
你聽過爬蟲嗎?
計算中的爬蟲,又稱為網絡爬蟲、網頁蜘蛛、網絡機器人,它是一段計算機器代碼,可以自動抓取網頁上的數據。
網頁是由什么組成呢?
網頁一般由文本、圖像、音頻、視頻等元素組成。
它們通過html、JS、css等編程語法排列組合,然后生成網頁。也就是說,我們看到的文字、圖片、視頻等是和HTML等元素混合在一起的。
爬蟲所做的工作就是從網頁中把我們關心的文本、圖像、音頻、視頻等提取出來,我們不關心HTML等元素,但我們需要按照HTML等的語法來解析網頁。
爬蟲的基本結構
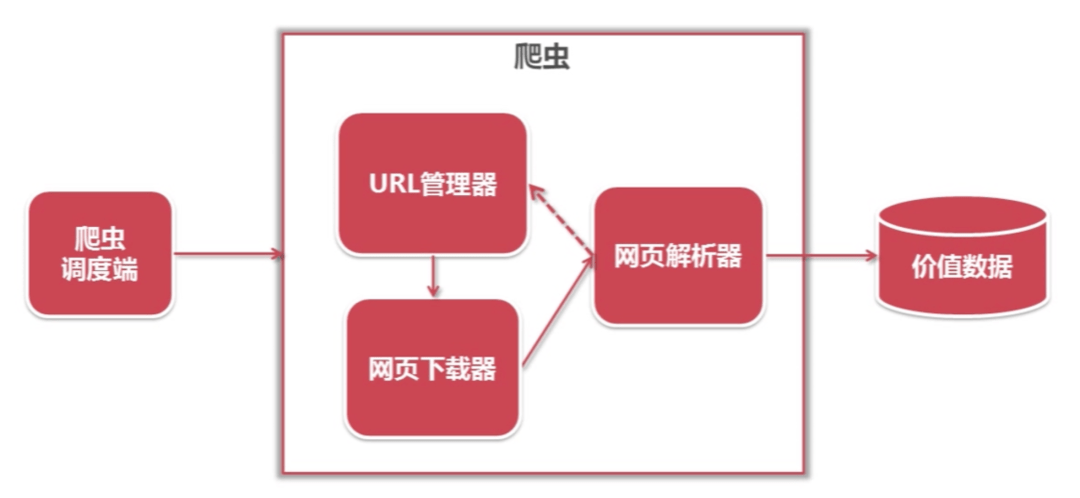
一個簡單的爬蟲由四部分組成:URL管理器、網頁下載器、網頁解析器、數據存儲器等。
- URL管理器就是你要下載哪個網頁的內容,URL中有超鏈接,這些鏈接是否需要下載,下載時需要去重等。
- 網頁下載器就是下載網頁的內容,將網頁的內容下載到本地。常用的兩個http請求庫有urllib庫和request庫。前者是Python/ target=_blank class=infotextkey>Python官方基本模塊。后者是性能優越使用廣泛的第三方庫。
- 網頁解析器就是解析網頁內容,提取我們關心的信息。用到的知識有正則表達式、lxml庫和Beautiful Soup庫。
- 數據存儲庫主要就是存儲數據,將數據持久化存儲到本地。
為什么Python在爬蟲領域獨領風騷?
因為有很多成熟好用的相關庫,拿來就用,節省了造輪子的時間。
爬蟲的工作流程
爬蟲的工作流程主要有四步:
- Request發起請求,客戶端請求服務器響應。
- Reponse獲取響應,此時服務器將所請求的網頁送到客戶端。
- 解析內容,利用正則表達式、lxml庫或Beautiful Soup庫提取目標信息。
- 保存數據,將解析后的數據保存到本地,可以是文本、音頻、圖片、視頻等。
如何限制爬蟲
目前對網絡爬蟲的限制主要有兩種方式:
1.來源審查:判斷User-Agent(在請求頭中的一個鍵值對)進行限制,通過該鍵值對可以判斷發起網絡請求的瀏覽器類型,網站維護人員可以根據這個進行請求限制。
2.發布公告:Robots協議。
Robots協議是一種網站管理員用來告知搜索引擎蜘蛛哪些頁面可以抓取,哪些頁面不可以抓取的文本文件。
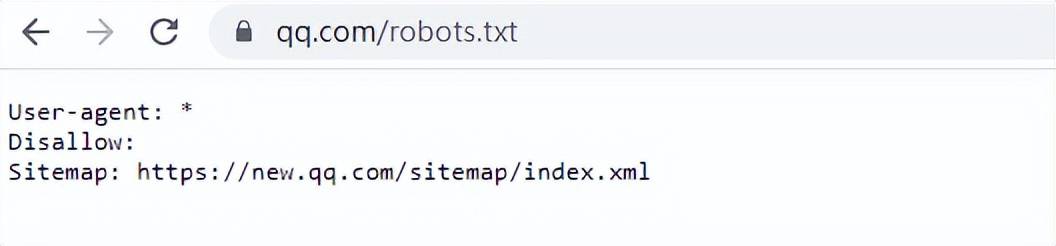
robots.txt是一種存放于網站根目錄下的ASCII編碼的文本文件,它通常告訴網絡搜索引擎的漫游器(又稱網絡爬蟲/蜘蛛),此網站中的哪些內容是不能被搜索引擎的漫游器獲取的,哪些是可以被獲取的。當robots訪問一個網站時,它會首先查看該網站根目錄下是否存在robots.txt文件,如果存在,它將按照文件中規定的規則進行訪問 。
可以查看一些網站的robots.txt文件,比如:


遵紀守法
robots.txt是道德規范,是一個協議,它不是命令,不是強制執行,大家一定要自覺遵守。
爬蟲技術是一種自動化獲取網絡信息的技術,但是如果不遵守相關法律法規,就會觸犯法律。

為了避免這種情況,我們可以采取以下措施:
1.在爬蟲程序中設置訪問限制,避免對目標網站造成過大的訪問壓力;
2.在爬蟲程序中設置合理的請求間隔,避免對目標網站造成過大的訪問量;
3.在爬蟲程序中設置合理的抓取深度,避免對目標網站造成過大的數據抓取量;
4.在爬蟲程序中設置合理的數據存儲方式,避免對目標網站造成過大的數據存儲壓力;
5.在使用爬蟲技術時,應該尊重目標網站的隱私權和知識產權,不得侵犯其合法權益 。





