

據(jù)思科統(tǒng)計數(shù)據(jù),互聯(lián)網視頻流在網絡帶寬中占有很大份額,到2022年將增長到消費互聯(lián)網流量的82%以上。視頻服務已經成為人們生活中不可或缺的一部分。
為了克服網絡抖動帶來不必要的播放卡頓,自適應多碼率被公認為最有效的手段之一,例如MPEG-DASH、Apple的HLS、快手的LAS等。ABR算法自適應多碼率方案的核心,依據(jù)網絡狀態(tài)、播放狀態(tài)等信息,動態(tài)調整請求視頻流的清晰度(碼率),從而在流暢度、清晰度和平滑性上取得平衡,最大化用戶體驗。
ABR算法可以分為兩大類,一類是基于啟發(fā)式的策略,通過建立各種模型或規(guī)則來控制碼率的選擇,然而這些算法通常需要仔細調參以適應多變的網絡環(huán)境。另一類則是采用機器學習的方式,讓播放器通過與現(xiàn)實中的網絡交互,“自主地”學習出一個適應當前網絡狀態(tài)的ABR算法。
任何算法在落地前都需要經歷漫長從理論到實踐的調試與優(yōu)化,特別是解決各種各樣“實驗室中認為不重要但是在落地階段非常重要”的問題。
鑒此,快手音視頻技術部聯(lián)合清華大學孫立峰教授團隊對基于學習的ABR算法在兩方面進行了研究和改進,并分別發(fā)表在國際頂級會議IEEE INFOCOM 2020與國際頂級期刊IEEE JSAC。
論文地址:https://ieeexplore.ieee.org/abstract/document/9109427
1
自適應多碼率
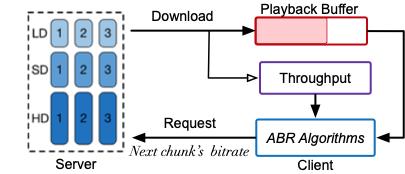
圖1 碼率自適應傳輸架構圖
自適應多碼率的傳輸架構分為基于分片(MPEFG-DASH、HLS)和基于流式(LAS)兩類,本文以基于分片為例,如圖1所示:視頻在發(fā)布前,會先進行切片和轉碼,得到不同碼率和清晰的分片,在客戶端,每次當當前切片下載完成時,客戶端上的ABR算法將綜合考慮帶寬、緩沖情況以及用戶信息等信息,選擇下一個切片的碼率,從而實現(xiàn)自適應,提升用戶的體驗(QoE)。用戶的QoE通常由以下指標組成(如公式1所示)。
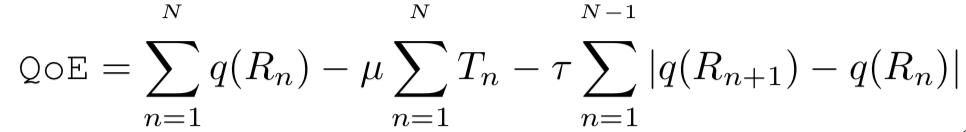
公式1 自適應碼率傳輸中的QoE定義
其中代表視頻的碼率,代表視頻的卡頓時長,最后一項為平滑項:即不希望視頻碼率頻繁切換。μ和τ為懲罰系數(shù)。對ABR算法來說,該優(yōu)化是一種長時優(yōu)化(long-term optimization)。例如在某個時刻ABR算法“貪心地”選擇了高碼率,然而網絡在之后變差了,導致之后幾個時刻ABR算法都只能“被迫”選擇較低的碼率或造成卡頓,那么綜合來說,這次選擇就是不合適的。
2
基于學習的ABR
機器學習是否能解決這個問題呢?答案是肯定的。例如Pensieve(SIGCOMM'17)將碼率自適應過程建模為了一個馬爾可夫決策過程(MDP),并使用深度強化學習算法(Deep Reinforcement Learning, DRL) 從零開始訓練,最終學習到的策略在QoE指標上超越了過去最優(yōu)算法18%。然而,盡管Pensieve在“性能”上獲得了巨大的突破,但是該算法由于諸多限制很難在現(xiàn)實中部署:
-
開銷:為了減少客戶端上的開銷,Pensieve將整個模型推理放在了服務器上,并作為服務運行。然而在實際部署中,大多數(shù)的ABR算法部署在客戶端上以避免額外的消耗,例如端到端延遲,服務器上作為服務的消耗等。故如何進一步從機理上降低模型的開銷將成為其部署的一大挑戰(zhàn)。
-
效率:Pensieve使用強化學習算法進行訓練,通常需要至少8小時才能訓練收斂一個策略。如何改善訓練效率,使其始終能適應當前網絡狀態(tài)是ABR任務的另一大挑戰(zhàn)。
1、結合領域知識,降低整體開銷
面對第一個挑戰(zhàn),我們提出了“結合領域知識”這一概念。基本動機是:雖然AlphaZero等突破性的算法在摒棄了人類領域知識后獲得了更高的水準。但是考慮到ABR算法是一個“狀態(tài),動作空間較小,物理意義明確”的任務,是否過去優(yōu)秀的ABR算法已經挖掘出足夠的“領域特征了”?

