
k8s極簡史
Docker和K8S已經是當下運維的必備技能,無論是行業技能要求還是前沿技術領域,現在還不能很好掌握這兩門技術的技術人員,在新一輪的技術迭代中將最終被拋棄。
LXC

AA6FB025-6CB8-4A96-B91D-702CD632331B
Docker其實是一門容器化技術,也是虛擬化技術的一種,只是相對傳統的kvm,xen,vmware虛擬化技術而言,是基于進程級別的虛擬化技術,更為輕量,因而性能損耗更小。
虛擬化技術并不是一門新技術,最小可以追溯到LXC技術!
LXC為linux Container的簡寫。可以提供輕量級的虛擬化,以便隔離進程和資源,而且不需要提供指令解釋機制以及全虛擬化的其他復雜性。相當于C++中的NameSpace。容器有效地將由單個操作系統管理的資源劃分到孤立的組中,以更好地在孤立的組之間平衡有沖突的資源使用需求。與傳統虛擬化技術相比,它的優勢在于:
- 與宿主機使用同一個內核,性能損耗小;
- 不需要指令級模擬;
- 不需要即時(Just-in-time)編譯;
- 容器可以在CPU核心的本地運行指令,不需要任何專門的解釋機制;
- 避免了準虛擬化和系統調用替換中的復雜性;
- 輕量級隔離,在隔離的同時還提供共享機制,以實現容器與宿主機的資源共享。
總結:Linux Container是一種輕量級的虛擬化的手段,提供了在單一可控主機節點上支持多個相互隔離的server container同時執行的機制。Linux Container有點像chroot,提供了一個擁有自己進程和網絡空間的虛擬環境,但又有別于虛擬機,因為LXC是一種操作系統層次上的資源的虛擬化
這里衍生出來另外一個問題?LXC技術最早可以追溯到20世紀70年代,計算機系統剛誕生的時代,即LXC和系統是強關聯,為什么一直到2010年左右才開始在歷史舞臺大紫大紅呢?
這里其實要講到進程和隔離了。
進程與隔離

進程與隔離
沒有電的電腦只是一堆廢鐵,通了電的電腦只是一堆帶電的廢鐵!! 這句話充分詮釋了操作系統的重要性。
由于計算機只認識二進制 0 和 1,所以無論哪種語言的實現,最后都需要通過某種方式編譯為二進制文件,才能在計算機操作系統中運行起來。
而為了能夠讓這些代碼正常運行,我們還需要數據、代碼運行平臺即操作系統。比如我們這個加法程序所需要的輸入文件。這些數據加上代碼本身的二進制文件,放在磁盤上,就是我們平常所說的一個“程序”,也叫代碼的可執行鏡像(executable image)。
然后,我們就可以在計算機上運行這個程序了。
- 首先,操作系統從“程序”中發現輸入數據保存在一個文件中
- 然后,這些數據就會被加載到內存中待命
- 接著,操作系統又讀取到了計算加法的指令
- 這時,它就需要指示 CPU 完成加法操作。
而 CPU 與內存協作進行加法計算,又會使用寄存器存放數值、內存堆棧保存執行的命令和變量。同時,計算機里還有被打開的文件,以及各種各樣的 I/O 設備在不斷地調用中修改自己的狀態。
就這樣,一旦 程序 被執行起來,它就從磁盤上的二進制文件,變成了計算機內存中的數據、寄存器里的值、堆棧中的指令、被打開的文件,以及各種設備的狀態信息的一個集合。像這樣一個程序運行起來后的計算機執行環境的總和,就是我們今天的主角:進程。
從上面可以看到,操作系統也是進程,只是其無比復雜,復雜到可以把自己“虛擬成平臺”并承載其它進程運行的程序,而操作系統在這個過程中起到兩個非常重要的角色是:資源分配和資源隔離。
資源分配
資源分配
眾所周知,Linux多用戶操作系統,即意味著可以多個同時使用操作系統,但操作系統只有一個大腦(無論是幾個物理核心,其實真正都在同一時間只有一個核心工作,雖然現代多核心技術在多核心協作上做了非常精巧的設計)。
那么操作系統究竟該如何分配資源呢?如圖是top命令的返回,第一列是進程ID,大家可能已經想到了,就是進程ID. 進程ID越小,優先級越高。進程ID是系統判斷資源分配的重要依據 。
當然,現代操作系統都是并行性操作系統,想像這么一個場景:如果有多個進程都在申請同一塊內存,而另外一個進程一直在占用這塊內存不肯釋放,此時操作系統該怎么辦呢?這種情形稱為“死瑣”,早在2.6版本以前的內核,在資源分配和資源隔離做的并不理想。尤其是資源隔離
