

?轉載本文需注明出處:微信公眾號EAWorld,違者必究。
引言:
在企業級應用實施和運營過程中,為了解決企業中部分業務場景訪問量大、并發量高的問題,就需要對系統架構及應用參數做出優化和調整,如架構優化、數據庫優化、應用優化等。
應用系統部署優化是一個不斷嘗試、實踐、總結的過程,并針對不同企業的特點制定相關解決方案。通過應用系統架構、數據庫及應用優化入手,并通過相關案例加以說明和解釋。
目錄:
1、應用系統架構簡介
2、數據庫及應用優化方案
3、優化案例分析
1. 應用系統架構簡介
應用系統架構的發展
當今互聯網技術發展日新月異,應用系統架構也在不斷的更新迭代,從傳統的單一架構演變為如今的集群架構、分布式、微服務架構等,以便滿足用戶對系統的要求。
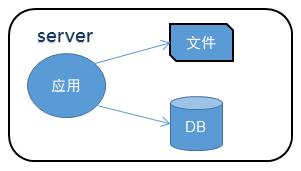
NO1.單機部署架構
互聯網建設初期,用戶訪問量有限,數據量不大,多數系統采用單臺服務器部署應用服務,系統服務、文件、數據庫等所有系統資源部署在一臺服務器上.
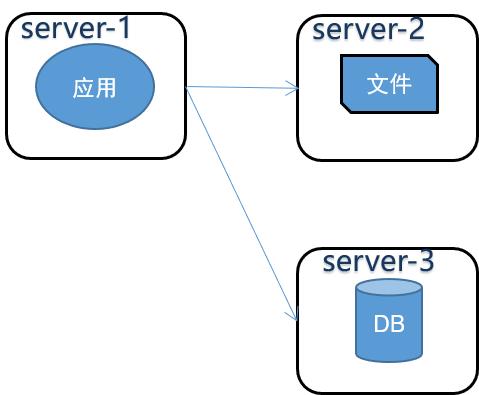
NO2.應用和數據分離
隨著用戶量和數據量的不斷攀升,業務對系統的性能要求越來越高,這是需要將應用和數據分離,單獨部署相關的業務組件。
NO3.引入NoSQL數據庫架構
隨著用戶不斷的增加,關系型數據庫壓力變大,訪問延遲,性能下降,這時加入緩存技術,將查詢較多數據緩存起來,以加快應用訪問速度。

NO4.應用集群部署
在訪問量高峰時期,單一的系統服務往往無法承受巨大的訪問量,這時就需要做集群服務,以減少單臺服務器的壓力。
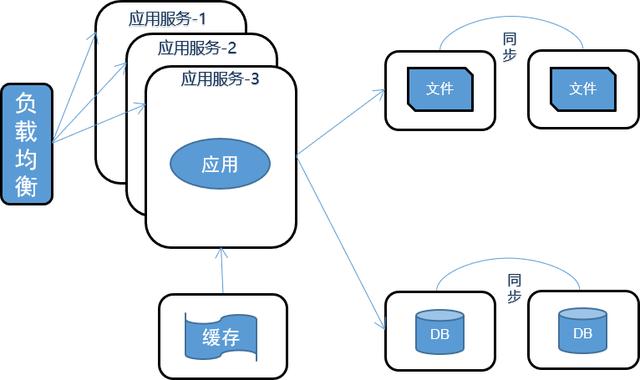
中小企業應用系統多數為集群部署,既保證系統的穩定性,又能降低因服務器故障,造成數據丟失的風險。
其他在應用集群部署方案上演變的架構系統,如:分布式、微服務架構等,對系統穩定性和安全性做的更加出色。
2.數據庫及應用優化方案
本章節主要介紹MySQL數據庫的部署及常見優化方案;應用以Tomcat為例,簡單介紹tomcat的常見參數優化配置。
- 數據庫分類介紹
當今的互聯網企業中,最常用的數據庫模式主要有兩種,即關系型數據庫和非關系型數據庫。
關系型數據庫:采用了關系模型來組織數據的數據庫,其以行和列的形式存儲數據,行和列被稱為表,一組表組成了數據庫。
- MySQL:甲骨文旗下產品,體積小、速度快、成本低,代碼開源,適用于中小型網站開發
- ORACLE:同樣為甲骨文旗下產品,Oracle可移植性好、使用方便、功能強,高效率、可靠性好的、適應高吞吐量的數據庫方案
- SQLServer:微軟旗下產品,圖像化用戶界面,使用方便、web技術支持良好、豐富的編程接口
非關系型數據庫:去掉關系數據庫的關系型特性,數據之間無關系,非常容易擴展。同時也在架構的層面上帶來了可擴展能力。大數據量,高性能,NoSQL數據庫具有非常高的讀寫性能。
- redis:基于內存亦可持久化的日志型、Key-Value數據庫
- MongoDB:分布式文件存儲數據庫,高效的二進制數據存儲,使用方便
- HBASE:列存儲數據庫,以列簇式存儲,將同一列數據存在一起
- MySQL數據庫部署
案例系統環境為RadHat_6.6_64;數據庫版本為MySQL-5.7.23社區版(mysql-5.7.23-1.el6.x86_64.rpm-bundle.tar)。
mysql安裝方法有RPM包安裝和源碼包安裝,RPM安裝是最簡單的安裝方法,不需要源碼編譯適合初學者安裝使用。
1.檢查系統是否含有自帶mysql
使用命令# rpm -qa|grep -i mysql
2.yum卸載自帶mysql
使用命令# yum -y remove mysql-libs-*
卸載完成后,請再次執行步驟1進行檢查
3.上傳mysql-5.7.23-1.el6.x86_64.rpm-bundle.tar到服務器,并解壓縮
