
寫在前面
之前寫過一篇關(guān)于統(tǒng)計學(xué)軟件STAMP的教程,使用STAMP對微生物群落數(shù)據(jù)進行統(tǒng)計學(xué)分析還是挺方便的,尤其是對R語言不是很熟悉的朋友來說,圖形化的界面和相對簡單的操作還是挺友好的。
-
STAMP——微生物組間差異統(tǒng)計分析 簡明教程 中文幫助文檔
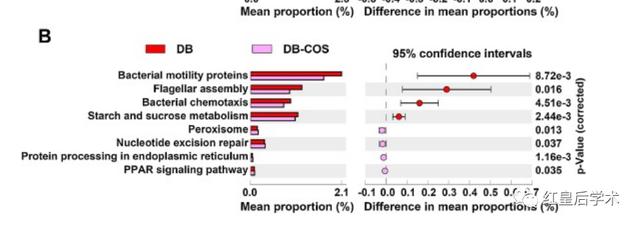
我們通常使用的STAMP的結(jié)果主要就是兩組數(shù)據(jù)之間差異性檢驗的被稱作Extended error bar(擴展柱狀圖)的圖像。
由于STAMP的結(jié)果圖相對固定,可修改的圖像參數(shù)有限,經(jīng)常會遇到一些問題,比如靶標物種或功能基因名字過程就會導(dǎo)致顯示不全,在與其它圖像拼接成一副圖的時候也會出現(xiàn)字號太小導(dǎo)致看不清楚的問題。
正好前幾天在群里有人詢問了這個圖有沒有其它的繪制辦法,今天就給大家?guī)硪粋€使用ggplot2繪制Extended error bar的方法。
數(shù)據(jù)準備
這里我將使用一套同一環(huán)境位點水體和沉積物16S擴增子測序的PICRUSt功能預(yù)測結(jié)果作為示例。
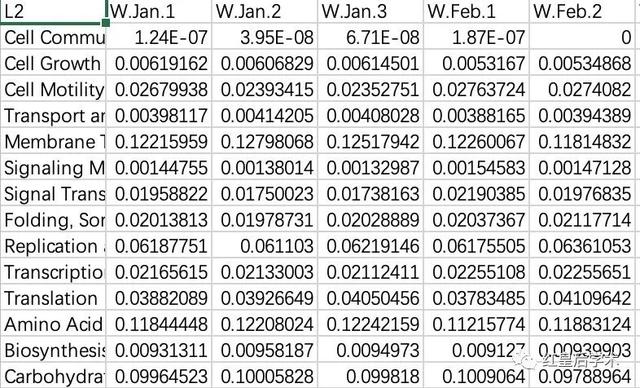
選擇的是KEGG L2水平的功能預(yù)測的相對豐度數(shù)據(jù)。
繪圖的數(shù)據(jù)文件有兩個,一個是豐度數(shù)據(jù),另一個是樣本分組數(shù)據(jù)。
后臺回復(fù)“STAMP”獲取示例文件和完整代碼。
首先將數(shù)據(jù)導(dǎo)入R環(huán)境,我是首先過濾掉了平均豐度低于1%的功能分類。
data <- read.table("KEGG_L2.txt",header = TRUE,row.names = 1,sep = "t")
group <- read.table("group.txt",header = FALSE,sep = "t")
library(tidyverse)
data <- data*100
data <- data %>% filter(Apply(data,1,mean) > 1)
??如果使用不同分類學(xué)水平的微生物數(shù)據(jù)或著更深層次的功能注釋數(shù)據(jù),由于物種或功能基因種類較多,可能會導(dǎo)致結(jié)果中具有差異的數(shù)目特別多,比如幾十個差異物種放在一副圖里基本上是不可能看清的,這種時候就要對數(shù)據(jù)進行過濾,去除低豐度的物種或基因,具體的過濾標準請根據(jù)自身數(shù)據(jù)情況自行確定。
統(tǒng)計學(xué)檢驗
在繪制Extended error bar之前首先要對數(shù)據(jù)進行差異顯著性檢驗,以選出豐度在不同組間具有顯著差異的物種或功能基因,這里以兩組數(shù)據(jù)為例,使用的檢驗方式通常為t-test和Wilcox秩和檢驗。
當分析數(shù)據(jù)符合正態(tài)分布時,使用t-test,如不符合正態(tài)分布,則使用Wilcox秩和檢驗。
t-test
首先對數(shù)據(jù)進行調(diào)整,構(gòu)建用于t-test的數(shù)據(jù)框。
data <- t(data)
data1 <- data.frame(data,group$V2)
colnames(data1) <- c(colnames(data),"Group")
data1$Group <- as.factor(data1$Group)
由于R語言的t-test一次只能分析一列數(shù)據(jù),在網(wǎng)上搜到了一個批量進行t-test的方法,感覺是最簡便的了。
首先使用select_if選擇格式為數(shù)字列,然后使用map_df分別對每一個列進行t-test,最后使用broom:tidy將結(jié)果整合在tidy的數(shù)據(jù)框中。
diff <- data1 %>%
select_if(is.numeric) %>%
map_df(~ broom::tidy(t.test(. ~ Group,data = data1)), .id = 'var')