圖2 BBA算法原理介紹
BBA(Buffer-Based Approach,SIGCOMM’14)是優(yōu)秀的代表之一,其原理如圖2所示。BBA算法內部有兩個閾值(RESEVIOR和CUSHION)。在當前緩沖小于閾值RESEVIOR時(偏左的紅色虛線),BBA算法恒選擇最小的視頻碼率;當緩沖區(qū)儲存的視頻時長大于RESEVIOR+CUSHION(偏右的紅色虛線)時,BBA會選擇最大的視頻碼率;在緩沖區(qū)處于其他狀態(tài)下時,BBA算法會使用線性擬合的方式,根據(jù)當前的緩沖選擇一個適合的視頻碼率。由此可知,BBA算法的性能非常依賴RESEVIOR和CUSHION這兩個值的取值。在本文中,我們嘗試是否可以將BBA算法和基于學習的算法可以有機地結合在一起,即,我們能通過深度學習方法增強BBA算法,與此同時,BBA算法又能給學習算法帶來更多的領域知識,從而降低模型開銷。
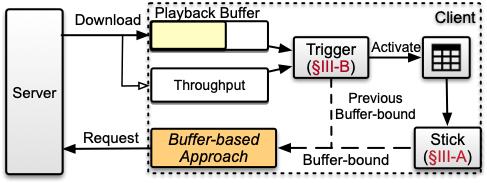
圖3 Stick系統(tǒng)架構圖
我們提出了Stick,一種融合了傳統(tǒng)基于緩沖區(qū)方法和基于學習的方法的自適應碼率方案。該方案的系統(tǒng)框架圖如圖3所示,模塊主要由兩大部分組成,分別是:1) 基本Stick模塊。該模塊主要利用一個線下訓練完的神經網絡,根據(jù)當前客戶端接收的狀態(tài)輸出連續(xù)值,該值用于控制傳統(tǒng)的BBA算法的閾值。2) Trigger模塊。Trigger模塊是一個輕量級的神經網絡,部署在Stick啟動之前,用于決策是否開啟基本Stick模塊,從而進一步降低Stick神經網絡的整體開銷。

圖4 Stick神經網絡結構
Stick模塊:采用連續(xù)值下的深度強化學習算法DDPG來訓練神經網絡,將過去的碼率決策,過去一段時間的帶寬大小,下載時長,未來視頻大小,剩余時長,當前緩沖區(qū)大小等輸入神經網絡,并輸出一個單值,代表允許下最大碼率的緩沖值。隨后我們采用經典的BBA方案,該值將被擴展為一個緩沖表,用于決策每一個緩沖下的對應下載碼率。之后的實驗表明,運用領域知識可以大幅度降低神經網絡的開銷,最高可將模型大小縮減88%。
Trigger模塊:在使用領域知識縮減了模型大小后,我們進一步通過實驗挖掘出BBA的潛力:由于Stick使用緩沖表去選擇碼率,很明顯,它比一般的輸出攜帶了更多的信息,所以在大多數(shù)網絡情況下,只有30%到40%的情形需要去開啟Stick神經網絡去推端新的閾值,在其他時候,只需要沿用上一個閾值即可。故我們可以在Stick神經網絡之前再部署一個非常輕量級的小型神經網絡,使用簡單的結構決定是否需要更新當前閾值參數(shù)。在此我們使用的模仿學習,即在訓練時實時求解最優(yōu)解并引導神經網絡漸漸“靠近”最優(yōu)策略。
