擊這里在線咨詢客服")
在這一節(jié),我們將簡(jiǎn)要介紹不同類型的機(jī)器學(xué)習(xí),并重點(diǎn)關(guān)注它們的主要特點(diǎn)和差異。在接下來(lái)的部分中,我們將討論非正式定義,以及正式定義。如果你不熟悉討論中涉及的數(shù)學(xué)概念,則可以跳過詳細(xì)信息。但是,研究所有未知的理論因素是非常明智的,因?yàn)樗鼈儗?duì)于理解后面章節(jié)的概念至關(guān)重要。
1.3.1 有監(jiān)督學(xué)習(xí)算法
在有監(jiān)督的場(chǎng)景中,模型的任務(wù)是查找樣本的正確標(biāo)簽,假設(shè)在訓(xùn)練集時(shí)標(biāo)記正確,并有可能將估計(jì)值與正確值進(jìn)行比較。有監(jiān)督這個(gè)術(shù)語(yǔ)源自外部教學(xué)代理的想法,其在每次預(yù)測(cè)之后提供精確和即時(shí)的反饋。模型可以使用此類反饋?zhàn)鳛檎`差的度量,從而減少錯(cuò)誤所需的更正。
更正式地說,如果我們假設(shè)一個(gè)數(shù)據(jù)生成過程,數(shù)據(jù)集

的獲取如下:

其中
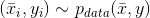
且


如1.2節(jié)所述,所有樣本必須是從數(shù)據(jù)生成過程中統(tǒng)一采樣的獨(dú)立且同分布(Independent and Identically Distributed,IID)的值。特別地,所有類別必須代表實(shí)際分布(例如,如果p( y = 0) = 0.4且p( y = 1) = 0.6,則該比例應(yīng)為40%或60%)。但是,為了避免偏差,當(dāng)類之間的差異不是很大時(shí),合理的選擇是完全統(tǒng)一的采樣,并且對(duì)于y = 1,2,…,M是具有相同數(shù)量的代表。
通用分類器

可以通過兩種方式建模。
- 輸出預(yù)測(cè)類的參數(shù)化函數(shù)。
- 參數(shù)化概率分布,輸出每個(gè)輸入樣本的類概率。
對(duì)于第一種情況,我們有:
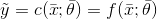
且

是一個(gè)錯(cuò)誤的測(cè)量結(jié)果
考慮整個(gè)數(shù)據(jù)集X,可以計(jì)算全局成本函數(shù)L:
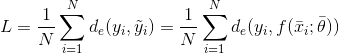
由于L僅取決于參數(shù)向量(xi和yi是常數(shù)),因此通用算法必須找到最小化成本函數(shù)的最佳參數(shù)向量。例如在回歸問題(標(biāo)簽是連續(xù)的)中,誤差度量可以是實(shí)際值和預(yù)測(cè)值之間的平方誤差:

這種成本函數(shù)可以用不同的方式優(yōu)化(特定算法特有的),但一個(gè)非常常見的策略(尤其在深度學(xué)習(xí)中)是采用隨機(jī)梯度下降(Stochastic Gradient Descent,SGD)算法。它由以下兩個(gè)步驟的迭代組成。
- 使用少量樣本xi∈X計(jì)算梯度∇L(相對(duì)于參數(shù)向量)。
- 更新權(quán)重并在梯度的相反方向上移動(dòng)參數(shù)(記住漸變始終指向最大值)。
對(duì)于第二種情況,當(dāng)分類器是基于概率分布時(shí),它應(yīng)該表示為參數(shù)化的條件概率分布:
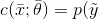
換句話說,分類器現(xiàn)在將輸出給定輸入向量y的概率。現(xiàn)在的目標(biāo)是找到最佳參數(shù)集,它將獲得:
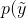
在前面的公式中,我們將pdata表示為條件分布。我們可以使用概率距離度量來(lái)進(jìn)行優(yōu)化,例如Kullback-Leibler散度DKL(DKL始終為非負(fù),且僅當(dāng)兩個(gè)分布相同時(shí),DKL=0):

通過一些簡(jiǎn)單的操作,我們得到:

因此,生成的成本函數(shù)對(duì)應(yīng)于p和pdata之間交叉熵的差值達(dá)到定值(數(shù)據(jù)生成過程的熵)。訓(xùn)練策略現(xiàn)在是基于使用獨(dú)熱編碼表示的標(biāo)簽(例如如果有兩個(gè)標(biāo)簽0→(0,1)和1→(1,0),那么所有元素的總和必須始終等于1)并使用內(nèi)在概率(例如在邏輯回歸中)或softmax濾波器(其將M值轉(zhuǎn)換為概率分布)輸出。
在這兩種情況下,很明顯隱藏教師模型的存在提供了一致的誤差測(cè)量,它允許模型相應(yīng)地校正參數(shù)。特別地,第二種方法對(duì)達(dá)到我們的目的非常有用,因此如果你還不太清楚,我建議你進(jìn)一步研究它(主要定義也可以在machine Learning Algorithms, Second Edition一書中找到)。
我們現(xiàn)在討論一個(gè)非常基本的監(jiān)督學(xué)習(xí)示例,它是一個(gè)線性回歸模型,可用于預(yù)測(cè)簡(jiǎn)單時(shí)間序列的演變。
有監(jiān)督的hello world!
在此示例中,我們要展示如何使用二維數(shù)據(jù)執(zhí)行簡(jiǎn)單的線性回歸。特別地,假設(shè)我們有一個(gè)包含100個(gè)樣本的自定義數(shù)據(jù)集,如下所示:
import numpy as np
import pandas as pd
T = np.expand_dims(np.linspace(0.0, 10.0, num=100), axis=1)
X = (T * np.random.uniform(1.0, 1.5, size=(100, 1))) +
np.random.normal(0.0, 3.5, size=(100, 1))
df = pd.DataFrame(np.concatenate([T, X], axis=1), columns=['t', 'x'])
我們還創(chuàng)建了一個(gè)pandas的DataFrame,因?yàn)槭褂胹eaborn庫(kù)創(chuàng)建繪圖更容易。在本書中,通常省略了圖表的代碼(使用Matplotlib或seaborn),但它始終存在于庫(kù)中。
我們希望用一種綜合的方式表示數(shù)據(jù)集,如下所示:
此任務(wù)可以使用線性回歸算法執(zhí)行,如下所示:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(T, X)
print('x(t) = {0:.3f}t + {1:.3f}'.format(lr.coef_[0][0], lr.intercept_[0]))
最后一個(gè)命令的輸出如下:
X(t) = 1.169t + 0.628
我們還可以將數(shù)據(jù)集與回歸線一起繪制,獲得視覺確認(rèn),如圖1-4所示。
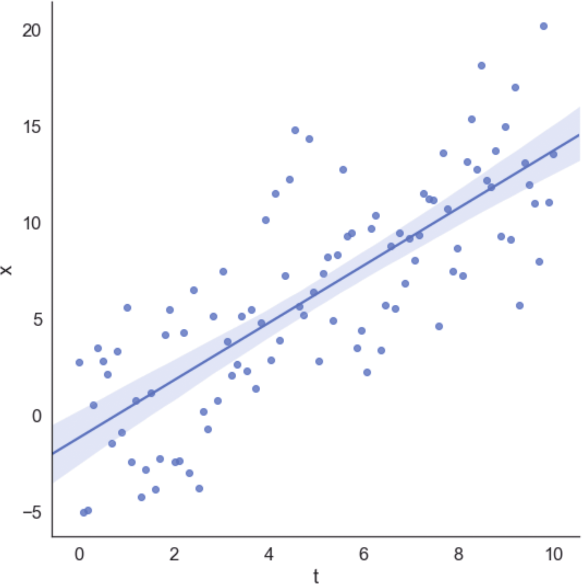
圖1-4 數(shù)據(jù)集與回歸線
在該示例中,回歸算法最小化了平方誤差成本函數(shù),試圖減小預(yù)測(cè)值與實(shí)際值之間的差異。由于對(duì)稱分布,所以高斯(空均值)噪聲對(duì)斜率的影響最小。
1.3.2 無(wú)監(jiān)督學(xué)習(xí)算法
很容易想象在無(wú)監(jiān)督的場(chǎng)景中,沒有隱藏的老師,因此主要目標(biāo)與最小化基本事實(shí)的預(yù)測(cè)誤差無(wú)關(guān)。實(shí)際上,在這種背景下,相同的基本事實(shí)的概念具有略微不同的含義。事實(shí)上,在使用分類器時(shí),我們希望訓(xùn)練樣本出現(xiàn)一個(gè)零錯(cuò)誤(這意味著除了真正類之外的其他類永遠(yuǎn)不會(huì)被接受為正確類)。
相反,在無(wú)監(jiān)督問題中,我們希望模型在沒有任何正式指示的情況下學(xué)習(xí)一些信息。這種情況意味著唯一可以學(xué)習(xí)的因素是樣本本身包含的。因此,無(wú)監(jiān)督算法通常旨在發(fā)現(xiàn)樣本之間的相似性和模式,或者在給定一組從中得出的向量的情況下,再現(xiàn)輸入分布。現(xiàn)在讓我們分析一些最常見的無(wú)監(jiān)督模型類別。
1.聚類分析
聚類分析(通常稱為聚類)是我們想要找出大量樣本中共同特征的示例。在這種情況下,我們總是假設(shè)存在數(shù)據(jù)生成過程
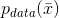
,并且將數(shù)據(jù)集X定義為:

其中

且
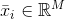
聚類算法基于一個(gè)隱含假設(shè),即樣本可以根據(jù)其相似性進(jìn)行分組。特別是當(dāng)給定兩個(gè)向量,相似性函數(shù)被定義為度量函數(shù)的倒數(shù)或相反數(shù)。例如,如果我們?cè)跉W幾里得空間中,則有:

且
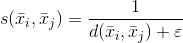
在前面的公式中,引入了常數(shù)ε以避免除以零。很明顯,d(a,c) < d(a,b) ⇒ s(a,c) > s(a,b)。因此,給定每個(gè)聚類

的代表,我們可以根據(jù)規(guī)則創(chuàng)建一組分配的向量:

換句話說,聚類包含代表距離同所有其他代表相比最小的所有元素。這意味著聚類包含同所有代表相比與代表的相似性最大的樣本。此外,在分配之后,樣本獲得與同一聚類的其他成員共享其功能的權(quán)利。
事實(shí)上,聚類分析最重要的應(yīng)用之一是嘗試提高被認(rèn)為相似樣本的同質(zhì)性。例如推薦引擎可以基于用戶向量的聚類(包含有關(guān)用戶興趣和購(gòu)買產(chǎn)品的信息)來(lái)進(jìn)行推薦。一旦定義了組,屬于同一聚類的所有因素都被認(rèn)為是相似的,因此我們被隱式授權(quán)共享差異。如果用戶A購(gòu)買了產(chǎn)品P并對(duì)其進(jìn)行了積極評(píng)價(jià),我們可以向沒有購(gòu)買產(chǎn)品的用戶B推薦此商品,反之亦然。該過程看似隨意,但是當(dāng)因素的數(shù)量很大并且特征向量包含許多判別因素(例如評(píng)級(jí))時(shí),因素就變得非常有效了。
2.生成模型
另一種無(wú)監(jiān)督方法是基于生成模型。這個(gè)概念與我們已經(jīng)討論的有監(jiān)督算法的概念沒有太大區(qū)別,但在這種情況下,數(shù)據(jù)生成過程不包含任何標(biāo)簽。因此,我們的目標(biāo)是對(duì)參數(shù)化分布進(jìn)行建模并優(yōu)化參數(shù),以便將候選分布與數(shù)據(jù)生成過程之間的距離最小化:
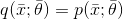
該過程通常基于Kullback-Leibler散度或其他類似度量:

在訓(xùn)練階段結(jié)束時(shí),我們假設(shè)L→0,所以p≈pdata。通過這種方式,我們不會(huì)將分析限制在可能樣本的子集,而是限制在整個(gè)分布。使用生成模型,我們可以繪制與訓(xùn)練過程選擇樣本截然不同的新樣本,但它們始終屬于相同的分布。因此,它們(可能)總是可以接受的。
例如生成式對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Network,GAN)是一種特殊的深度學(xué)習(xí)模型,它能夠?qū)W習(xí)圖像集的分布,生成與訓(xùn)練樣本幾乎無(wú)法區(qū)分的新樣本(從視覺語(yǔ)義的角度來(lái)看)。無(wú)監(jiān)督學(xué)習(xí)是本書的主題,因此我們不會(huì)在此處進(jìn)一步討論GAN。所有這些概念將在第9章(用實(shí)際例子)進(jìn)行深入討論。
3.關(guān)聯(lián)規(guī)則
我們正在考慮的最后一種無(wú)監(jiān)督方法是基于關(guān)聯(lián)規(guī)則的,它在數(shù)據(jù)挖掘領(lǐng)域非常重要。常見的情形是由一部分商品組成的商業(yè)交易集合,目標(biāo)是找出商品之間最重要的關(guān)聯(lián)(例如購(gòu)買Pi和Pj的概率為70%)。特定算法可以有效地挖掘整個(gè)數(shù)據(jù)庫(kù),突出所有可以考慮到的戰(zhàn)略和物流目的之間的關(guān)系。例如在線商店可以使用這種方法來(lái)促銷那些經(jīng)常與其他商品一起購(gòu)買的商品。此外,預(yù)測(cè)方法允許通過建議所有很可能售罄的商品來(lái)簡(jiǎn)化供應(yīng)流程,這要?dú)w功于其他項(xiàng)目的銷售增加。
在這一點(diǎn)上,讀者了解無(wú)監(jiān)督學(xué)習(xí)的實(shí)際例子是有幫助的。不需要特別的先決條件,但你最好具備概率論的基本知識(shí)。
4.無(wú)監(jiān)督的hello world!
由于本書完全致力于無(wú)監(jiān)督算法的講解,在此不將簡(jiǎn)單的聚類分析顯示為hello world!示例,而是假設(shè)一個(gè)非常基本的生成模型。假設(shè)我們正在監(jiān)控每小時(shí)到車站的列車數(shù)量,因?yàn)槲覀冃枰_定車站所需的管理員數(shù)量。特別地,要求每列列車至少有1名管理員,每當(dāng)管理員數(shù)量不足時(shí),我們將被罰款。
此外,在每小時(shí)開始時(shí)發(fā)送一個(gè)組更容易,而不是逐個(gè)控制管理員。由于問題非常簡(jiǎn)單,我們也知道泊松分布是一個(gè)好的分布,參數(shù)μ同樣也是平均值。從理論上講,我們知道這種分布可以在獨(dú)立的主要假設(shè)下有效地模擬在固定時(shí)間范圍內(nèi)發(fā)生的事件的隨機(jī)數(shù)。在一般情況下生成模型基于參數(shù)化分布(例如神經(jīng)網(wǎng)絡(luò)),并且不對(duì)其系列進(jìn)行具體假設(shè)。僅在某些特定情況下(例如高斯混合),選擇具有特定屬性的分布是合理的,并且在不損失嚴(yán)謹(jǐn)性的情況下,我們可以將該示例視為此類方案之一。
泊松分布的概率質(zhì)量函數(shù)為:

此分布描述了在預(yù)定義的間隔內(nèi)觀察k個(gè)事件的概率。在我們的例子中,間隔始終是1小時(shí),我們希望觀測(cè)10多趟列車,然后估計(jì)概率。我們?nèi)绾尾拍塬@得μ的正確數(shù)值?
最常見的策略稱為最大似然估計(jì)(Maximum Likelihood Estimation,MLE)。該策略通過收集一組觀測(cè)值,然后找到μ的值,該值使分布生成所有點(diǎn)的概率最大化。
假設(shè)我們已經(jīng)收集了 N 個(gè)觀測(cè)值(每個(gè)觀測(cè)值是一小時(shí)內(nèi)到達(dá)的列車數(shù)量),則相對(duì)于所有樣本的μ的似然度是在使用以下公式計(jì)算的概率分布下所有樣本的聯(lián)合概率μ(為簡(jiǎn)單起見,假設(shè)為IID):

當(dāng)我們使用乘積和指數(shù)時(shí),計(jì)算對(duì)數(shù)似然是一種常見的規(guī)則:
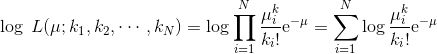
一旦計(jì)算出對(duì)數(shù)似然,我們就可以將μ的導(dǎo)數(shù)設(shè)置為0,以便找到最佳值。在這種情況下,我們省略了證明(直接獲得)并直接得出μ的最大似然估計(jì)值:

很幸運(yùn)的是最大似然估計(jì)值只是到達(dá)時(shí)間的平均值。這意味著,如果我們觀察到N個(gè)平均值為μ的值,則有很大可能生成它們的泊松分布,其特征系數(shù)為μ。因此,從這種分布中抽取的任何其他樣本將與觀察到的數(shù)據(jù)集兼容。
我們現(xiàn)在可以從第一次模擬開始。假設(shè)我們?cè)诠ぷ魅盏南挛缡占?5個(gè)觀察結(jié)果,如下所示:
import numpy as np
obs = np.array([7, 11, 9, 9, 8, 11, 9, 9, 8, 7, 11, 8, 9, 9, 11, 7, 10, 9, 10, 9, 7, 8, 9, 10, 13])
mu = np.mean(obs)
print('mu = {}'.format(mu))
最后一個(gè)命令的輸出如下:
mu = 9.12
因此,每小時(shí)平均到達(dá)9趟列車。初始分布的直方圖如圖1-5所示。
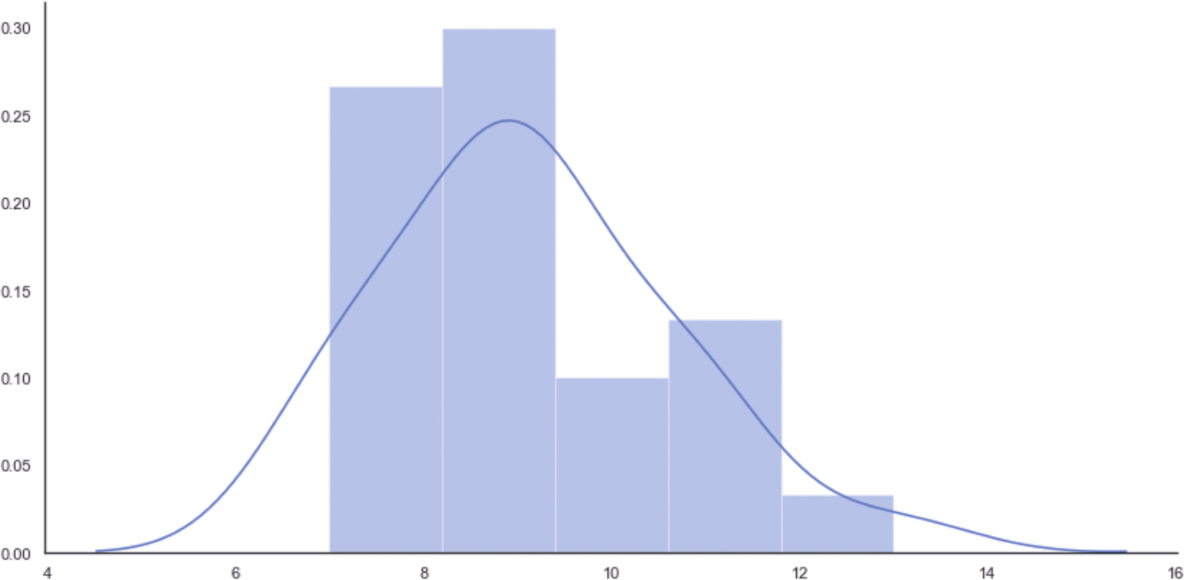
圖1-5 初始分布的直方圖
要計(jì)算請(qǐng)求的概率,我們需要使用累積分布函數(shù)(Cumulative Distribution Function,CDF),它在SciPy中實(shí)現(xiàn)(在scipy.stats包中)。特別地,由于我們感興趣的是觀察到的列車數(shù)量超過固定值的概率,因此有必要使用與1-CDF相對(duì)應(yīng)的生存函數(shù)(Survival Function,SF),如下所示:
from scipy.stats import poisson
print('P(more than 8 trains) = {}'.format(poisson.sf(8, mu)))
print('P(more than 9 trains) = {}'.format(poisson.sf(9, mu)))
print('P(more than 10 trains) = {}'.format(poisson.sf(10, mu)))
print('P(more than 11 trains) = {}'.format(poisson.sf(11, mu)))
上述代碼段的輸出如下所示:
P(more than 8 trains) = 0.5600494497386543
P(more than 9 trains) = 0.42839824517059516
P(more than 10 trains) = 0.30833234660452563
P(more than 11 trains) = 0.20878680161156604
正如預(yù)期的那樣,能觀測(cè)10多趟列車的概率很低(30%),派10名管理員似乎不合理。但是,由于我們的模型是自適應(yīng)的,我們可以繼續(xù)收集觀測(cè)值(例如在清晨),如下所示:
new_obs = np.array([13, 14, 11, 10, 11, 13, 13, 9, 11, 14, 12, 11, 12,14,
8, 13, 10, 14, 12, 13, 10, 9, 14, 13, 11, 14, 13, 14])
obs = np.concatenate([obs, new_obs])
mu = np.mean(obs)
print('mu = {}'.format(mu))
μ的新值如下所示:
mu = 10.641509433962264
現(xiàn)在平均每小時(shí) 11 趟列車。假設(shè)我們收集了足夠的樣本(考慮所有潛在的事故),我們可以重新估計(jì)概率,如下所示:
print(P(more than 8 trains) = {}'.format(poisson.sf(8, mu)))
print(P(more than 9 trains) = {}'.format(poisson.sf(9, mu)))
print(P(more than 10 trains) = {}'.format(poisson.sf(10, mu)))
print(P(more than 11 trains) = {}'.format(poisson.sf(11, mu)))
輸出如下:
P(more than 8 trains) = 0.734624391080037
P(more than 9 trains) = 0.6193541369812121
P(more than 10 trains) = 0.49668918740243756
P(more than 11 trains) = 0.3780218948425254
使用新數(shù)據(jù)集觀測(cè)超過9趟列車的概率約為62%(這證實(shí)了我們最初的選擇),但現(xiàn)在觀測(cè)超過10趟列車的概率約為50%。由于我們不想承擔(dān)支付罰款的風(fēng)險(xiǎn)(這比管理員的成本高),因此最好派10名管理員。為了得到進(jìn)一步的確認(rèn),我們決定從分布中抽取2000個(gè)值,如下所示:
syn = poisson.rvs(mu, size=2000)
相應(yīng)的直方圖如圖1-6所示。
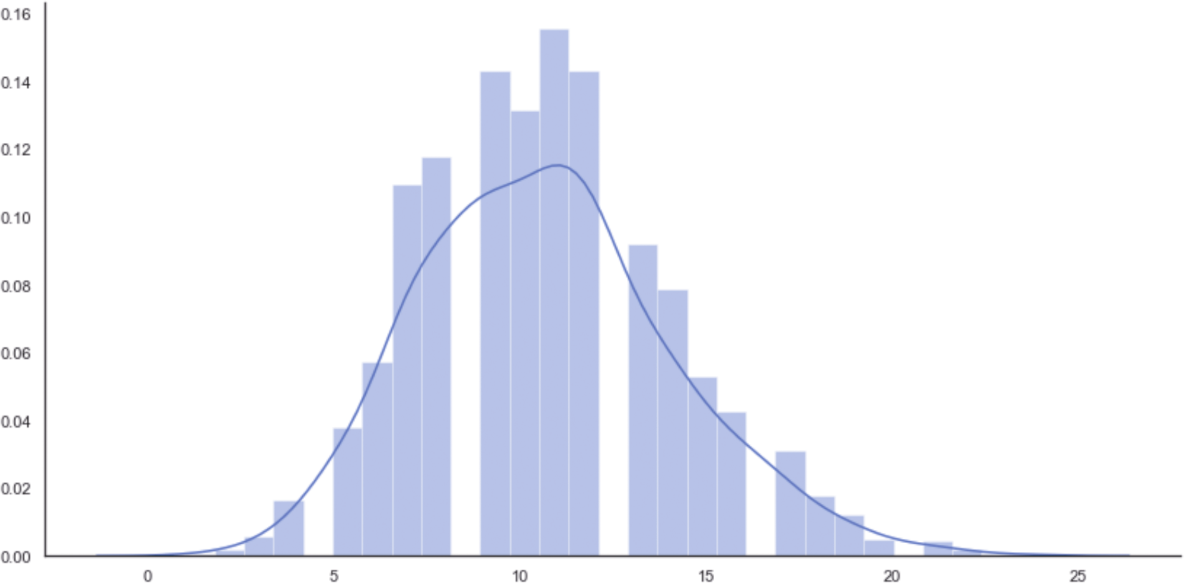
圖1-6 從最終泊松分布中抽取2000個(gè)值的直方圖
該圖在10(表示10名管理員)之后(非常接近11時(shí))達(dá)到峰值,然后從k=13開始快速衰減,這是使用有限數(shù)據(jù)集發(fā)現(xiàn)的(比較直方圖的形狀以進(jìn)一步確認(rèn))。但是,在這種情況下,我們正在生成無(wú)法存在于觀察集中的潛在樣本。MLE保證了概率分布與數(shù)據(jù)一致,并且新樣本將相應(yīng)地進(jìn)行加權(quán)。這個(gè)例子非常簡(jiǎn)單,其目的只是展示生成模型的動(dòng)態(tài)性。
我們將在本書的后續(xù)章節(jié)中討論許多更復(fù)雜的模型和示例。許多算法常見的一個(gè)重要技術(shù)在于不是選擇預(yù)定義的分布(這意味著先驗(yàn)知識(shí)),而是選擇靈活的參數(shù)模型(例如神經(jīng)網(wǎng)絡(luò))來(lái)找出最優(yōu)分布。只有基礎(chǔ)隨機(jī)過程存在較高的置信度時(shí),優(yōu)先選擇預(yù)定義(如本例所示)才合理。在其他情況下,最好避免任何假設(shè),只依賴數(shù)據(jù),以便找到數(shù)據(jù)生成過程中的最適當(dāng)?shù)慕浦怠?/p>
1.3.3 半監(jiān)督學(xué)習(xí)算法
半監(jiān)督場(chǎng)景可以被視為標(biāo)準(zhǔn)監(jiān)督場(chǎng)景,它利用了一些屬于無(wú)監(jiān)督學(xué)習(xí)技術(shù)的特征。事實(shí)上,當(dāng)很容易獲得大的未標(biāo)記數(shù)據(jù)集,而標(biāo)簽成本又非常高時(shí),就會(huì)出現(xiàn)一個(gè)非常普遍的問題。因此,只標(biāo)記部分樣本并將標(biāo)簽傳播到所有未標(biāo)記樣本,這些樣本與標(biāo)記樣本的距離就會(huì)低于預(yù)定義閾值。如果從單個(gè)數(shù)據(jù)生成過程中抽取數(shù)據(jù)集并且標(biāo)記的樣本均勻分布,則半監(jiān)督算法可以實(shí)現(xiàn)與有監(jiān)督算法相當(dāng)?shù)木取T诒緯校覀儾挥懻撨@些算法,但有必要簡(jiǎn)要介紹兩個(gè)非常重要的模型。