最后對t-test的p值進行校正,保留校正后p值小于0.05的數(shù)據(jù)。
diff$p.value <- p.adjust(diff$p.value,"bonferroni")
diff <- diff %>% filter(p.value < 0.05)
秩和檢驗
秩和檢驗和上面的t-test一樣,只需要把代碼中的t.test換成wilcox.test就可以了。
diff1 <- data1 %>%
select_if(is.numeric) %>%
map_df(~ broom::tidy(wilcox.test(. ~ Group,data = data1)), .id = 'var')
diff1$p.value <- p.adjust(diff1$p.value,"bonferroni")
diff1 <- diff %>% filter(p.value < 0.05)
數(shù)據(jù)可視化
這個Extended error bar的結(jié)果圖整體分為兩個部分,左側(cè)為組建物種或基因豐度平均值的比較條形圖,右側(cè)為組間平均豐度及其95%置信區(qū)間的散點圖。
畫圖的思路是首先分別繪制左右兩幅圖,之后再拼接在一起,因此需要首先構(gòu)建繪制兩幅圖所需的繪圖文件。
繪圖數(shù)據(jù)獲取
對于左側(cè)的組間豐度均值比較條形圖,我們首先根據(jù)差異性檢驗的結(jié)果從原始的豐度數(shù)據(jù)文件中提取具有顯著差異的列,之后按照分組計算其組內(nèi)平均豐度,再轉(zhuǎn)換成ggplot繪圖所用的長格式數(shù)據(jù)框。
abun.bar <- data1[,c(diff$var,"Group")] %>%
gather(variable,value,-Group) %>%
group_by(variable,Group) %>%
summarise(Mean = mean(value))
對于右側(cè)散點圖所需要的數(shù)據(jù),在上一步差異學(xué)檢驗的結(jié)果中已經(jīng)給出了,我們只需要提取對應(yīng)的數(shù)據(jù)列,之后根據(jù)差異的正負給其賦予對應(yīng)的分組信息,最后按照差異豐度的大小對數(shù)據(jù)進行重新的排序
diff.mean <- diff[,c("var","estimate","conf.low","conf.high")]
diff.mean$Group <- c(ifelse(diff.mean$estimate >0,levels(data1$Group)[1],
levels(data1$Group)[2]))
diff.mean <- diff.mean[order(diff.mean$estimate,decreasing = TRUE),]
左側(cè)條形圖
在繪制條形圖之前,要把物種或基因名按照其組間豐度差異從大到小進行一個排序,以便圖像的美觀。
在畫圖之前首先要根據(jù)物種或基因豐度的差異大小,對變量的名稱設(shè)置一個因子并排序,以保證兩幅圖變量排序的一致性。
library(ggplot2)
cbbPalette <- c("#E69F00", "#56B4E9")
abun.bar$variable <- factor(abun.bar$variable,levels = rev(diff.mean$var))
接下來繪制圖像。
p1 <- ggplot(abun.bar,aes(variable,Mean,fill = Group)) +
scale_x_discrete(limits = levels(diff.mean$var)) +
coord_flip +
xlab("") +
ylab("Mean proportion (%)") +
theme(panel.background = element_rect(fill = 'transparent'),
panel.grid = element_blank,
axis.ticks.length = unit(0.4,"lines"),
axis.ticks = element_line(color='black'),