資源隔離
資源隔離
程序的正常運行最少需要如下這些資源:
- 網絡資源
- 磁盤資源
- 內存資源
- CPU計算資源
容器化
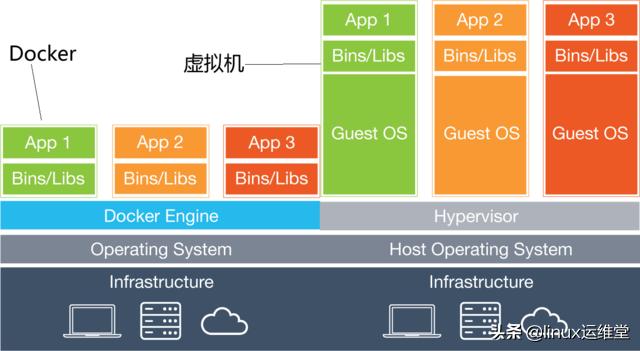
其次還有非常重要的文件系統資源,和傳統虛擬化不同。傳統虛擬化是在磁盤上劃分出來一塊空間,在此空間上虛擬一個完整的操作系統,所有的資源與真實主機隔離。隔離安全性有保障,但性能損失不容忽視。
而Docker容器化不同的地方是Docker并不是一個操作系統,而只是真實物理機操作系統中的一個進程,通過該進程來調用內核資源,使用rootfs文件系統技術和cgroup隔離動技術,實現資源隔離。
性能幾乎無損耗,但隔離技術門檻較高,且3.10之前的內核版本不支持。時至今日,Docker在虛擬化隔離也不能做到安全性100%。
介紹這么多,大家千萬不要誤解是因為Docker性能損耗少所以大紅大紫,真正促使Docker如日中天的原因其實是PAAS的發展
DOCKER

docker
從本世紀初開始,云計算的呼聲不斷,到2009年王堅博士“騙”了馬云10個億創建阿里云,到現在阿里3年2000億、騰訊5年5000億在新基建的大力投入,不過短短20年時間。從早期的AWS,azure外資獨大,到現在阿里、騰訊、華為云獨占云市場鰲頭,如日中天的AWS和盛極一時的OpenStack,帶動整個IT產品邁向PAAS時代.
但事情的發展總不以人的意識為導向。在家名為 dotCloud的公司在PAAS的浪潮中堅持不下去,無奈開源他們容器化項目:Docker。
令dotCloud公司自己都沒想到的是,這竟然會讓他們站在浪潮之巔并有機會和RedHat和google一戰雌雄,甚至逼的Google不得不和RedHat合作,并拿出自家核秘密武器Brog卻只為求得生存。
“容器”這個概念從來就不是什么新鮮的東西,也不是 dotCloud 公司發明的。所以dotCloud 開源的決定在當時根本沒人在乎。
PaaS 項目被大家接納的一個主要原因,就是它提供了一種名叫“應用托管”的能力。在當時,虛擬機和云計算已經是比較普遍的技術和服務了,用戶主流用法,就是租一批 AWS 或者 OpenStack 的虛擬機,然后像以前管理物理服務器那樣,用腳本或者手工的方式在這些機器上部署應用。
當然,這個部署過程難免會碰到云端虛擬機和本地環境不一致的問題,所以當時的云計算服務,比的就是誰能更好地模擬本地服務器環境,能帶來更好的“上云”體驗。而 PaaS 開源項目的出現,就是當時解決這個問題的一個最佳方案。
Cloud Foundry是當時 PAAS 的平臺龍頭。在Docker開源時,其產品經理 james Bayer在社區做過詳細對比,并告訴大家 Docker 實際上只是一個同樣使用了 cgroup 和Namespace 的"沙盒"工具而已,并不需要特別關注。
但僅在短短幾個月后,Docker就迅速崛起,速度之快連包括 Cloud Foudry 在內的所有 PAAS 公司沒來得及反應就out了.
而引導這一現象的原因卻僅僅是**Docker的鏡像功能**。
恐怕連 Docker 項目的作者 Solomon Hykes 自己當時都沒想到,這個小小的創新,在短短幾年內就如此迅速地改變了整個云計算領域的發展歷程。
PaaS 之所以能夠幫助用戶大規模部署應用到集群里,是因為它提供了一套應用打包的功能。可偏偏就是這個打包功能,卻成了 PaaS日后不斷遭到用戶詬病的一個“軟肋”。
用戶一旦使用了 PaaS,就必須為每種語言、每種框架,甚至每個版本的應用維護一個打好的包。這個打包過程,沒有任何章法可循,更麻煩的是,明明在本地運行得好好的應用,卻需要做很多修改和配置工作才能在 PaaS 里運行起來。而這些修改和配置,并沒有什么經驗可以借鑒,基本上得靠不斷試錯,直到你摸清楚了本地應用和遠端 PaaS 匹配的“脾氣”才能夠搞定。
而 Docker 鏡像解決的,恰恰就是打包這個根本性的問題
就這樣,容器化的時代開始了!