- 標(biāo)簽傳播。
- 半監(jiān)督支持向量機(jī)。
第一個(gè)稱為標(biāo)簽傳播(Label Propagation),其目的是將一些樣本的標(biāo)簽傳播到較大的群體。我們可以通過圖形來(lái)實(shí)現(xiàn)該目標(biāo),其中每個(gè)頂點(diǎn)表示樣本并且每條邊都使用距離函數(shù)進(jìn)行加權(quán)。通過迭代,所有標(biāo)記的樣本將其標(biāo)簽值的一小部分發(fā)送給它們所有的近鄰,并且重復(fù)該過程直到標(biāo)簽停止變化。該系統(tǒng)具有最終穩(wěn)定點(diǎn)(即無(wú)法再演變的配置),算法可以通過有限的迭代次數(shù)輕松到達(dá)該點(diǎn)。
標(biāo)簽傳播在某些樣本可以根據(jù)相似性度量進(jìn)行標(biāo)記的情況下非常有用。例如在線商店可能擁有大量客戶,但只有10%的人透露了自己的性別。如果特征向量足夠豐富以表示男性和女性用戶的常見行為,則可以使用標(biāo)簽傳播算法來(lái)猜測(cè)未公開信息的客戶性別。當(dāng)然,請(qǐng)務(wù)必記住,所有分配都基于相似樣本具有相同標(biāo)簽的假設(shè)。在許多情況下都是如此,但是當(dāng)特征向量的復(fù)雜性增加時(shí),也可能會(huì)產(chǎn)生誤導(dǎo)。
第二個(gè)重要的半監(jiān)督算法系列是基于標(biāo)準(zhǔn)支持向量機(jī)(Support Vector Machine,SVM)的,對(duì)包含未標(biāo)記樣本的數(shù)據(jù)集的擴(kuò)展。在這種情況下,我們不想傳播現(xiàn)有標(biāo)簽,而是傳播分類標(biāo)準(zhǔn)。換句話說,我們希望使用標(biāo)記數(shù)據(jù)集來(lái)訓(xùn)練分類器,并將分類規(guī)則擴(kuò)展到未標(biāo)記的樣本。
與僅能評(píng)估未標(biāo)記樣本的標(biāo)準(zhǔn)過程相反,半監(jiān)督SVM使用它們來(lái)校正分離超平面。假設(shè)始終基于相似性:如果A的標(biāo)簽為1,而未標(biāo)記樣本B的d(A,B)<ε(其中ε是預(yù)定義的閾值),則可以合理地假設(shè)B的標(biāo)簽也是1。通過這種方式,即使僅手動(dòng)標(biāo)記了一個(gè)子集,分類器也可以在整個(gè)數(shù)據(jù)集上實(shí)現(xiàn)高精度。與標(biāo)簽傳播類似,這種類型的模型只有在數(shù)據(jù)集的結(jié)構(gòu)不是非常復(fù)雜時(shí),特別是當(dāng)相似性假設(shè)成立時(shí)(不幸的是,在某些情況下,找到合適的距離度量非常困難,因此許多類似的樣本確實(shí)不相似,反之亦然)才是可靠的。
1.3.4 強(qiáng)化學(xué)習(xí)算法
