
數據可視化可深入了解數據集中變量之間的分布和關系。
此洞察力有助于選擇在建模之前應用的數據準備以及最適合數據的算法類型。
Seaborn 是 Python 的數據可視化庫,它在流行的 Matplotlib 數據可視化庫之上運行,并且提供了簡單的界面和美觀的圖形。

本文對機器學習中的 Seaborn 數據可視化作了簡要介紹。
看完本文,你將知道:
- 如何使用條形圖,直方圖以及箱形圖來總結變量的分布。
- 如何使用線圖和散點圖總結關系。
- 如何比較同一圖上不同類別值的變量的分布和關系。
概述
本教程分為六個部分:
- Seaborn數據可視化庫
- 線圖
- 條形圖
- 直方圖
- 箱形圖
- 散點圖
Seaborn數據可視化庫
Python 的主要繪圖庫稱為 Matplotlib 。
Seaborn 是一個繪圖庫,它不僅提供了一個更簡單的界面,為機器學習所需的繪圖提供了合理的默認值,而且最重要的是,這些繪圖在外觀上比 Matplotlib 更好。
Seaborn 要求首先安裝 Matplotlib。
我們可以使用 pip 直接安裝 Matplotlib ,如下所示:
sudo pip install matplotlib
安裝后,可以通過輸出版本號來確認可以加載和使用該庫,如下所示:
# matplotlib
import matplotlib
print('matplotlib: %s' % matplotlib.__version__)
我們可以得到 Matplotlib 庫的當前版本。
matplotlib: 3.1.2
接下來,也可以使用 pip 安裝 Seaborn 庫:
sudo pip install seaborn
安裝好后,我們還可以通過打印版本號來確認可以加載和使用該庫,如下所示:
# seaborn
import seaborn
print('seaborn: %s' % seaborn.__version__)
運行示例將打印Seaborn庫的當前版本。
seaborn: 0.10.0
要創建 Seaborn 可視化圖形,必須導入 Seaborn 庫并調用函數來創建圖。
重要的是,Seaborn 繪圖功能希望將數據作為 Pandas 數據幀提供。這意味著,如果你要從CSV文件加載數據,則必須使用 read_csv()之類的 Pandas 函數將數據作為數據幀加載。繪制時,可以通過數據幀名稱或列索引指定列。
要顯示該圖,可以在 Matplotlib 庫上調用 show()函數。
...
# 顯示圖表
pyplot.show()
或者,可以將圖保存到文件,例如 PNG 格式的圖像文件。savefig()函數 Matplotlib 可用于保存圖像。
...
# 保存圖表
pyplot.savefig('my_image.png')
現在我們已經安裝好 Seaborn 了,讓我們看一下使用機器學習數據時可能需要的一些常見可視化圖表。
線圖
我們一般使用線圖來呈現定期收集的數據觀察結果。
x 軸表示規則間隔,例如時間。y 軸顯示觀測值,按 x 軸排序并通過一條線連接。
可以通過調用 lineplot()函數并在常規間隔中傳遞 x 軸數據和觀察值的 y 軸來在 Seaborn 中創建線圖。
我們可以使用每月汽車銷售的時間序列數據集來演示折線圖。
Github數據集鏈接:https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv
數據集有兩列:“ 月 ”和“ 銷售”。月將用作 x 軸,銷售量將繪制在 y 軸上。
...
# 創建線圖
lineplot(x='Month', y='Sales', data=dataset)
完整示例如下:
#時間序列數據集的線圖
from pandas import read_csv
from seaborn import lineplot
from matplotlib import pyplot
# 加載數據集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv'
dataset = read_csv(url, header=0)
# 創建線圖
lineplot(x='Month', y='Sales', data=dataset)
# 顯示線圖
pyplot.show()
首先運行示例將加載時間序列數據集并創建數據的折線圖,以清楚地顯示銷售數據中的趨勢和季節性。
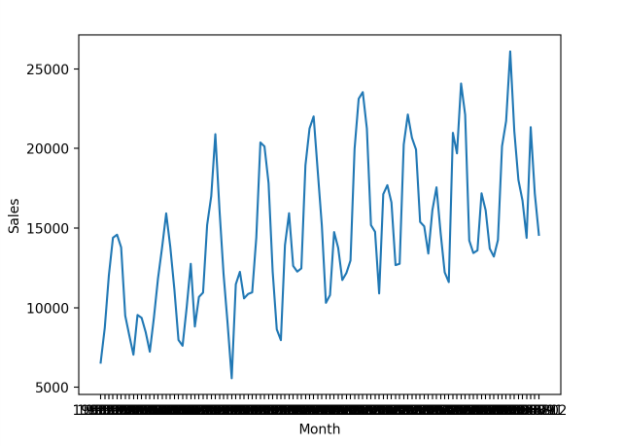
時間序列數據集的線圖
條形圖
條形圖通常用于顯示多個類別的相對數量。
x 軸代表均勻分布的類別。y 軸代表每種類別的數量,并以條形圖從基線到 y 軸上的適當水平繪制。
可以通過調用 countplot()函數并傳遞數據來在 Seaborn 中創建條形圖。
我們將展示條形圖,其中包含來自乳腺癌分類數據集的變量,該變量由分類輸入變量組成。
乳腺癌分類數據集鏈接:https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv
我們只繪制一個變量,在這種情況下,第一個變量是年齡段。
...
