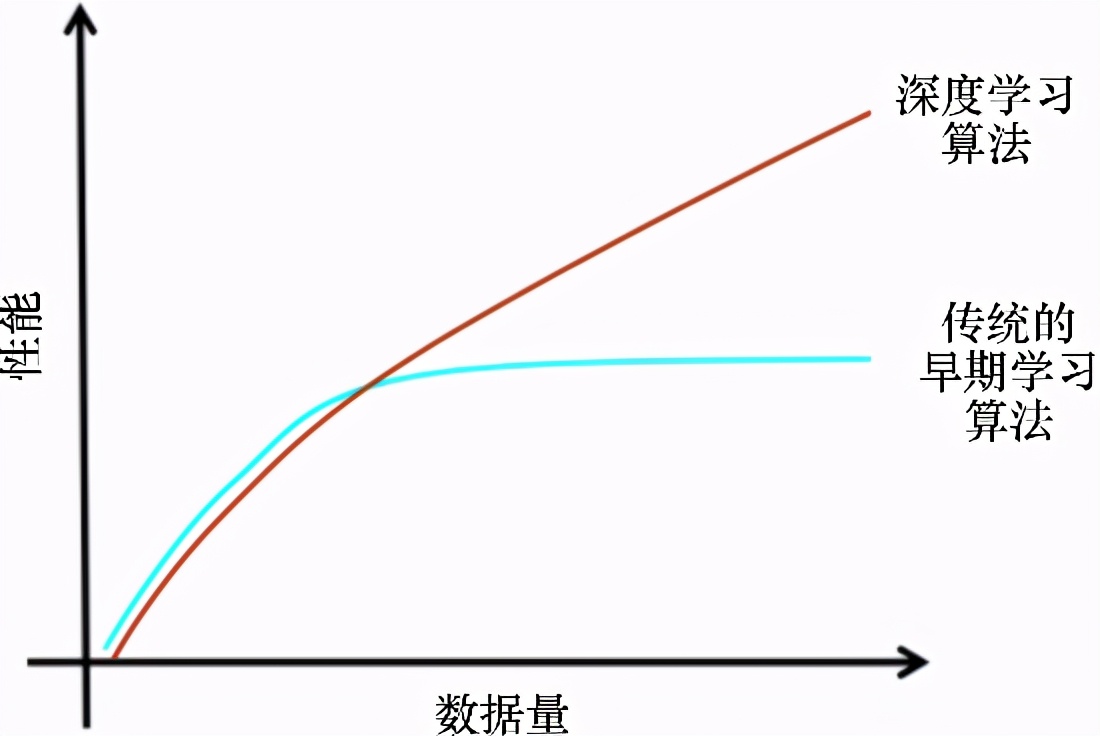
圖10-3 深度學習算法與經典的機器學習算法的性能比較
本文摘自《Python圖像處理實戰》