實驗結果:我們比較了Stick與經典的buffer-based算法(包括BBA和BOLA)的性能,結果表明Stick分別提升了44.26%和25.93%的QoE。隨后在進一步和過去多個算法的比較中,Stick也表現(xiàn)出了更好的性能,總體提升了3.5%-25.86%的QoE。于此同時,與Pensieve相比,Stick減少了88%的模型開銷。
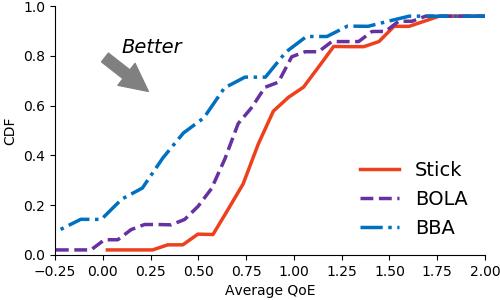
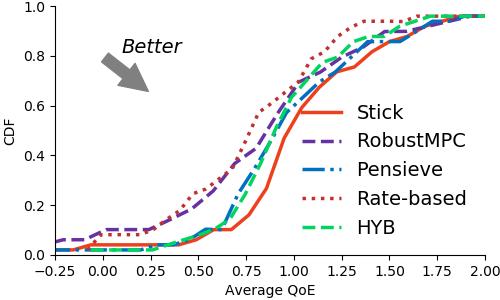
圖5 Stick實驗結果
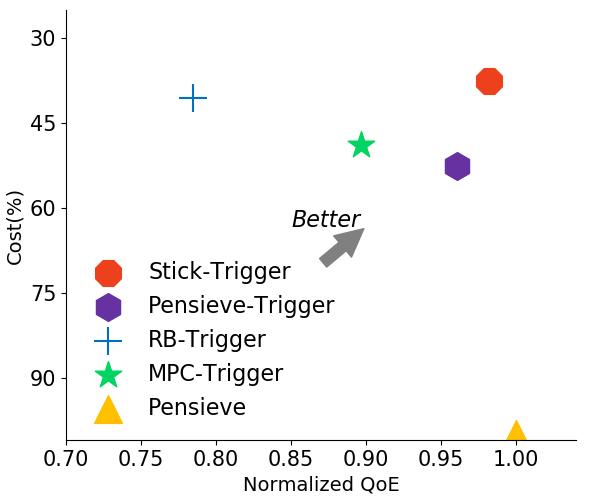
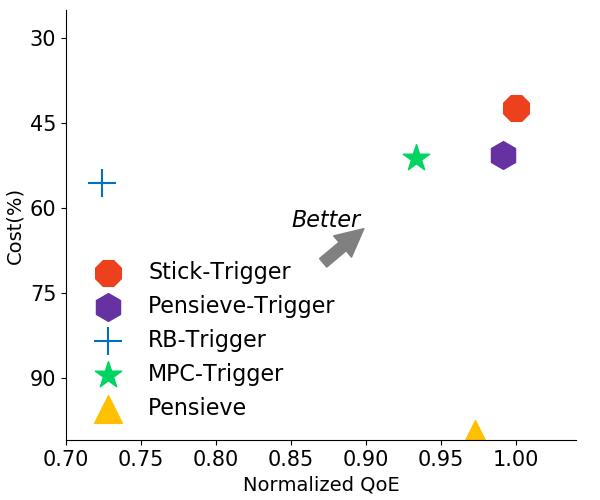
圖6 Trigger實驗結果
我們隨后對Trigger三個不同的數(shù)據(jù)集上進行了實驗測試。結果表明Trigger會明顯減少Stick的綜合開銷,總體節(jié)省幅度在39%-61%。此外我們可以看到Trigger甚至幫助過去的一些經典算法提升了性能,包括Rate-based和經過改進的Pensieve。
更詳細的內容請參考我們的IEEE INFOCOM2020的論文《Stick: A Harmonious Fusion of Buffer-based and Learning-based Approach for Adaptive Streaming》。
2、改善訓練效率,在線終身學習
第二個挑戰(zhàn)來自強化學習的低訓練效率。在強化學習方案中,智能體通過與環(huán)境交互獲得{狀態(tài),動作,回報}集合,隨后通過學習增大每次動作獲得的回報。然而,在學習過程中,智能體無法獲取在當前狀態(tài)下的最優(yōu)動作,因此不能為神經網絡提供準確的梯度方向更新,基于強化學習的ABR算法也遭受著這個缺點。

圖7 LifeLong-Comyco系統(tǒng)架構
