擊這里在線咨詢客服")
譯者丨朱先忠
近些年來,向量數(shù)據(jù)庫引起業(yè)界的廣泛關(guān)注,一個(gè)相關(guān)事實(shí)是許多向量數(shù)據(jù)庫初創(chuàng)公司在短期內(nèi)就籌集到數(shù)百萬美元的資金。
你很可能已經(jīng)聽說過向量數(shù)據(jù)庫,但也許直到現(xiàn)在才真正關(guān)心向量數(shù)據(jù)庫——至少,我想這就是你現(xiàn)在閱讀本文的原因……
如果你閱讀本文只是為了簡單回答上面的問題,那就讓我們直接進(jìn)入話題吧。
1、定義:什么是向量數(shù)據(jù)庫?
向量數(shù)據(jù)庫是一種以向量嵌入(高維向量)方式存儲和管理非結(jié)構(gòu)化數(shù)據(jù)(如文本、圖像或音頻)的數(shù)據(jù)庫,以便于快速查找和檢索類似對象。
如果這個(gè)定義只會(huì)引起人們更多的理解上的混亂,那么就讓我們一步一步來進(jìn)行解釋。本文的靈感來自WIRED的5級視頻系列(https://www.wired.com/video/series/5-levels),本文將揭示向量數(shù)據(jù)庫在以下三個(gè)難度級別中的內(nèi)容:
- 最淺顯的解釋
- 向數(shù)字原住民和技術(shù)愛好者解釋向量數(shù)據(jù)庫
- 向工程師和數(shù)據(jù)專業(yè)人員解釋向量數(shù)據(jù)庫
2、向量數(shù)據(jù)庫:最淺面的解釋
這有點(diǎn)離題,但你知道我不明白的是什么嗎?當(dāng)人們按顏色排列書架時(shí),哎喲!當(dāng)他們不知道書的封面是什么顏色時(shí),他們是如何找到書的?
圖片

1)向量數(shù)據(jù)庫背后的直覺
如果你想快速找到一本特定的書,那么,按類型和作者排列書架比按顏色排列更有意義。這就是為什么大多數(shù)圖書館都是這樣組織的原因,以便幫助你快速找到你想要的東西。
但是,你如何根據(jù)一個(gè)查詢而不是一個(gè)流派或作者來找到可以閱讀的書籍呢?如果你想讀一本書,例如:類似于《饑餓的毛毛蟲》或關(guān)于一個(gè)和你一樣喜歡吃美食的主角?
如果你沒有時(shí)間瀏覽書架,最快的方法是向圖書管理員征求他們的推薦,因?yàn)樗麄冏x過很多書,會(huì)確切地知道哪本書最適合你的查詢。
在組織書籍的例子中,你可以將圖書管理員視為向量數(shù)據(jù)庫,因?yàn)橄蛄繑?shù)據(jù)庫旨在存儲關(guān)于對象(例如書籍)的復(fù)雜信息(例如書籍的情節(jié))。因此,向量數(shù)據(jù)庫可以幫助你根據(jù)特定的查詢(例如,一本關(guān)于…的書)而不是一些預(yù)定義的屬性(例如,作者)來查找對象,就像圖書管理員一樣。
3、向數(shù)字原住民和技術(shù)愛好者解釋向量數(shù)據(jù)庫
現(xiàn)在,讓我們繼續(xù)探討圖書館的例子,并獲得更多的技術(shù)知識:當(dāng)然,現(xiàn)在,在圖書館中搜索書籍的技術(shù)比只按類型或作者搜索更先進(jìn)了一些。
如果你去圖書館,通常角落里會(huì)有一臺電腦,可以幫助你找到一本具有更具體屬性的書,比如書名、國際標(biāo)準(zhǔn)圖書編號、出版年份或一些關(guān)鍵詞。根據(jù)輸入的值,就可以查詢存儲可用書籍信息的數(shù)據(jù)庫。不過,這個(gè)數(shù)據(jù)庫通常是一個(gè)傳統(tǒng)的關(guān)系數(shù)據(jù)庫。
圖片

1)關(guān)系數(shù)據(jù)庫和向量數(shù)據(jù)庫之間的區(qū)別是什么?