axis.line = element_line(colour = "black"),
axis.title.x=element_text(colour='black', size=12,face = "bold"),
axis.text=element_text(colour='black',size=10,face = "bold"),
legend.title=element_blank,
legend.text=element_text(size=12,face = "bold",colour = "black",
margin = margin(r = 20)),
legend.position = c(-1,-0.1),
legend.direction = "horizontal",
legend.key.width = unit(0.8,"cm"),
legend.key.height = unit(0.5,"cm"))for (i in 1:(nrow(diff.mean) - 1))
p1 <- p1 + annotate('rect', xmin = i+0.5, xmax = i+1.5, ymin = -Inf, ymax = Inf,
fill = ifelse(i %% 2 == 0, 'white', 'gray95'))
p1 <- p1 +
geom_bar(stat = "identity",position = "dodge",width = 0.7,colour = "black") +
scale_fill_manual(values=cbbPalette)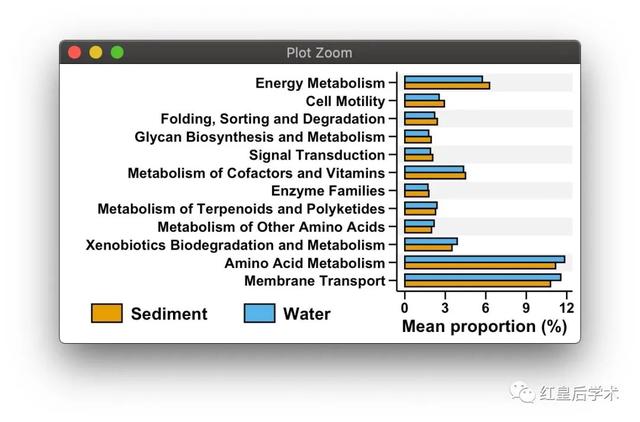
本來是不想用循環(huán)添加矩形的方式來實現(xiàn)灰白較差的底紋的,但是研究了半天也沒找到更方便的辦法,各位要是有更簡便的辦法歡迎私聊~~
這里要特別注意圖層的順序,一定要在添加舉行之后在繪制條形圖,不然會覆蓋掉。
右側(cè)散點圖
同樣要先對變量名進行一個因子排序,保證兩個圖像的變量順序的一致。
此外散點圖要在右側(cè)添加校正后的p-value,因此需要先對p-value取有效數(shù)字,之后轉(zhuǎn)換成文本。
diff.mean$var <- factor(diff.mean$var,levels = levels(abun.bar$variable))
diff.mean$p.value <- signif(diff.mean$p.value,3)
diff.mean$p.value <- as.character(diff.mean$p.value)
本來是想畫散點圖的同時直接把p-value的文本加上,但是由于這幅圖p-value的文本是添加在繪圖區(qū)以外的,研究了半天沒弄明白,后來給分成了兩個圖,一副圖只有散點圖,另一副圖只有右側(cè)的p-value文本。
散點圖的繪制。
p2 <- ggplot(diff.mean,aes(var,estimate,fill = Group)) +
theme(panel.background = element_rect(fill = 'transparent'),
panel.grid = element_blank,
axis.ticks.length = unit(0.4,"lines"),
axis.ticks = element_line(color='black'),
axis.line = element_line(colour = "black"),
axis.title.x=element_text(colour='black', size=12,face = "bold"),
axis.text=element_text(colour='black',size=10,face = "bold"),
axis.text.y = element_blank,
legend.position = "none",
axis.line.y = element_blank,
axis.ticks.y = element_blank,
plot.title = element_text(size = 15,face = "bold",colour = "black",hjust = 0.5)) +