# tar –xvf mysql-5.7.23-1.el6.x86_64.rpm-bundle.tar
4.rpm安裝mysql數據庫,按照順序以下命令執行
#rpm -ivh mysql-community-common-5.7.23-1.el6.x86_64.rpm
#rpm -ivh mysql-community-libs-5.7.23-1.el6.x86_64.rpm
#rpm -ivh mysql-community-libs-compat-5.7.23-1.el6.x86_64.rpm
#rpm -ivh mysql-community-embedded-5.7.23-1.el6.x86_64.rpm
#rpm -ivh mysql-community-devel-5.7.23-1.el6.x86_64.rpm
#rpm -ivh mysql-community-embedded-devel-5.7.23-1.el6.x86_64.rpm
#rpm -ivh mysql-community-client-5.7.23-1.el6.x86_64.rpm
#rpm -ivh mysql-community-server-5.7.23-1.el6.x86_64.rpm
5.初始化數據庫
# mysqld --initialize
6.啟動數據庫并修改root默認密碼
使用命令 # service mysqld start --啟動數據庫
使用命令 # service mysqld status --檢查數據庫狀態
使用命令 # cat /var/log/mysqld.log --查看數據庫root初始化密碼
登錄mysql數據庫:
# mysql -uroot –p ‘!w1wzCxJprmv’
設置root用戶的新密碼:
#set password=password('******');
可設置mysql服務開機自啟動:
chkconfig --add mysqld
chkconfig mysqld on
檢查:chkconfig --list mysqld
MySQL參數優化
需要修改my.cnf配置文件,修改完成后,重新啟動mysql # service mysqld restart
參數設置:
- skip-name-resolve
#開啟該選項,則所有遠程主機連接授權都要使用IP地址方式
- back_log = 512
#系統在一個短時間內有很多連接,則需要增大該值,該值指定到來的TCP/IP連接的偵聽隊列的大小,linux系統推薦設置為小于512的整數
- max_allowed_packet = 4M
#限制插入的數據包大小
- max_connections = 500
#指定MySQL允許的最大連接進程數
- sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER
# NO_ENGIN_SUBSTITUTION 在創建表指定一個不存在的存儲引擎,mysql會提示錯誤,反之,則會設置成默認的innodb
# STRICT_TRANS_TABLES 在插入或更新數據時進行更嚴格的檢查,如果發現某個值缺失或非法,MySQL將拋出錯誤,語句會停止運行并回滾
# NO_AUTO_CREATE_USER 新建用戶不能空密碼
lower_case_table_names=1
#“0”是表名存儲是給定的大小寫,比較是區分大小寫的 “1”表名存儲在磁盤是小寫,比較是不區分大小寫的 “2”表名存儲是給定的大小寫,比較是小寫
- explicit_defaults_for_timestamp=true
#如果一行數據中某些列被更新了,如果這一行中有timestamp類型的列,那么這個timestamp列的數據也會被自動更新到,更新操作所發生的那個時間點
skip-networking
#開啟該選項可以徹底關閉MySQL的TCP/IP連接方式,如果WEB服務器是以遠程連接的方式訪問MySQL數據庫服務器則不要開啟該選項!!!!!