關(guān)系數(shù)據(jù)庫和向量數(shù)據(jù)庫之間的主要區(qū)別在于它們存儲的數(shù)據(jù)類型。雖然關(guān)系數(shù)據(jù)庫是為適合表的結(jié)構(gòu)化數(shù)據(jù)而設(shè)計(jì)的,但是,向量數(shù)據(jù)庫即是為非結(jié)構(gòu)化數(shù)據(jù)(如文本或圖像)而設(shè)計(jì)的。
存儲的數(shù)據(jù)類型也會(huì)影響數(shù)據(jù)的檢索方式:在關(guān)系數(shù)據(jù)庫中,查詢結(jié)果基于特定關(guān)鍵字的匹配。在向量數(shù)據(jù)庫中,查詢結(jié)果是基于相似性進(jìn)行的。
你可以把傳統(tǒng)的關(guān)系數(shù)據(jù)庫想象成電子表格。它們非常適合存儲結(jié)構(gòu)數(shù)據(jù),例如關(guān)于一本書的基本信息(例如,標(biāo)題、作者、ISBN等),因?yàn)檫@類信息可以存儲在列中,非常適合過濾和排序。
使用關(guān)系數(shù)據(jù)庫,你可以快速獲取所有書籍,例如兒童書籍,并且標(biāo)題中有“毛蟲”。
但是,如果你喜歡《饑餓的毛毛蟲》是關(guān)于食物的呢?你可以試著搜索關(guān)鍵詞“食物”,但除非在書的摘要中提到關(guān)鍵詞“食品”,否則你甚至找不到“非常饑餓的毛毛蟲”。相反,你可能會(huì)以一堆烹飪書和失望告終。
這是關(guān)系數(shù)據(jù)庫的一個(gè)限制:你必須添加你認(rèn)為某人可能需要的所有信息才能找到該特定項(xiàng)目。但是,你怎么知道該添加哪些信息以及添加多少信息呢?添加所有這些信息往往非常耗時(shí),并且不能保證完整性。
然而,這正是向量數(shù)據(jù)庫發(fā)揮作用的地方!
不過,你首先需要先來了解一下一個(gè)叫做向量嵌入(vector embeddings)的概念。
今天的機(jī)器學(xué)習(xí)(ML)算法可以將給定的對象(例如,單詞或文本)轉(zhuǎn)換為保留該對象信息的數(shù)字表示。想象一下,你給一個(gè)ML模型一個(gè)詞(例如,“食物”),然后這個(gè)ML模型發(fā)揮了它的魔力,給你返回了一長串?dāng)?shù)字。這個(gè)長長的數(shù)字列表是單詞的數(shù)字表示,即稱為向量嵌入。
因?yàn)檫@些嵌入是一長串?dāng)?shù)字,所以我們稱之為高維。讓我們假設(shè)這些嵌入只是三維的,以便將它們可視化,如下所示。
圖片
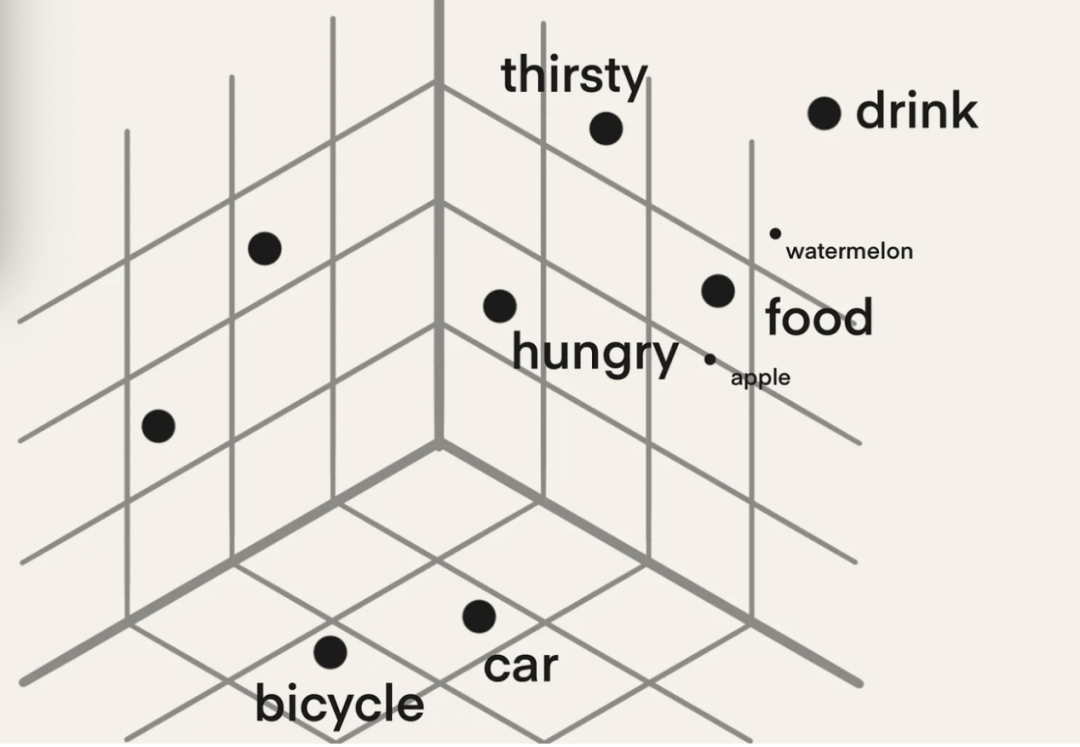
你可以看到,類似的單詞,如“饑餓”(hungry)、“口渴”(thirsty)、“食物”(food)和“飲料”(drink),都被分組在一個(gè)相似的角落里,而其他單詞如“自行車”(bicycle)和“汽車”(car),則在這個(gè)向量空間中靠近在一起,但在不同的角落里。
數(shù)字表示使我們能夠?qū)?shù)學(xué)計(jì)算應(yīng)用于通常不適合計(jì)算的對象,如單詞。例如,除非將單詞替換為其嵌入;否則,以下計(jì)算將不起作用:
drink - food + hungry = thirsty
因?yàn)槲覀兛梢允褂们度脒M(jìn)行計(jì)算,所以我們也可以計(jì)算一對嵌入對象之間的距離。兩個(gè)嵌入對象之間的距離越近,它們就越相似。
正如你所看到的,向量嵌入非常酷。
讓我們回到前面的例子,假設(shè)我們將每本書的內(nèi)容嵌入到圖書館中,并將這些嵌入存儲在向量數(shù)據(jù)庫中。現(xiàn)在,當(dāng)你想找到一本“主角喜歡食物的童書”時(shí),你的查詢也會(huì)被嵌入,并返回與你的查詢最相似的書籍,例如《饑餓的毛毛蟲》或《金發(fā)姑娘與三只熊》。
2)向量數(shù)據(jù)庫的使用情況是什么?