# 創建線圖
countplot(x=0, data=dataset)
完整示例代碼如下:
#分類變量的條形圖
from pandas import read_csv
from seaborn import countplot
from matplotlib import pyplot
#加載數據集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv'
dataset = read_csv(url, header=None)
# 創建條形圖
countplot(x=0, data=dataset)
# 顯示條形圖
pyplot.show()
首先運行示例將加載乳腺癌數據集并創建數據的條形圖,以顯示每個年齡組以及可及范圍內的個體(樣本)數量。
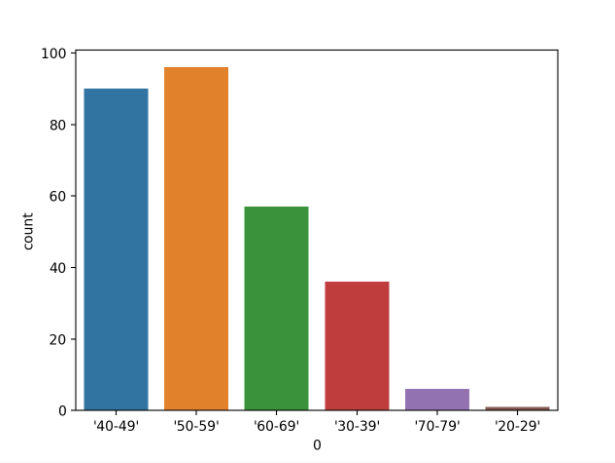
年齡范圍分類變量的條形圖
此外,如果我們還想針對類標簽繪制變量(例如第一個變量)的每個類別的計數。
可以通過使用 countplot()函數并通過“ hue ”參數指定類變量來實現,如下所示:
...
# 創建條形圖
countplot(x=0, hue=9, data=dataset)
完整示例代碼如下:
# 分類變量與類變量的條形圖
from pandas import read_csv
from seaborn import countplot
from matplotlib import pyplot
# 加載數據集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/breast-cancer.csv'
dataset = read_csv(url, header=None)
# 創建條形圖
countplot(x=0, hue=9, data=dataset)
# 顯示條形圖
pyplot.show()
首先運行示例將加載乳腺癌數據集,并創建數據的條形圖,以顯示每個年齡組以及屬于每個組的個體(樣本)數量(由數據集的兩個類別標簽分隔)。
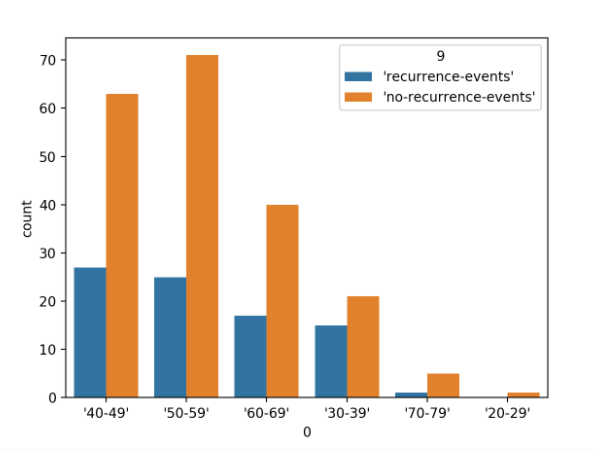
按類別標簽劃分的年齡范圍分類變量的條形圖
直方圖
直方圖通常用于總結數值數據樣本的分布。
x 軸表示觀測值的離散區間或間隔。例如,值介于 1 到 10 之間的觀測值可以分為五個 bin,值 [1,2] 將分配給第一個 bin,[3,4] 將分配給第二個 bin,依此類推。
y 軸表示數據集中屬于每個 bin 的觀測值的頻率或計數。
本質上,數據樣本被轉換為條形圖,其中 x 軸上的每個類別都代表觀察值的間隔。
可以通過調用 distplot()函數并傳遞變量來在 Seaborn 中創建直方圖。
我們將展示一個帶有糖尿病分類數據集中數值變量的箱線圖。我們只繪制一個變量,在這種情況下,是第一個變量,即患者懷孕的次數。
糖尿病分類數據集:https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv
...