MySQL不同訪問量級時的架構應用
日訪問量為萬級以內
無需做架構層優化,應用和數據庫分離部署,但是考慮數據的安全和備份,可以考慮搭建主從部署,主數據庫承擔所有業務訪問,從數據庫用作熱備
日訪問量達到十萬以上
可以考慮一主多從(讀寫分離)架構,即主數據庫承擔“寫”任務,從數據庫承擔“讀”任務
日訪問量達到百萬以上
一主已經無法承擔相關業務訪問,需要進一步作出調整。我們將相關的用戶、業務、權限等分離出來,單獨運行至一個數據庫,然后再做主從,即分庫;也可以將讀取量或者寫入量大的表分離出來,單獨運行至一個數據庫,或者將大表分離成多個小表,即分表。這種方式就是分庫分表的模式
- 主從同步架構介紹
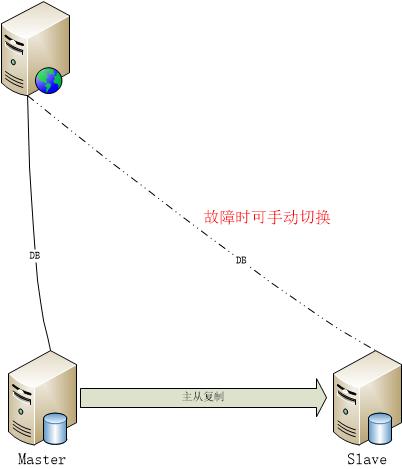
可用于用戶量較小,允許短時終止服務的子系統或小型系統。
當master出現故障時,可以通過手動調整web應用服務器連接數據庫的地址,將數據庫請求切換到slave數據庫中。
當master故障修復后,可以將slave數據庫的整個mysql-data目錄拷貝至master中,值得注意的是,mysql-data目錄中包含auto.cnf文件,這是mysql的server-uuid值,需要繼續使用master中原有的值,然后重新配置主從同步。
[auto]
server-uuid=a34c331b-e55c-11e9-9107-000c292efb70
也可以將Slave用作主庫使用,Master當作從庫使用,重新配置主從同步。
主從同步部署
1.主庫創建同步用戶
mysql>GRANT REPLICATION SLAVE,FILE ON *.* TO 'replication'@'%' IDENTIFIED BY '*******'
2.修改主庫配置文件
編輯my.cnf文件
log-bin=mysql-bin #日志文件名
server-id=1 #主數據庫端ID號
修改問完成,請重啟
3.查詢主庫master狀態
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000001 | 154 | | |
+------------------+----------+--------------+------------------+
調整完畢后不要再操作主庫,防止主庫數據發生變化
4.從庫執行同步命令
mysql>change master to master_host=‘192.168.0.1’,master_user= ‘replication ’,master_password=‘******',master_log_file='mysql-bin.000001',master_log_pos=154;
mysql>start slave; #開啟同步
5.檢查從庫同步狀態
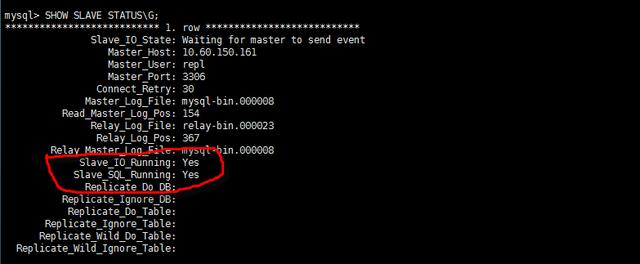
show slave statusG;
# Slave_IO_Running及Slave_SQL_Running進程必須正常運行
主從同步參數優化
主從同步參數優化,修改my.cnf文件
1.參數進行忽略(從庫配置文件)
當業務中出現無需同步的數據表時,可以選擇replicate_wild_ignore_table=db.table參數進行忽略(從庫配置文件)
2.跳過指定錯誤(從庫配置文件)
slave-skip-errors = 1062,1053 #根據業務類型選擇
1007:數據庫已存在,創建數據庫失敗
1008:數據庫不存在,刪除數據庫失敗
1050:數據表已存在,創建數據表失敗
1051:數據表不存在,刪除數據表失敗
1054:字段不存在,或程序文件跟數據庫有沖突
1060:字段重復,導致無法插入
1061:重復鍵名