針對這些問題,我們提出了Lifelong-Comyco,一種終身模仿學習的ABR算法。Lifelong-Comyco的系統(tǒng)架構如圖7所示。該系統(tǒng)由外循環(huán)系統(tǒng)(Outer-loop)和內循環(huán)(Inner-loop)系統(tǒng)兩部分組成。其中內循環(huán)系統(tǒng)使用模仿學習方法更快更有效地從專家序列中學到策略;外循環(huán)系統(tǒng)則給予了系統(tǒng)持續(xù)更新能力,采用終身學習的方式自主“查缺補漏”,學習有必要的數(shù)據(jù)。該系統(tǒng)的系統(tǒng)流程為:在視頻開始之前,位于客戶端的視頻播放器從ABR模型服務器下載最新的神經網絡模型。每次當視頻在客戶端上播放完成后,播放器將通過過去的下載塊大小和下載時間生成帶寬數(shù)據(jù)。隨后,收集到的帶寬數(shù)據(jù)將被提交到位于服務器端的外循環(huán)系統(tǒng)。外環(huán)系統(tǒng)將即時估計當前策略與最優(yōu)策略之間的差距。根據(jù)該差距,我們可以確定該網絡帶寬數(shù)據(jù)是否需要加入訓練集中。隨后在每個時間段(例如1小時),在內循環(huán)系統(tǒng)將被調用并通過終身模仿學習有效地更新神經網絡。最后,每隔一段時間,我們會將訓練好的模型凍結并提交給ABR模型服務器。

圖8 內循環(huán)系統(tǒng)架構
內循環(huán)系統(tǒng):在內循環(huán)系統(tǒng)中,我們充分利用了自適應碼率任務的特點,即可以通過線下模擬器,在給定的網絡和視頻的條件下準確地判斷出當前的最優(yōu)或者接近最優(yōu)的解。在獲取到最優(yōu)解后,我們便可以使用傳統(tǒng)的監(jiān)督學習方法高效地對神經網絡進行更新。大致方法如下:首先,我們使用蒙特卡洛采樣,即從相同的狀態(tài)開始,將過程推演到N步之后。隨后我們選擇得到地QoE得分最高地那條軌跡中地第一個選擇作為未來地碼率選擇。之后,我們將{狀態(tài),最優(yōu)選擇}保存入經驗池中。最后,每次訓練開啟,我們需要訓練的智能體就會從經驗池中隨機選出數(shù)據(jù)進行訓練。這里我們可以注意到,與強化學習不同,模仿學習做到了采樣和訓練解耦,從而更能提升并行效率,達到高效訓練。

圖9 外循環(huán)系統(tǒng)架構
外循環(huán)系統(tǒng):外循環(huán)子系統(tǒng)的核心思想是進一步減少訓練時所需地訓練集。我們會先對客戶端上報的帶寬數(shù)據(jù)進行整理,核算線下最優(yōu)解。隨后我們查看當前線上策略與線下最優(yōu)解所取得的QoE的差距,當差距超過某個值時,我們會將當前帶寬數(shù)據(jù)放入要訓練的數(shù)據(jù)集中。最后,我們會采用終身學習的訓練方法訓練神經網絡,這是一種經典的主動學習(Active Learning)方案,可以在不忘記過去表現(xiàn)良好的帶寬數(shù)據(jù)的情況下,記住表現(xiàn)不好的帶寬數(shù)據(jù)。