強(qiáng)化學(xué)習(xí)可以被視為有監(jiān)督的學(xué)習(xí)場(chǎng)景,其中隱藏教師僅在模型的每個(gè)決策后提供近似反饋。更正式地說,強(qiáng)化學(xué)習(xí)的特點(diǎn)是代理和環(huán)境之間的持續(xù)互動(dòng)。前者負(fù)責(zé)決策(行動(dòng)),最終增加其回報(bào),而后者則為每項(xiàng)行動(dòng)提供反饋。反饋通常被視為獎(jiǎng)勵(lì),其價(jià)值可以是積極的(行動(dòng)已成功)或消極的(行動(dòng)不能復(fù)用)。當(dāng)代理分析環(huán)境(狀態(tài))的不同配置時(shí),每個(gè)獎(jiǎng)勵(lì)必須被視為綁定到元組(行動(dòng),狀態(tài))。因此,我們的最終目標(biāo)是找到一種方針(建議在每種狀況下采取最佳行動(dòng)的一種策略),使預(yù)期總回報(bào)最大化。
強(qiáng)化學(xué)習(xí)的一個(gè)非常經(jīng)典的例子是學(xué)習(xí)如何玩游戲的代理。在一個(gè)事件中,代理會(huì)測(cè)試所有遇到狀態(tài)中的操作并收集獎(jiǎng)勵(lì)。算法校正策略以減少非積極行為(即獎(jiǎng)勵(lì)為正的行為)的可能性,并增加在事件結(jié)束時(shí)可獲得的預(yù)期總獎(jiǎng)勵(lì)。
強(qiáng)化學(xué)習(xí)有許多有趣的應(yīng)用,這些應(yīng)用并不僅限于游戲。例如推薦系統(tǒng)可以根據(jù)用戶提供的二進(jìn)制反饋(例如拇指向上或向下)來(lái)更正建議。強(qiáng)化學(xué)習(xí)和有監(jiān)督學(xué)習(xí)之間的主要區(qū)別在于環(huán)境提供的信息。事實(shí)上,在有監(jiān)督的場(chǎng)景中,更正通常與其成比例,而在強(qiáng)化學(xué)習(xí)中,必須分析一系列行動(dòng)和未來(lái)的獎(jiǎng)勵(lì)。因此,更正通常基于預(yù)期獎(jiǎng)勵(lì)的估計(jì),并且它們的影響受后續(xù)行動(dòng)的價(jià)值影響。例如有監(jiān)督模型沒有內(nèi)存,因此其更正是立竿見影的,而強(qiáng)化學(xué)習(xí)代理必須考慮一個(gè)事件的部分展開,以決定一個(gè)操作是否是負(fù)的。
強(qiáng)化學(xué)習(xí)是機(jī)器學(xué)習(xí)的一個(gè)有趣分支。遺憾的是,這個(gè)主題超出了本書的范圍,因此我們不會(huì)詳細(xì)討論它(你可以在Hands-On Reinforcement Learning with Python和Mastering Machine Learning Algorithms中找到更多細(xì)節(jié))。
本文摘自:《Python無(wú)監(jiān)督學(xué)習(xí)》

本書需要你有機(jī)器學(xué)習(xí)和Python編程的基本知識(shí)。此外,為了充分理解書中所有的理論,還需要你了解大學(xué)階段的概率論、微積分和線性代數(shù)等相關(guān)知識(shí)。但是,不熟悉這些知識(shí)的讀者也可以跳過數(shù)學(xué)討論,只關(guān)注實(shí)踐方面的內(nèi)容。在需要時(shí),你可以參考相關(guān)論文和書籍,以便更深入地理解復(fù)雜的概念。
本書通過Python語(yǔ)言講解無(wú)監(jiān)督學(xué)習(xí),全書內(nèi)容包括10章,前面9章由淺入深地講解了無(wú)監(jiān)督學(xué)習(xí)的基礎(chǔ)知識(shí)、聚類的基礎(chǔ)知識(shí)、高級(jí)聚類、層次聚類、軟聚類和高斯混合模型、異常檢測(cè)、降維和分量分析、無(wú)監(jiān)督神經(jīng)網(wǎng)絡(luò)模型、生成式對(duì)抗網(wǎng)絡(luò)和自組織映射,第10章以問題解答的形式對(duì)前面9章涉及的問題給出了解決方案。