事實(shí)上,向量數(shù)據(jù)庫在大型語言模型(LLM)的宣傳開始之前就已經(jīng)存在了。最初,它們被應(yīng)用于推薦系統(tǒng)中,因?yàn)樗鼈兛梢钥焖僬业浇o定查詢的相似對象。但是,由于它們可以為大型語言模型提供長期記憶,因此最近也被應(yīng)用于問答應(yīng)用程序中。
4、向工程師和數(shù)據(jù)專業(yè)人員解釋向量數(shù)據(jù)庫
如果在打開本文之前,你已經(jīng)猜到向量數(shù)據(jù)庫可能是存儲向量嵌入的一種方式,并且只想知道向量嵌入的背后是什么,那么,現(xiàn)在讓我們來深入了解并討論一下相關(guān)的算法。
1)向量數(shù)據(jù)庫是如何工作的?
向量數(shù)據(jù)庫能夠快速檢索查詢中的類似對象,因?yàn)樗鼈円呀?jīng)預(yù)先計(jì)算過了。其基本概念被稱為近似最近鄰(Approximate Nearest Neighbor:ANN)搜索,它使用不同的算法來索引和計(jì)算相似性。
正如你所能想象的,當(dāng)你有數(shù)百萬個(gè)嵌入時(shí),用簡單的k近鄰(kNN)算法計(jì)算查詢和每個(gè)嵌入對象之間的相似性可能會(huì)變得相當(dāng)耗時(shí)。而使用ANN搜索算法,你可以以一定的準(zhǔn)確性換取速度,并檢索與查詢近似最相似的對象。
索引:為此,向量數(shù)據(jù)庫對向量嵌入進(jìn)行索引。此步驟將向量映射到數(shù)據(jù)結(jié)構(gòu),從而實(shí)現(xiàn)更快的搜索。
你可以把索引看作是把圖書館里的書分成不同的類別,比如作者或流派。但由于嵌入可以包含更復(fù)雜的信息,進(jìn)一步的分類可能是“主角的性別”或“情節(jié)的主要位置”。因此,索引可以幫助您檢索所有可用向量的較小部分,從而加快檢索速度。
我們不會(huì)討論索引算法的技術(shù)細(xì)節(jié);但是,如果你有興趣進(jìn)一步閱讀,你可能想從查找分層導(dǎo)航小世界(Hierarchical Navigable Small World:HNSW)開始。
相似性度量:為了從索引向量中找到查詢的最近鄰居,向量數(shù)據(jù)庫應(yīng)用相似性度量。常見的相似性度量包括余弦相似性、點(diǎn)積、歐幾里得距離、曼哈頓距離和漢明距離(Hamming distance)。
2)向量數(shù)據(jù)庫相對于將向量嵌入存儲在NumPy數(shù)組中的優(yōu)勢是什么?
我經(jīng)常(已經(jīng))遇到的一個(gè)問題是:我們不能只使用NumPy數(shù)組來存儲嵌入嗎?——當(dāng)然,如果你沒有很多嵌入,或者你只是在做一個(gè)有趣的愛好項(xiàng)目,你可以這樣做。但正如你已經(jīng)猜到的,當(dāng)你有很多嵌入時(shí),向量數(shù)據(jù)庫會(huì)明顯更快,而且你不必把所有東西都保存在內(nèi)存中。
最后,我僅會(huì)簡短地說一句,因?yàn)橐辽?middot;羅森塔爾在解釋使用向量數(shù)據(jù)庫和使用NumPy數(shù)組之間的區(qū)別方面做得比我寫的要好得多。有關(guān)此內(nèi)容的更多信息,請參考他的文章《你真的需要向量數(shù)據(jù)庫嗎?》,網(wǎng)址是:www.ethanrosenthal.com。
——譯者介紹——
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計(jì)算機(jī)教師,自由編程界老兵一枚。
原文鏈接:https://towardsdatascience.com/explAIning-vector-databases-in-3-levels-of-difficulty-fc392e48ab78