K8S

k8s
那Docker和k8s又有什么關系呢?
前面介紹,Docker 項目一日千里的發展勢頭,但用戶們最終要部署的,還是他們的網站、服務、數據庫,甚至是云計算業務。
這就意味著,只有那些能夠為用戶提供平臺層能力的工具,才會真正成為開發者們關心和愿意付費的產品。而 Docker 項目這樣一個只能用來創建和啟停容器的小工具,最終只能充當這些平臺項目的“幕后英雄”。
即要想Docker能大面積普及,還需要解決大量Docker的協作編排問題。
談到Docker容器編排問題,就不得不說說 Docker 公司的老朋友和老對手 CoreOS 了。CoreOS 是一個基礎設施領域創業公司。它的核心產品是一個定制化的操作系統,用戶可以按照分布式集群的方式,管理所有安裝了這個操作系統的節點。從而,用戶在集群里部署和管理應用就像使用單機一樣方便了.
Docker 項目發布后,CoreOS 公司很快就認識到可以把“容器”的概念無縫集成到自己的這套方案中,從而為用戶提供更高層次的 PaaS 能力。所以,CoreOS 很早就成了 Docker 項目的貢獻者,并在短時間內成為了 Docker 項目中第二重要的力量。
然而,這段短暫的蜜月期到 2014 年底就草草結束了。CoreOS 公司以強烈的措辭宣布與 Docker 公司停止合作,并直接推出了自己研制的 Rocket(后來叫 rkt)容器。
這次決裂的根本原因,正是源于 Docker 公司對 Docker項目定位的不滿足。Docker 公司解決這種不滿足的方法就是,讓 Docker 項目提供更多的平臺層能力,即向 PaaS 項目進化。而這,顯然與 CoreOS 公司的核心產品和戰略發生了嚴重沖突。
大紅大紫不差錢的 Docker 開始大私收購來完善自己的生態和平臺能力。最出名的莫過于 Fig項目,即現在的 Compose,除此外,還有 SocketPlane, Flocker, Tutum等項目。
Docker的異常繁榮終于引起了行業巨頭的關注。
作為 Docker 項目早期的重要貢獻者,RedHat 也是因為對 Docker 公司平臺化戰略不滿而憤憤退出。但此時,它竟只剩下 OpenShift 這個跟 Cloud Foundry 同時代的經典 PaaS 一張牌可以打,跟 Docker Swarm 和轉型后的 Mesos完全不在同一個“競技水平”之上。
2014年6月,基礎設施領域的翹楚 Google 公司突然發力,正式宣告了一個名叫 Kubernetes項目的誕生。而這個項目,不僅挽救了當時的 CoreOS 和 RedHat,還如同當年 Docker項目的橫空出世一樣,再一次改變了整個容器市場的格局。
2015年6月22日,由 Docker 公司牽頭,CoreOS、Google、RedHat 等公司共同宣布,Docker公司將 Libcontainer 捐出,并改名為 RunC 項目,交由一個完全中立的基金會管理,然后以 RunC 為依據,大家共同制定一套容器和鏡像的標準和規范。
但由于 OCI 的成立更多的是這些容器玩家出于自身利益進行干涉的一個妥協結果。所以OCI的組織效率一直很低下。
Docker 公司之所以不擔心 OCI 的威脅,原因就在于它的 Docker 項目是容器生態的事實標準,而它所維護的 Docker 社區也足夠龐大。可是,一旦這場斗爭被轉移到容器之上的平臺層,或者說 PaaS 層,Docker 公司的競爭優勢便立刻捉襟見肘了。
Google、RedHat 等開源基礎設施領域玩家們,為了牽制Docker,共同牽頭發起了一個名為 CNCF(Cloud Native Computing Foundation)的基金會。這個基金會的目的其實很容易理解:它希望,以 Kubernetes 項目為基礎,建立一個由開源基礎設施領域廠商主導的、按照獨立基金會方式運營的平臺級社區,來對抗以 Docker 公司為核心的容器商業生態。
k8s早先在社區一直被認為太過前衛先進,但隨著時間的發展,GOOGLE的工程能力也逐步得到社區的認可。而沒有大規模驗證的 swarm 逐步淡出人們視野。
2016 年,Docker 公司宣布了一個震驚所有人的計劃:放棄現有的 Swarm 項目,將容器編排和集群管理功能全部內置到 Docker 項目當中。
到此,容器編排之爭落下帷幕。