1068:定義了多個主鍵
1094:位置線程ID
1146:數據表缺失,請恢復數據庫
1053:復制過程中主服務器宕機
1062:主鍵沖突
3.刪除同步日志(主庫配置文件)
Master庫中的同步日志需要及時刪除
Expire_logs_days = 7 #刪除7天前的同步日志
主從復制原理簡介
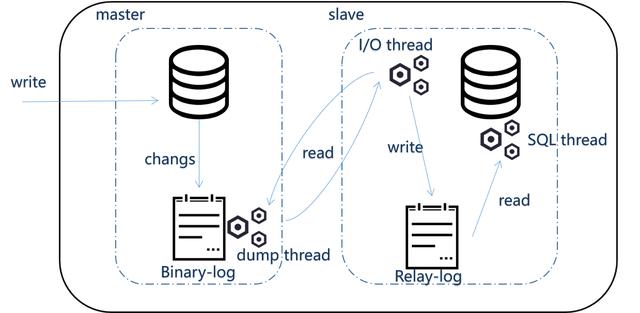
- slave庫手動執行change master to 語句連接master庫,提供了連接的用戶一切條件(user 、pwd、port、ip),并且讓slave知道,二進制日志的起點位置(file名 position 號),同時開啟start slave
- slave庫的IO線程和主庫的dump線程建立連接
- slave庫根據change master to 語句提供的file名和position號,IO線程向主庫發起binlog的請求
- master庫dump線程根據從庫的請求,將本地binlog發給slave庫IO線程
- slave庫IO線程接收binlog并存放到本地relay-log中
- slave庫SQL線程應用relay-log,默認情況下,已經應用過的relay-log 會自動被清理
- 主主同步架構介紹
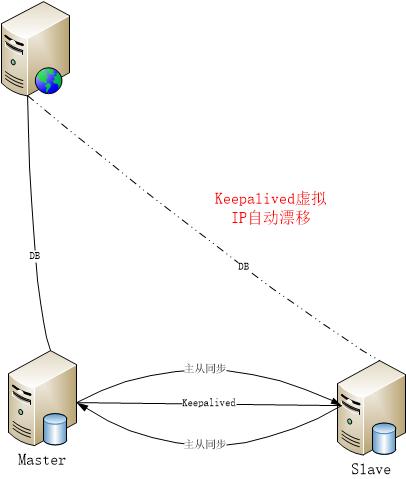
由于keepalived會檢測mysql運行狀態,在重啟mysql時注意,先停止keepalived服務,確認mysql運行正常時,再啟動keepalived。
主主配置方式和上文介紹的主從配置類似,即master復制slave數據,slave復制master數據。
Keepalived實現自動切換
Keepalived是實現集群高可用的服務軟件,通過虛擬路由冗余協議(vrrp),將N臺提供相同服務的路由組成一個路由組,可以有一個master和多個backup,master上是對外提供服務的虛擬ip,當backup收不到master發送的vrrp包時就認為master宕掉,此時選舉一個backup來充當master并重新綁定虛擬ip,來保證服務高可用性。
1.用戶自行下載相關版本并安裝
# cd keepalived
# ./configure --prefix=/usr/local/keepalived (安裝路徑)
# make && make install
2.設置系統為系統服務方便啟動停止
mkdir /etc/keepalived
cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
ln -s /usr/local/sbin/keepalived /usr/sbin/
ln -s /usr/local/keepalived/sbin/keepalived /sbin/
3.建議將keepalived設置為自啟服務
chkconfig keepalived on
4.Keepalived配置管理
修改/etc/keepalived/keepalived.conf文件
5.編寫keepalived執行腳本
注意:授權chmod +x /etc/keepalived/mysql_check.sh
6.可配置郵件發送提醒
編寫sendmail.pl腳本,注意:授權chmod +x /etc/keepalived/sendmail.pl
7.keepalived配置文件
global_defs { #全局配置
notification_email { #定義報警郵件地址
root@localhost
}
notification_email_from root@localhost #定義發送郵件的地址
smtp_server 127.0.0.1 #郵箱服務器