scale_x_discrete(limits = levels(diff.mean$var)) +
coord_flip +
xlab("") +
ylab("Difference in mean proportions (%)") +
labs(title="95% confidence intervals")
for (i in 1:(nrow(diff.mean) - 1))
p2 <- p2 + annotate('rect', xmin = i+0.5, xmax = i+1.5, ymin = -Inf, ymax = Inf,
fill = ifelse(i %% 2 == 0, 'white', 'gray95'))
p2 <- p2 +
geom_errorbar(aes(ymin = conf.low, ymax = conf.high),
position = position_dodge(0.8), width = 0.5, size = 0.5) +
geom_point(shape = 21,size = 3) +
scale_fill_manual(values=cbbPalette) +
geom_hline(aes(yintercept = 0), linetype = 'dashed', color = 'black')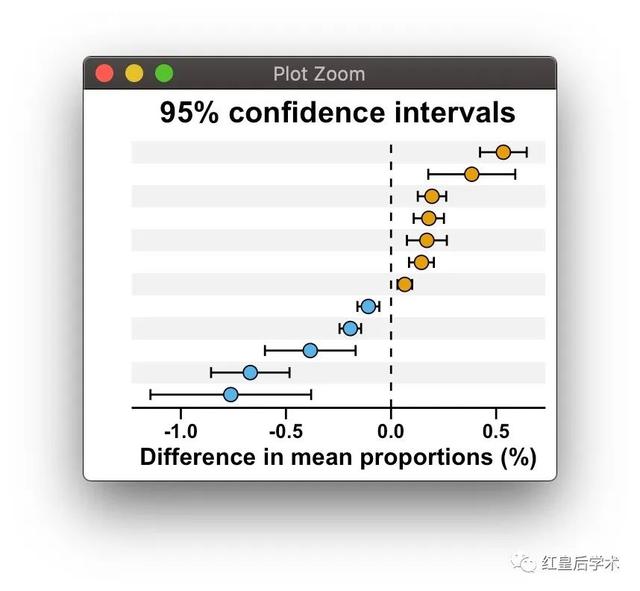
p-value文本的繪制。
p3 <- ggplot(diff.mean,aes(var,estimate,fill = Group)) +
geom_text(aes(y = 0,x = var),label = diff.mean$p.value,
hjust = 0,fontface = "bold",inherit.aes = FALSE,size = 3) +
geom_text(aes(x = nrow(diff.mean)/2 +0.5,y = 0.85),label = "P-value (corrected)",
srt = 90,fontface = "bold",size = 5) +
coord_flip +
ylim(c(0,1)) +
theme(panel.background = element_blank,
panel.grid = element_blank,
axis.line = element_blank,
axis.ticks = element_blank,
axis.text = element_blank,
axis.title = element_blank)
這樣所有的繪圖單元就齊了。
圖像拼接
使用patchwork對3個繪圖部分進行拼接。
library(patchwork)
p <- p1 + p2 + p3 + plot_layout(widths = c(4,6,2))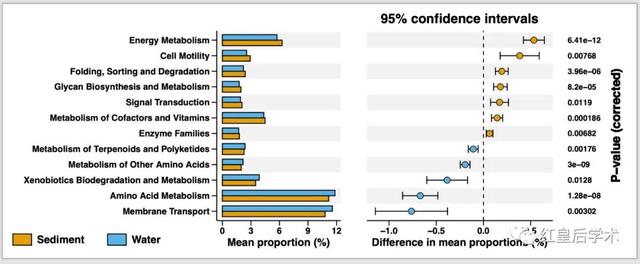
最后保存圖片就齊活了。
ggsave("stamp.pdf",p,width = 10,height = 4)
后臺回復(fù)“STAMP”獲取示例文件和完整代碼。
本文中差異性檢驗的代碼參考了:https://www.it1352.com/1581321.html
另外感謝“生信小白魚”提供循環(huán)添加矩形的代碼!!
10000+:菌群分析 寶寶與貓狗 梅毒狂想曲 提DNA發(fā)Nature Cell專刊 腸道指揮大腦
系列教程:微生物組入門 BIOStar 微生物組 宏基因組
專業(yè)技能:學(xué)術(shù)圖表 高分文章 生信寶典 不可或缺的人
一文讀懂:宏基因組 寄生蟲益處 進化樹
為鼓勵讀者交流、快速解決科研困難,我們建立了“宏基因組”專業(yè)討論群,目前己有國內(nèi)外5000+ 一線科研人員加入。參與討論,獲得專業(yè)解答,歡迎分享此文至朋友圈,并掃碼加主編好友帶你入群,務(wù)必備注“姓名-單位-研究方向-職稱/年級”。PI請明示身份,另有海內(nèi)外微生物相關(guān)PI群供大佬合作交流。技術(shù)問題尋求幫助,首先閱讀《如何優(yōu)雅的提問》學(xué)習(xí)解決問題思路,仍未解決群內(nèi)討論,問題不私聊,幫助同行。