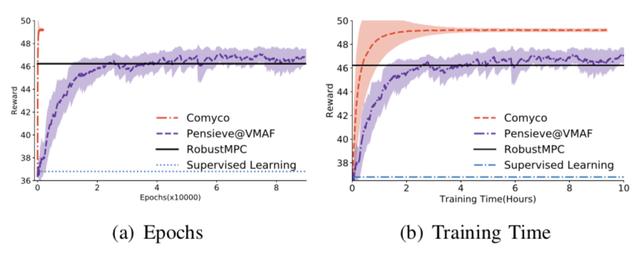
圖13 內循環(huán)系統(tǒng)訓練曲線
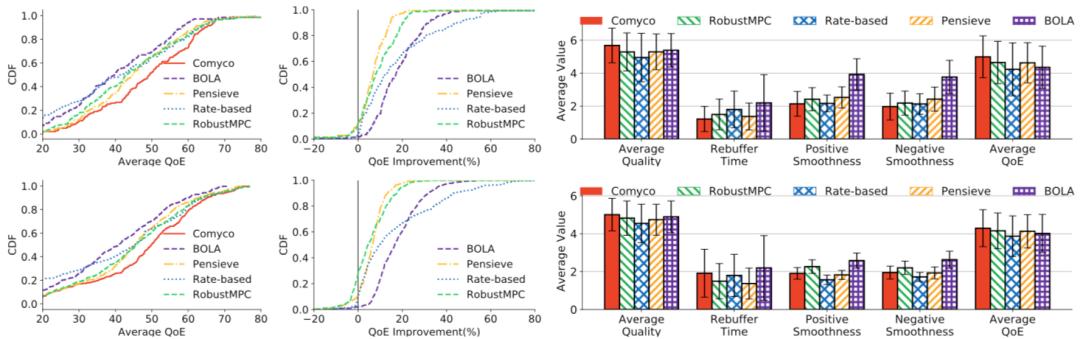
圖14 內循環(huán)系統(tǒng)實驗結果。算法在FCC和HSDPA數(shù)據(jù)集上進行了細致地測試
實驗結果:首先我們測試了內循環(huán)系統(tǒng)訓練出的神經網絡的性能。如圖10 所示,我們看到了模仿學習有效并快速的學習到了更好的策略:整體訓練步數(shù)相較于強化學習的訓練步數(shù)減少了1700倍,同時,整體訓練時長減少了16倍。于此同時算法的整體性能還有提升。在HSDPA數(shù)據(jù)集上,我們測得模仿學習訓練處的策略比過去的方法高出了7.5%-17.99%的QoE。
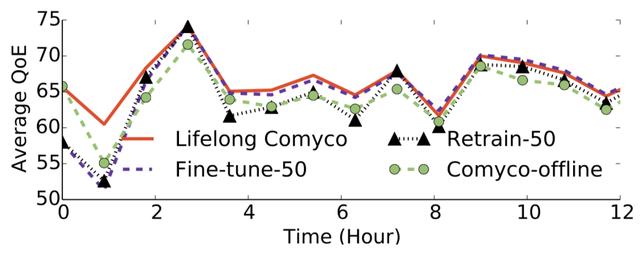
圖15 外循環(huán)系統(tǒng)實驗結果
隨后我們對外循環(huán)系統(tǒng)進行了測試。測試數(shù)據(jù)是我們搜集12小時帶寬序列數(shù)據(jù)。我們會在整點對神經網絡進行更新,并在其他時候記錄需要使用的帶寬數(shù)據(jù)集。實驗結果表示,使用終身學習算法將有效避免災難性遺忘問題,并且能夠跟隨網絡分布的變化實時更新自己的策略,使其性能用于處于較好的狀態(tài)。反觀其他算法,包括實時fine-tune,重新訓練,與只是用內循環(huán)系統(tǒng),都不能很好地做到這一點。實驗表明,使用外循環(huán)系統(tǒng)更新能比只使用內循環(huán)系統(tǒng)的方案再高出1.07%到9.81%的性能。
更詳細的內容請參考我們的JSAC的論文《Quality-aware Neural Adaptive Video Streaming with Lifelong Imitation Learning》。
3
結語
基于機器學習的ABR算法在落地上還有很多的內容需要被探索,包括可解釋性,魯棒性,以及更小巧的模型等。快手有完善的數(shù)據(jù)集、AB測試平臺、優(yōu)秀的算法團隊,非常歡迎各位同行、學者和我們一起研究、探討、合作,做落地有效的算法,提升用戶體驗。