# 創建直方圖
distplot(dataset[[0]])
完整示例代碼如下:
# 數值變量的直方圖
from pandas import read_csv
from seaborn import distplot
from matplotlib import pyplot
# 加載數據集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
# 創建直方圖
distplot(dataset[[0]])
# 顯示直方圖
pyplot.show()
首先運行示例將加載糖尿病數據集并創建變量的直方圖,以硬截止值為零的形式顯示值的分布。
該圖顯示了直方圖(bin的數量)以及概率密度函數的平滑估計。
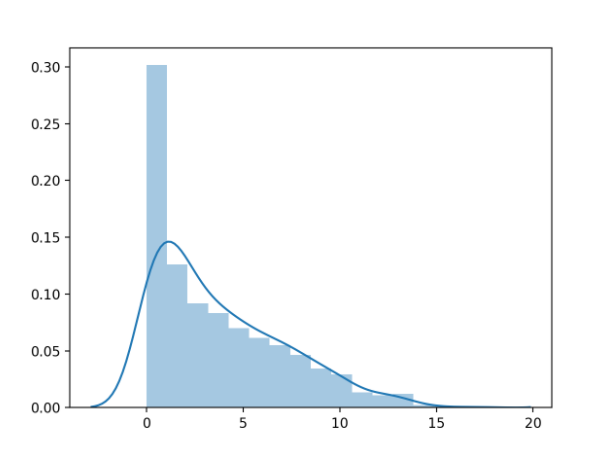
懷孕次數直方圖
箱形圖
通常使用箱形圖來概括數據樣本的分布。
x 軸用于表示數據樣本,如果需要,可以在 x 軸上并排繪制多個箱形圖。
y 軸表示觀測值。繪制一個方框來匯總數據集中的中間 50%數據,從觀察值的第 25 個百分位數開始,到第 75 個百分位數為止。這稱為四分位間距或 IQR。用一條線繪制中位數或第 50 個百分位數。
從盒子的兩端開始繪制稱為須狀的線,計算公式為(1.5 * IQR),以顯示分布中合理值的預期范圍。晶須外的觀測值可能是異常值,并用小圓圈繪制。
可以通過調用 boxplot()函數并傳遞數據來在 Seaborn 中創建一個箱線圖。
我們將展示一個帶有糖尿病分類數據集中數值變量的箱線圖。我們只繪制一個變量,在這種情況下,是第一個變量,即患者懷孕的次數。
...
# 創建箱形圖
boxplot(x=0, data=dataset)
完整示例代碼如下:
# 數值變量的箱型圖
from pandas import read_csv
from seaborn import boxplot
from matplotlib import pyplot
# 加載數據集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
# 創建箱形圖
boxplot(x=0, data=dataset)
# 顯示箱形圖
pyplot.show()
首先運行示例,加載糖尿病數據集,并創建第一個輸入變量的箱形圖,以顯示患者懷孕次數的分布。
我們可以看到中位數略高于2.5倍,一些離群值上升了15倍左右。
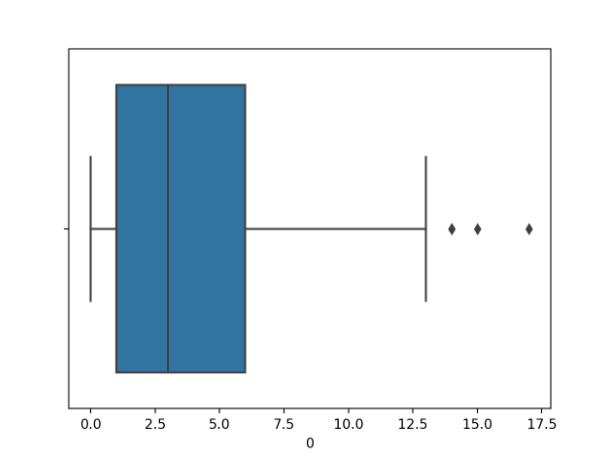
懷孕次數箱形圖
此外,如果我們還想針對類別標簽針對類別變量(例如第一個變量)的每個值繪制數字變量的分布。
可以通過調用 boxplot()函數并將 class 變量作為 x 軸和數值變量作為 y 軸來實現。
...