smtp_connect_timeout 30 #定義超時時間
router_id LVS_DEVEL #定義路由標識信息,建議使用主機名
}
vrrp_script chk_mysql {
script "/etc/keepalived/mysql_check.sh"
interval 2
weight -20
}
vrrp_instance VI_83 { #定義實例
state MASTER #狀態參數 master/backup 只是說明
interface eth0 #虛ip綁定網卡位置
virtual_router_id 83 #同一個集群id一致
priority 100 #priority值最大的將成為master
mcast_src_ip 192.168.0.1 #發送組播包的地址,不設置則使用網卡默認ip
advert_int 1 #主備通訊間隔s
authentication { #設置認證
auth_type PASS
auth_pass 1111
}
track_script {
chk_mysql
}
virtual_ipaddress { #虛擬ip
192.168.0.0
}
notify_master /etc/keepalived/sendmail.pl #郵件發送腳本
}
- 一主多從架構部署介紹
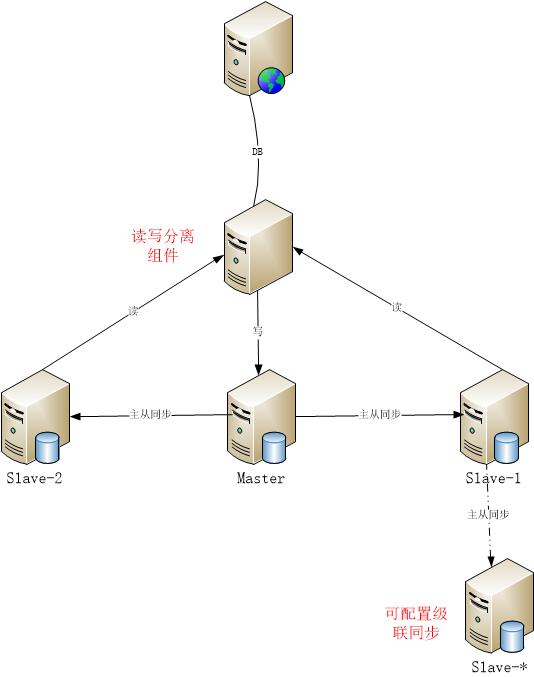
應用服務器只配置mycat地址即可,mycat可以實現讀寫分離和故障切換。
Master負責寫入,Slave負責讀取,同時MySQL可以支持級聯同步部署。
MySQL為保證事務的完整性,復制在slave上是串行化的,也就是多個master上的并行更新操作不能在同一slave上同時進行。
Mycat讀寫分離配置及優化
mycat可用于讀寫分離和數據切分的高可用中間件,并支持基于心跳檢測的自動故障切換,mycat主要包含兩個核心配置文件server.xml和schema.xml
1.server.xml配置優化
<user name=“user”> <!—對客戶端提供的用戶名、密碼 及表空間-->
<property name="password">******</property>
<property name="schemas">testdb</property>
<property name="readOnly">false</property>
<!--readOnly設置成false,代表可進行讀寫操作-->
</user>
2. schema.xml配置優化
<schema name=“testdb" checkSQLschema="false" sqlMaxLimit="100" dataNode=“dn1">
</schema>
<dataNode name=“dn1" dataHost="host001" database=“db1" />
<dataHost name=" host001" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status </heartbeat>
<writeHost host=“mysql-1” url=“192.168.0.1:3306” user=“user” password=“******”>
<!—master可讀、寫操作,slave只讀-->
<readHost host="mysql-1" url="192.168.0.1:3306" user=“user" password="******" />
<readHost host="mysql-2" url="192.168.0.2:3306" user=“user" password="******" />
</writeHost>