# 創建箱形圖
boxplot(x=8, y=0, data=dataset)
完整示例代碼如下:
#數值變量與類標簽的箱形圖
from pandas import read_csv
from seaborn import boxplot
from matplotlib import pyplot
# 加載數據集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
# 創建箱形圖
boxplot(x=8, y=0, data=dataset)
# 顯示箱形圖
pyplot.show()
首先運行示例將加載糖尿病數據集并創建數據的箱形圖,將懷孕次數的分布作為兩個類標簽的數值變量。
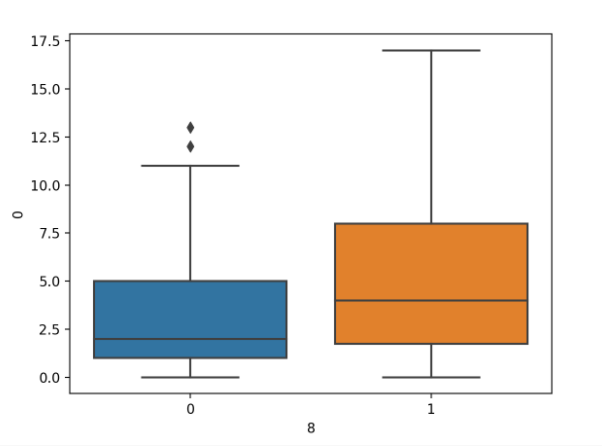
分類標簽的懷孕次數箱形圖
散點圖
散點圖或散點圖通常用于總結兩個配對數據樣本之間的關系。
配對的數據樣本意味著針對給定的觀察記錄了兩個度量,例如一個人的體重和身高。
x 軸代表第一樣品的觀察值,y 軸代表第二樣品的觀察值。圖上的每個點代表一個觀察值。
可以通過調用 scatterplot()函數并傳遞兩個數值變量來在 Seaborn 中創建散點圖。
我們將展示一個散點圖,其中包含來自糖尿病分類數據集的兩個數值變量。我們將繪制第一個變量與第二個變量的關系圖,在這種情況下,第一個變量是患者懷孕的次數,第二個變量是口服糖耐量測試兩小時后的血漿葡萄糖濃度。
糖尿病分類數據集:https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv
...
# 創建散點圖
scatterplot(x=0, y=1, data=dataset)
完整示例代碼如下:
# 兩個數值變量的散點圖
from pandas import read_csv
from seaborn import scatterplot
from matplotlib import pyplot
#加載數據集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
#創建散點圖
scatterplot(x=0, y=1, data=dataset)
# 顯示散點圖
pyplot.show()
首先運行示例將加載糖尿病數據集并創建前兩個輸入變量的散點圖。
我們可以看到兩個變量之間的關系有些統一。
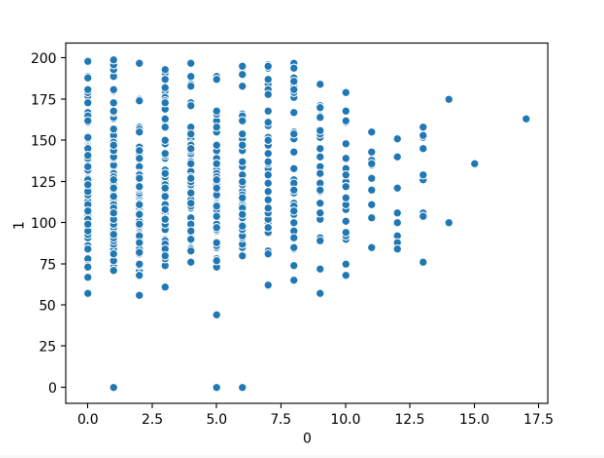
懷孕次數與血漿葡萄糖數值變量散點圖
我們可能還想針對類標簽繪制一對數字變量的關系。
這可以使用 scatterplot()函數并通過“ hue ”參數指定類變量來實現,如下所示:
...
# 創建散點圖
scatterplot(x=0, y=1, hue=8, data=dataset)
完整示例代碼如下:
# 兩個數值變量與類標簽的散點圖
from pandas import read_csv
from seaborn import scatterplot
from matplotlib import pyplot
# 加載數據集
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv'
dataset = read_csv(url, header=None)
# 創建散點圖
scatterplot(x=0, y=1, hue=8, data=dataset)
# 顯示散點圖
pyplot.show()
首先運行示例將加載糖尿病數據集,并創建前兩個變量與類標簽的散點圖。
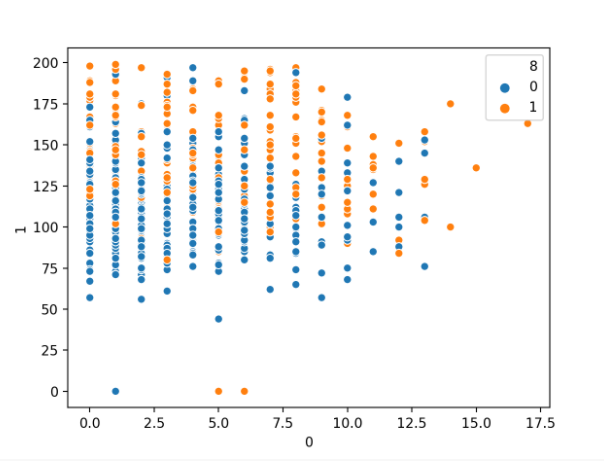
按類別標簽劃分的懷孕次數與血漿葡萄糖數值變量散點圖