<writeHost host=“mysql-2” url=“192.168.0.2:3306” user=“user”password=“******”>
<!—master故障,切換slave讀寫-->
<readHost host="mysql-2" url="192.168.0.2:3306" user=“user" password="******" />
</writeHost>
</dataHost>
參數說明:
writeType屬性負載均衡類型,目前的取值有3種:
- writeType="0", 所有寫操作發送到配置的第一個writeHost,第一個掛了切到還生存的第二個writeHost,重新啟動后以切換后的為準,切換記錄在配置文件中:dnindex.properties.
- writeType="1",所有寫操作都隨機的發送到配置的writeHost,1.5以后廢棄不推薦。
- writeType="2",不執行寫操作
switchType指的是切換的模式,目前的取值也有4種:
- switchType='-1' 表示不自動切換
- switchType='1' 默認值,表示自動切換
- switchType='2' 基于MySQL主從同步的狀態決定是否切換,心跳語句為 show slave status
- switchType='3'基于MySQL galary cluster的切換機制(適合集群)(1.4.1),心跳語句為 show status like 'wsrep%'
負載均衡類型,目前的取值有4種:
- balance="0", 不開啟讀寫分離機制,所有讀操作都發送到當前可用的writeHost上。
- balance="1",所有讀操作都隨機的發送到readHost。全部的readHost與stand by writeHost參與select語句的負載均衡,簡單的說,當雙主雙從模式(M1->S1,M2->S2,并且M1與 M2互為主備),正常情況下,M2,S1,S2都參與select語句的負載均衡。
- balance="2",所有讀操作都隨機的在writeHost、readhost上分發。
- balance="3",所有讀請求隨機的分發到wiriterHost對應的readhost執行,writerHost不負擔讀壓力
- Tomcat優化分享
1.內存優化
內存優化主要是對啟動參數優化,啟動腳本 catalina.sh 中設置 JAVA_OPTS 參數
JAVA_OPTS參數說明:
-server 啟用jdk 的 server 版
-Xms java虛擬機初始化時的最小內存
-Xmx java虛擬機可使用的最大內存
-XX: PermSize 內存永久保留區域
-XX:MaxPermSize 內存最大永久保留區域
配置示例:
JAVA_OPTS=’-Xms1024m -Xmx2048m -XX: PermSize=256M -XX:MaxNewSize=256m -XX:MaxPermSize=256m’
說明:其內存的配置需要根據服務器(或虛擬機)的實際內存來配置;重啟tomcat生效。
2.線程優化
修改server.xml配置文件:
maxThreads = “500”
//最大線程數,默認200,沒有最理想的值,需要不斷調整、優化,道道最合理的配置
//當系統需要大量計算時,響應時間取決于cup運算能力,此時maxThreads盡量設小,降低同一時間內爭搶cup的線程數
//當系統主要是I/O或操作數據庫時,響應時間取決于外部資源等待,此時maxThreads盡量設大,提高同時處理請求的個數
minSpareThreads=“50“ //初始化時創建的線程數,默認值為4
maxSpareThreads="500“ //一旦創建的線程超過這個值,Tomcat就會關閉不再需要的socket線程
acceptCount=“500”
//當所有處理的線程都正在使用時,在隊列中排隊請求的最大數目,默認值為10,
//超出隊列數,任何請求都會被拒絕一般設置跟maxThreads一樣大,
//這個值應該是主要根據應用的訪問峰值與平均值來權衡配置的
3.其他常用優化
maxPostSize=“-1” //POST請求數據大小限制,默認2M,tomcat-7.0.63之前設置為”0”表示不限制,7.0.63版本之后,設置為負數,表示不顯示
connectionTimeout=“20000” //設置連接超時時間毫秒值
maxHttpHeaderSize=“8192” //HTTP請求和響應頭的最大量,以字節為單位,默認值為4096字節
URIEncoding=“UTF-8“ //Tomcat中配置URIEncoding=”UTF-8”來進行中文的處理
enableLookups=“false” //如果為true,則可以通過調用request.getRemoteHost()進行DNS查詢來得到遠程客戶端的實際主機名,若為false則不進行DNS查詢,而是返回其ip地址,為了提高處理能力,應設置為 false
3.優化案例分析
上面章節介紹了架構演變、數據庫及相關組件部署優化、Tomcat應用優化等內容,本章節以實際架構案例分析,講解上述內容在實際架構中的應用。

案例架構采用典型的分層服務架構(三層),即接入層、應用層和數據層,所有應用服務均使用集群部署,保證服務的高可用性。
數據層:
案例系統中,數據讀取業務偏多,故考慮使用使用mycat做讀寫分離,兩臺數據庫同時對外提供讀取業務,其中一臺主服務器提供寫入操作,當master節點宕機之后,mycat組件檢測到服務狀態,并將讀寫能力全部切換至slave節點,保證系統的運行
Mycat組件進行讀寫分離和故障切換,所有應用服務連接keepalived對外提供的虛擬ip進行數據庫操作,Mycat本身也是一個高可用集群架構。
應用層:
內網負責均衡服務除了可以負載業務的請求之外,還將DMZ區與內網隔離,避免代理服務器直接請求內網應用,負載均衡Nginx使用時,應當根據集群中服務器的性能、部署服務等,合理進行權重分配。
公共組件應用服務器將組件服務通過分布式系統發布,供其他業務系統使用;也可為移動端提供公共服務組件。
應用集群服務器可能存在文件上傳業務,當文件上傳至服務器后,注意集群之間的數據同步問題。
接入層:
DMZ區:為了解決外部網絡不能訪問內部網絡服務器的問題,而設立的一個非安全系統與安全系統之間的緩沖區。由于DMZ區的特殊性,與Internet相比,DMZ可以提供更高的安全性,但是其安全性比內部網絡低,所以在部署時,特別注意網絡上的連通性關系。
DMZ區左側代理服務器主要負責代理推送和設備管理服務對互聯網的請求,用戶也可直接通過互聯網訪問到該代理集群服務器,可以用作內部自建應用市場等互聯網服務;DMZ區右側代理服務器主要通過安全網關通道將業務請求代理至內網,安全網關只對其白名單中的服務器和端口進行開放。
*1.注意圖中①②③④標注位置的網絡開通
*2.圖中使用keepalived做高可用架構的地方如圖中的⑤標注位置,需要注意虛擬ip的使用
應用部署和優化的方法多種多樣,其本身就是一個不斷嘗試、實踐、總結的過程,很多相關的技術方案和閱讀資料只能用作借鑒參考,我們需要針對不同企業的特點來制定相關方案,不斷去優化嘗試,才能最終解決問題。
關于作者:冬火,現任普元移動團隊開發運維工程師,主攻Java Web開發、系統架構設計和維護,先后參與多家金融機構移動平臺系統的開發和架構設計運維工作。專注服務部署和優化、網絡技術愛好者,移動平臺架構的踐行者。
關于EAWorld:微服務,DevOps,數據治理,移動架構原創技術分享。





